
快速排序的基本思想是通过一趟快速排序,将要排序的数据分割成独立的两部分,其中一部分的所有数据比另外一部分的所有数据都要小,然后再按此方法递归地对这两部分数据分别进行快速排序。如此一直进行下去,直到排序完成。
快速排序实际上是冒泡排序的一种改进,是冒泡排序的升级版。这种改进就体现在根据分割序列的基准数,跨越式地进行交换。正是由于这种跨越式,使得元素每次移动的间距变大了,而不像冒泡排序那样一格一格地“爬”。快速排序是一次跨多格,所以总的移动次数就比冒泡排序少很多。
但是快速排序也有一个问题,就是递归深度的问题。调用函数要消耗资源,递归需要系统堆栈,所以递归的空间消耗要比非递归的空间消耗大很多。而且如果递归太深的话会导致堆栈溢出,系统会“撑”不住。快速排序递归的深度取决于基准数的选择,比如下面这个序列:
5 1 9 3 7 4 8 6 2
5 正好处于 1~9 的中间,选择 5 作基准数可以平衡两边的递归深度。可如果是:
1 5 9 3 7 4 8 6 2
选择 1 作为基准数,那么递归深度就全部都加到右边了。如果右边有几万个数的话则系统直接就崩溃了。所以需要对递归深度进行优化。怎么优化呢?就是任意取三个数,一般是取序列的第一个数、中间数和最后一个数,然后选择这三个数中大小排在中间的那个数作为基准数,这样起码能确保获取的基准数不是两个极端。
前面讲过,快速排序一般用于大数据排序,即数据的个数很多的时候(不是指数的值很大)。如果是小规模的排序,就用前面讲的几种简单排序方式就行了,不必使用快速排序。
四种排序算法的比较
冒泡排序是最慢的排序算法。在实际运用中它是效率最低的算法。它通过一趟又一趟地比较数组中的每一个元素,使较大的数据下沉,较小的数据上升。
插入排序通过将序列中的值插入一个已经排好序的序列中,直到该序列结束。插入排序是对冒泡排序的改进。它比冒泡排序快两倍。一般不用在数据的值大于 1000 的场合,或数据的个数超过 200 的序列。
选择排序在实际应用中处于与冒泡排序基本相同的地位。它们只是排序算法发展的初级阶段,在实际中使用较少。但是它们最好理解。
快速排序是大规模递归的算法,它比大部分排序算法都要快。一般用于数据个数比较多的情况。尽管可以在某些特殊的情况下写出比快速排序快的算法,但是就通常情况而言,没有比它更快的了。快速排序是递归的,对于内存非常有限的机器来说,它不是一个好的选择。
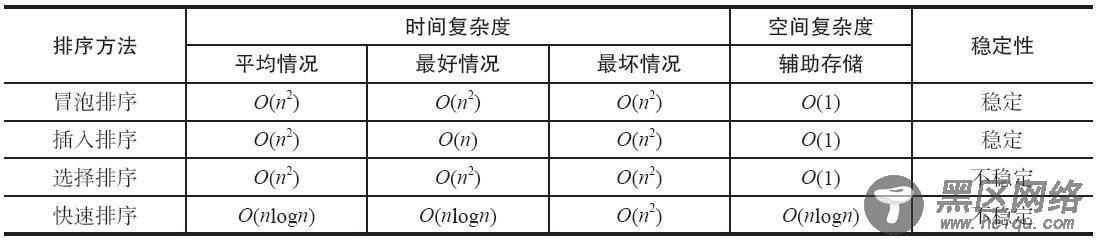
稳定性:假定在待排序的序列中存在多个相同的值,若经过排序后,这些值的相对次序保持不变,即在原序列中 ri=rj,且 ri 在 rj 之前,而在排序后的序列中 ri 仍在 rj 之前,则称这种排序算法是稳定的,否则称为不稳定的。
Linux公社的RSS地址:https://www.linuxidc.com/rssFeed.aspx