
3.4,Hadoop管理
3.4.1 格式化完成后,开始启动hadoop 程序启动hadoop 的命令脚本都在$HADOOP_HOME/sbin/下,下面的所有命令都不再带有完整路径名称:
distribute-exclude.sh hdfs-config.sh slaves.sh start-dfs.cmd start-yarn.sh stop-dfs.cmd stop-yarn.sh
hadoop-daemon.sh httpfs.sh start-all.cmd start-dfs.sh stop-all.cmd stop-dfs.sh yarn-daemon.sh
hadoop-daemons.sh mr-jobhistory-daemon.sh start-all.sh start-secure-dns.sh stop-all.sh stop-secure-dns.sh yarn-daemons.sh
hdfs-config.cmd refresh-namenodes.sh start-balancer.sh start-yarn.cmd stop-balancer.sh stop-yarn.cmd
讲述hadoop 启动的三种方式:
3.4.2,第一种,一次性全部启动:
执行start-all.sh 启动hadoop,观察控制台的输出,可以看到正在启动进程,分别是namenode、datanode、secondarynamenode、jobtracker、tasktracker,一共5 个,待执行完毕后,并不意味着这5 个进程成功启动,上面仅仅表示系统正在启动进程而已。我们使用jdk 的命令jps 查看进程是否已经正确启动。执行以下jps,如果看到了这5 个进程,说明hadoop 真的启动成功了。如果缺少一个或者多个,那就进入到“Hadoop的常见启动错误”章节寻找原因了。
停止应用:
/home/hadoop/src/hadoop-2.3.0/sbin/stop-all.sh
启动应用:
/home/hadoop/src/hadoop-2.3.0/sbin/start-all.sh
[hadoop@name01 hadoop]$ /home/hadoop/src/hadoop-2.3.0/sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [name01]
name01: starting namenode, logging to /home/hadoop/src/hadoop-2.3.0/logs/hadoop-hadoop-namenode-name01.out
data01: starting datanode, logging to /home/hadoop/src/hadoop-2.3.0/logs/hadoop-hadoop-datanode-name01.out
data02: starting datanode, logging to /home/hadoop/src/hadoop-2.3.0/logs/hadoop-hadoop-datanode-name01.out
Starting secondary namenodes [name01]
name01: starting secondarynamenode, logging to /home/hadoop/src/hadoop-2.3.0/logs/hadoop-hadoop-secondarynamenode-name01.out
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/src/hadoop-2.3.0/logs/yarn-hadoop-resourcemanager-name01.out
data02: starting nodemanager, logging to /home/hadoop/src/hadoop-2.3.0/logs/yarn-hadoop-nodemanager-name01.out
data01: starting nodemanager, logging to /home/hadoop/src/hadoop-2.3.0/logs/yarn-hadoop-nodemanager-name01.out
[hadoop@name01 bin]$
3.4.2.1,检查后台各个节点运行的hadoop进程
[hadoop@name01 hadoop]$ jps
8862 Jps
8601 ResourceManager
8458 SecondaryNameNode
8285 NameNode
[hadoop@name01 hadoop]$
[hadoop@name01 ~]$ jps
-bash: jps: command not found
[hadoop@name01 ~]$
[hadoop@name01 ~]$ /usr/lib/jvm/jdk1.7.0_60/bin/jps
5812 NodeManager
6047 Jps
5750 DataNode
[hadoop@name01 ~]$
[root@data01 ~]# jps
5812 NodeManager
6121 Jps
5750 DataNode
[root@data01 ~]
3.4.2.2,为什么在root下能单独用jps命令,su到hadoop不行,search了下,原因是我加载jdk路径的时候用的是
vim ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_60
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存退出,然后输入下面的命令来使之生效
source ~/.bashrc
方式,这种只对当前用户生效,我的jdk是用root安装的,所以su到hadoop就无法生效了,怎么办?用/etc/profile,在文件最末端添加jdk路径
[root@data01 ~]# vim /etc/profile
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_60
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#保存退出,然后输入下面的命令来使之生效:
[root@data01 ~]# source /etc/profile
su - hadoop
[hadoop@data01 ~]$ jps
6891 DataNode
7025 NodeManager
8354 Jps
[hadoop@data01 ~]$
OK,在hadoop账号下,jps也生效
3.4.2.3,再去data02节点下检查
[hadoop@data02 ~]$ jps
11528 Jps
10609 NodeManager
10540 DataNode
[hadoop@data02 ~]$
查看到2个data节点的进程都启动起来了,恭喜····
3.4.2.4,通过网站查看hadoop集群情况
在浏览器中输入::50030/dfshealth.html,网址为name01结点(也就是master主库节点)所对应的IP:
结果显示一片空白:
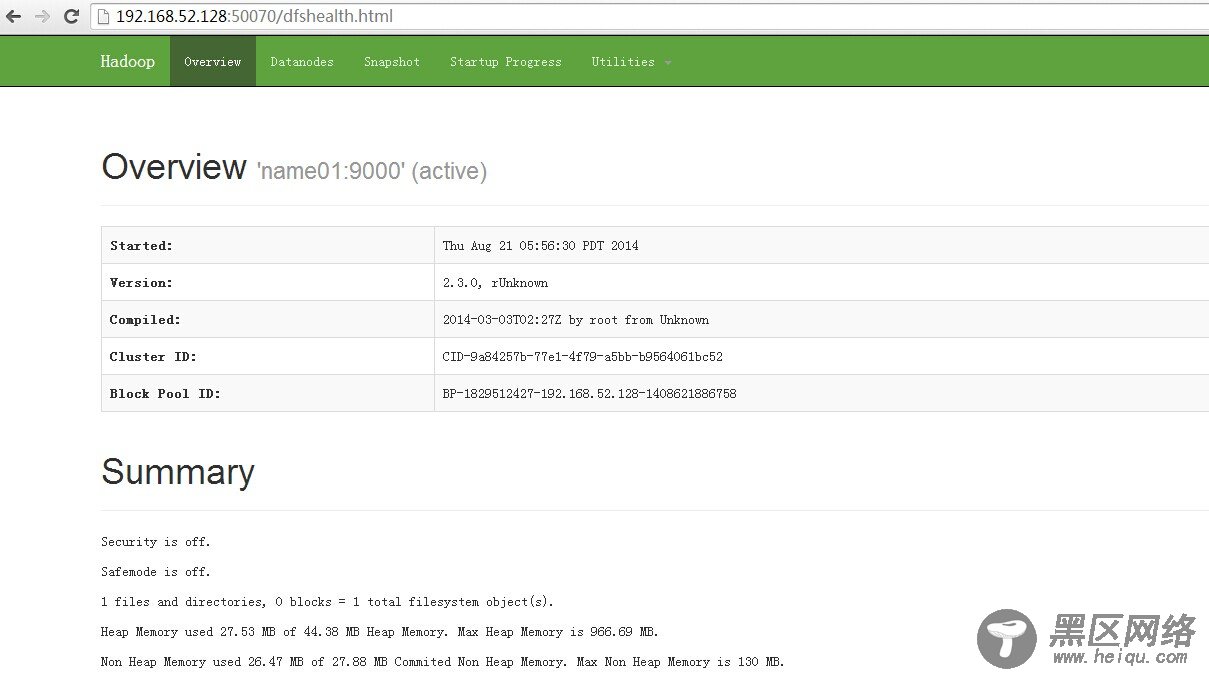
在浏览器中输入::50070,网址为name01结点(也就是master主库节点)所对应的IP:
进入:50070/dfshealth.html#tab-overview,看集群基本信息,如下图所示:
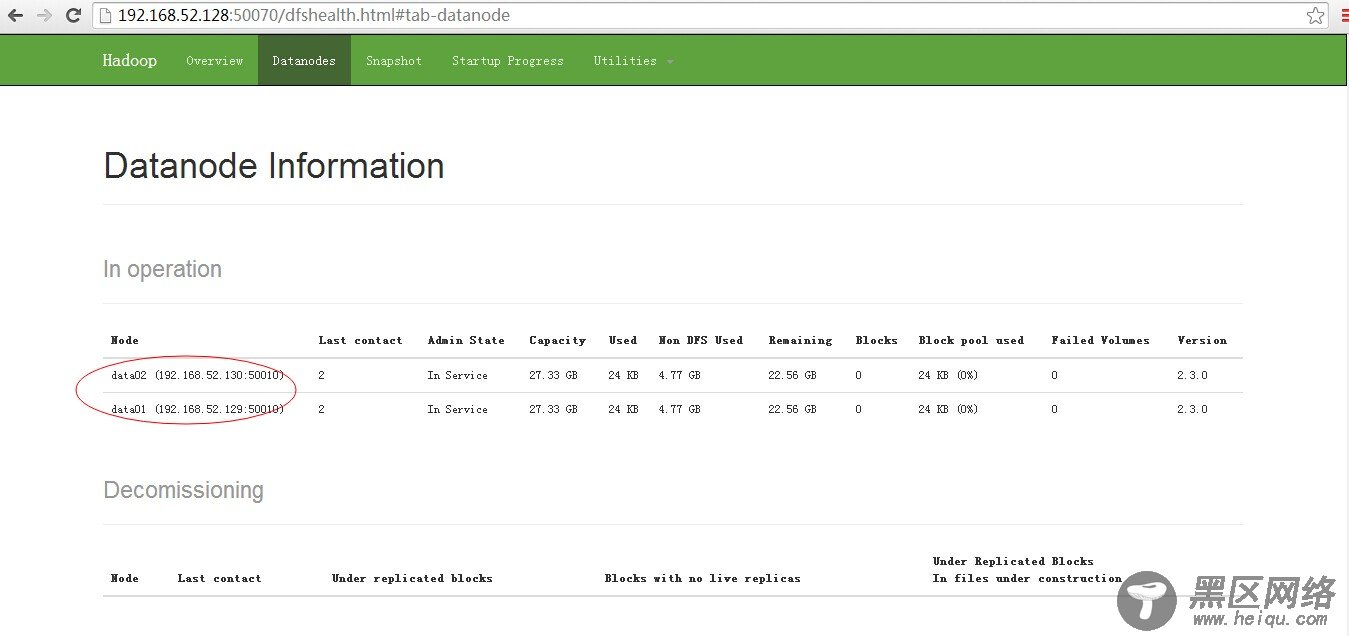
进入:50070/dfshealth.html#tab-datanode,看datanode信息,如下图所示:
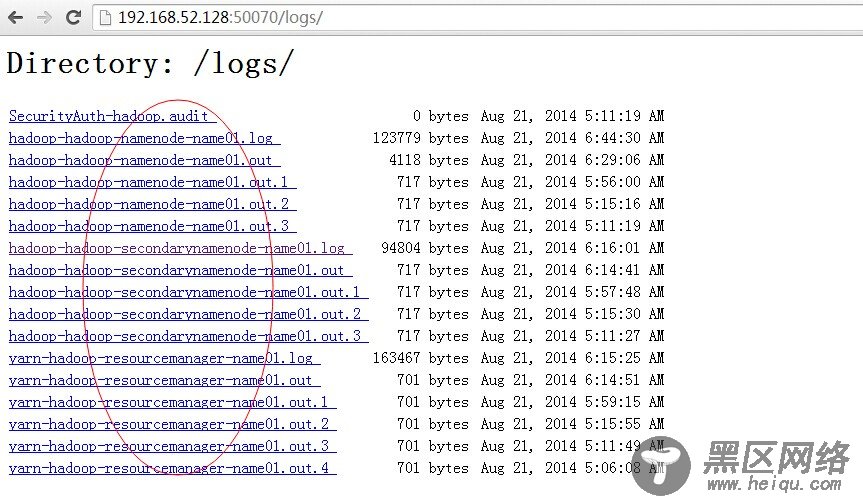
进入:50070/logs/,查看所有日志信息,如下图所示:
至此,hadoop的完全分布式集群安装已经全部完成,可以好好睡个觉了。~~