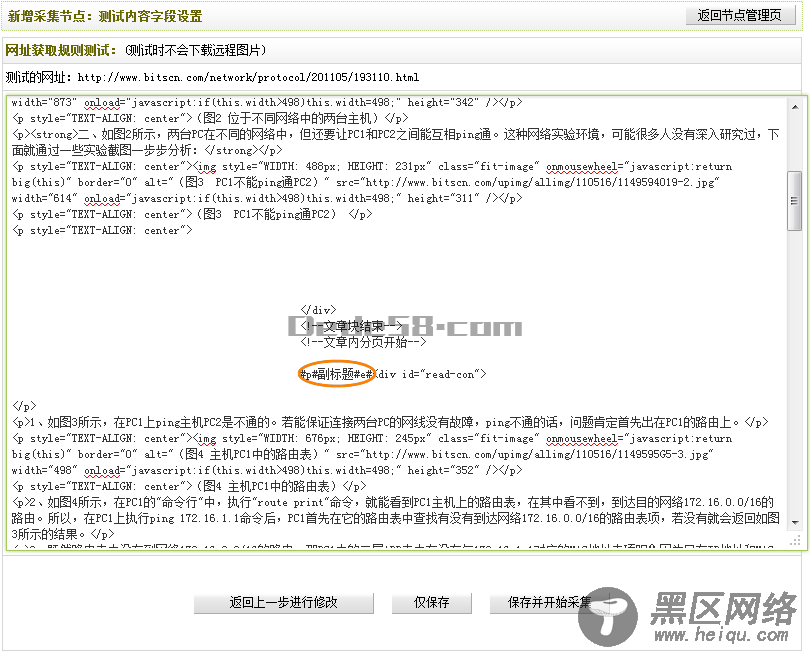
这里应选取“<!—文章内分页结束-->”作为文章内容的结束部分,由于在选取的内容中又包含了一段JS代码,因此应再次使用过滤规则,把其去除。同时,考虑到本页没有涉及到分页,所以在分页代码中的<ul></ul>之间是空的。但是,如果页面包含分页的话,也是应该使用过滤规则去除的。此外,如果所设定的文章内容中,含有图片、链接等不希望被采集到的内容,也应该使用过滤规则一并去除掉。填写完成后,如(图25)所示,
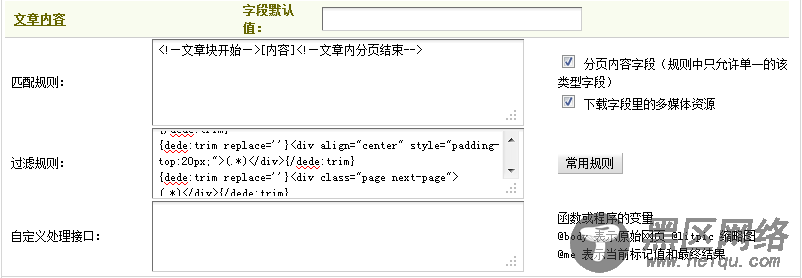
图25-文章内容的匹配规则
到这里,“新增采集节点:第二步设置内容字段获取规则”,就设置完成了。来看一下整个配置页面,如(图26)所示,

图26-设置后的新增采集节点:第二步设置内容字段获取规则
检查无误后,单击“保存配置并预览”。如果之前设置正确,单击后,将会进入“新增采集节点:测试内容字段设置”页面并看到相应的文章内容。如(图27)和(图28)所示,
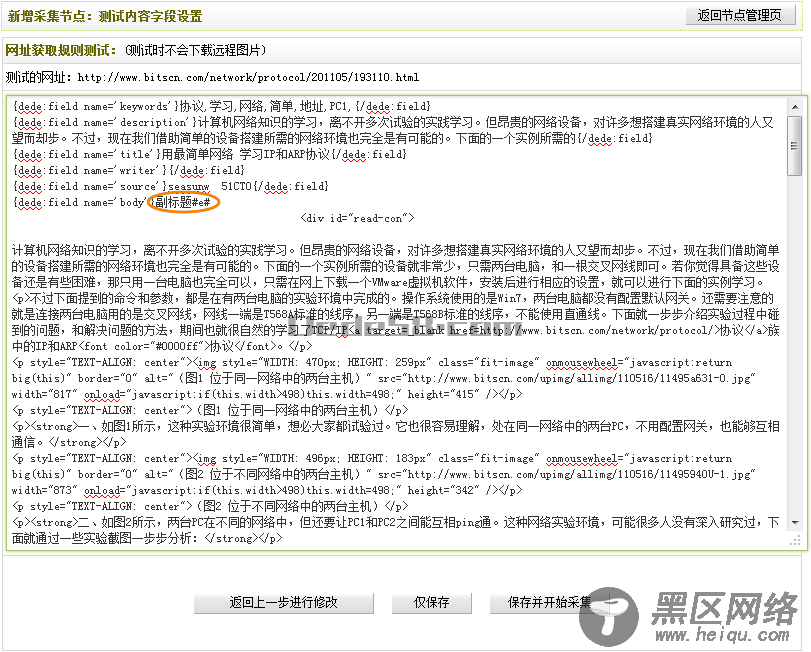
图27-新增采集节点:测试内容字段设置