我们尝试获取表的信息,这里,我们就用某校的课表来代替:
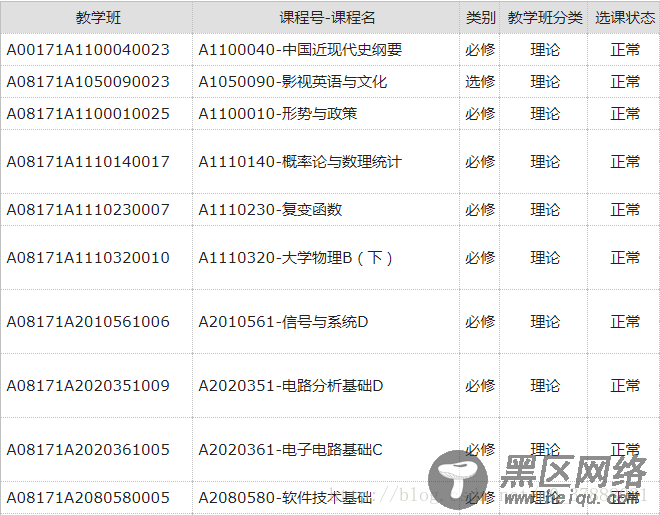
接下来我们就上代码:
a.php
<?php header( "Content-type:text/html;Charset=utf-8" ); $ch = curl_init(); $url ="表的链接"; curl_setopt ( $ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.113 Safari/537.36" ); curl_setopt($ch,CURLOPT_URL,$url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $content=curl_exec($ch); preg_match_all("/<td rowspan=\"\d\">(.*?)<\/td>\n<td rowspan=\"\d\">(.*?)<\/td><td rowspan=\"\d\" align=\"\w+\">(.*?)<\/td><td rowspan=\"\d\" align=\"\w+\">(.*?)<\/td><td>(.*?)<\/td>\n<td>(.*?)<\/td><td>(.*?)<\/td>/",$content,$matchs,PREG_SET_ORDER); //匹配该表所用的正则 var_dump($matchs);
然后咱们就运行一下:

成功获取到课表;
图片获取绝对链接
我们以百度图库的首页为例
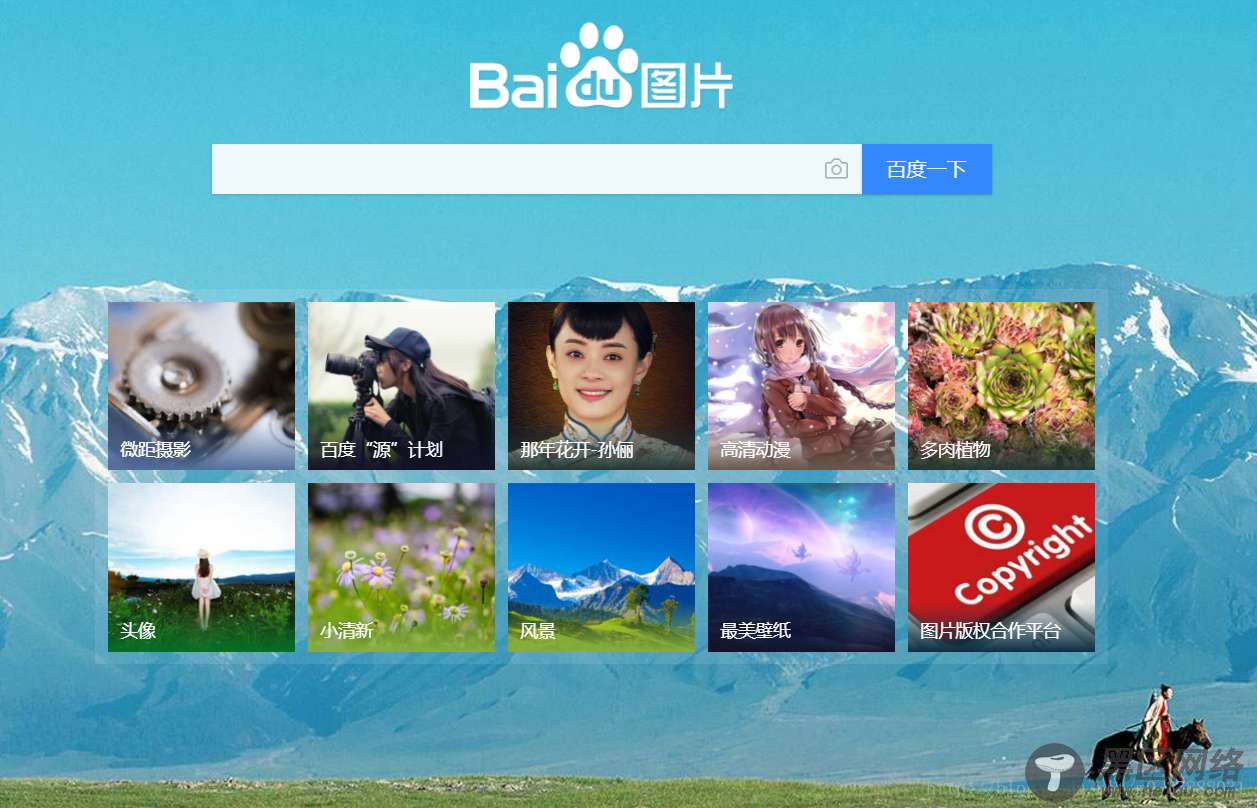
b.php
<?php header( "Content-type:text/html;Charset=utf-8" ); $ch = curl_init(); $url="http://image.baidu.com/"; curl_setopt ($ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.113 Safari/537.36" ); curl_setopt($ch,CURLOPT_URL,$url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $content=curl_exec($ch); $string=file_get_contents($url); preg_match_all("/<img([^>]*)\s*src=('|\")([^'\"]+)('|\")/", $string,$matches); $new_arr=array_unique($matches[3]); foreach($new_arr as $key) { echo "<img src=https://www.jb51.net/$key>"; }
然后,我们就获得了下面的页面:

相对链接
百度图库的图片的链接大部分是绝对链接,那么当我们遇到网页图片为相对链接的时候,我们该怎么处理呢?其实很简单,我们只需要将循环那部分改为
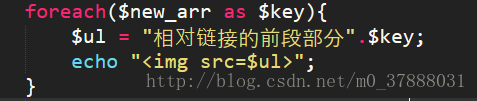
那么我们就可以同样在浏览器中输出图片了;
到此这篇关于PHP实现爬虫爬取图片代码实例的文章就介绍到这了,更多相关PHP实现爬虫内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章: