
https://www.facebook.com/Hadoopers
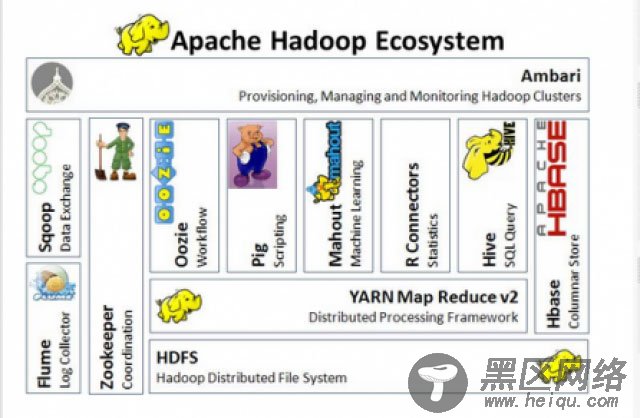
在一些 Teiid 的一些文章和示例上都会有关于 JBoss Data Virtualization (Teiid) 通过 Hive 使用 Hadoop 作为数据源的信息。当使用 Hadoop 环境创建 Data Virtualization 示例时,比如 Hortonworks Data Platform, Cloudera Quickstart 等等,里面会包含大量的开源项目。本篇文章主要是对 Hadoop 生态系统有个初步的认识,以下的一些开源项目详情可以查看 hadoop ecosystem table。
Map Reduce -MapReduce 是使用集群的并行,分布式算法处理大数据集的可编程模型。Apache MapReduce 是从 Google MapReduce 派生而来的:在大型集群中简化数据处理。当前的 Apache MapReduce 版本基于 Apache YARN 框架构建。YARN = “Yet-Another-Resource-Negotiator”。YARN 可以运行非 MapReduce 模型的应用。YARN 是 Apache Hadoop 想要超越 MapReduce 数据处理能力的一种尝试。
HDFS - The Hadoop Distributed File System (HDFS) 提供跨多个机器存储大型文件的一种解决方案。Hadoop 和 HDFS 都是从 Google File System (GFS) 中派生的。Hadoop 2.0.0 之前,NameNode 是 HDFS 集群的一个单点故障 (SPOF) 。利用 Zookeeper,HDFS 高可用性特性解决了这个问题,提供选项来运行两个重复的 NameNodes,在同一个集群中,同一个 Active/Passive 配置。
HBase - 灵感来源于 Google BigTable。HBase 是 Google Bigtable 的开源实现,类似 Google Bigtable 利用 GFS 作为其文件存储系统,HBase 利用 Hadoop HDFS 作为其文件存储系统;Google 运行 MapReduce 来处理 Bigtable 中的海量数据,HBase 同样利用 Hadoop MapReduce 来处理 HBase 中的海量数据;Google Bigtable 利用 Chubby 作为协同服务,HBase 利用 Zookeeper 作为对应。
HBase 结点之间时间不一致造成regionserver启动失败
HBase 的详细介绍:请点这里
HBase 的下载地址:请点这里
Hive - Facebook 开发的数据仓库基础设施。数据汇总,查询和分析。Hive 提供类似 SQL 的语言 (不兼容 SQL92):HiveQL。
Pig - Pig 提供一个引擎在 Hadoop 并行执行数据流。Pig 包含一个语言:Pig Latin,用来表达这些数据流。Pig Latin 包括大量的传统数据操作 (join, sort, filter, etc.), 也可以让用户开发他们自己的函数,用来查看,处理和编写数据。Pig 在 hadoop 上运行,在 Hadoop 分布式文件系统,HDFS 和 Hadoop 处理系统,MapReduce 中都有使用。Pig 使用 MapReduce 来执行所有的数据处理,编译 Pig Latin 脚本,用户可以编写到一个系列,一个或者多个的 MapReduce 作业,然后执行。Pig Latin 看起来跟大多数编程语言都不一样,没有 if 状态和 for 循环。