用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
而在Node中, 采用的是I/O 多路复用的模式, 而在I/O多路复用的模式中, 又具有read, select, poll, epoll等几个子模式, Node采用的是最优的epoll模式, 这里简单说下其中的区别, 并且解释下为什么epoll是最优的。
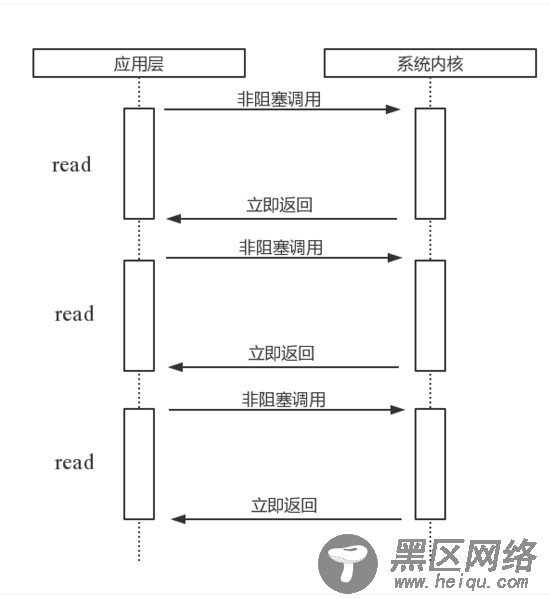
read
read。它是一种最原始、性能最低的一种,它会重复检查I/O的状态来完成数据的完整读取。在得到最终数据前,CPU一直耗用在I/O状态的重复检查上。图1是通过read进行轮询的示意图。
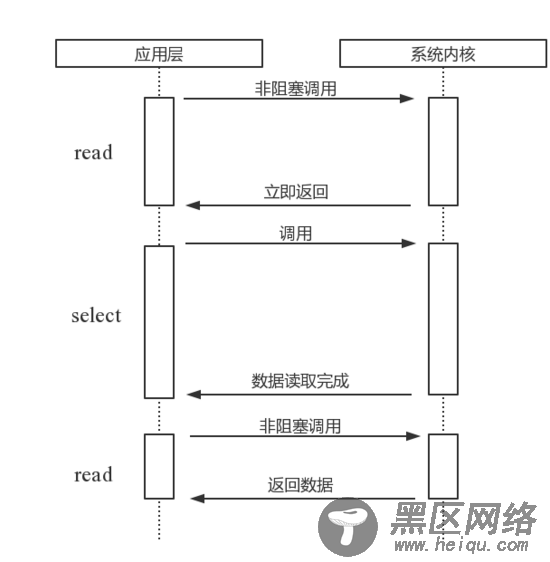
select
select。它是在read的基础上改进的一种方案,通过对文件描述符上的事件状态进行判断。图2是通过select进行轮询的示意图。select轮询具有一个较弱的限制,那就是由于它采用一个1024长度的数组来存储状态,也就是说它最多可以同时检查1024个文件描述符。
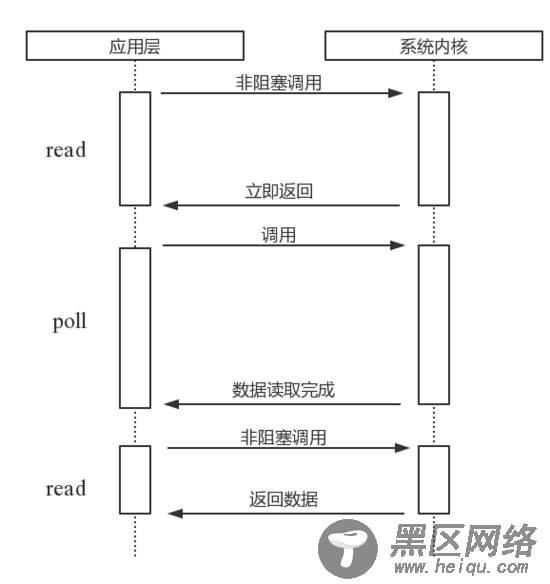
poll
poll。poll比select有所改进,采用链表的方式避免数组长度的限制,其次它可以避免不必要的检查。但是文件描述符较多的时候,它的性能是十分低下的。
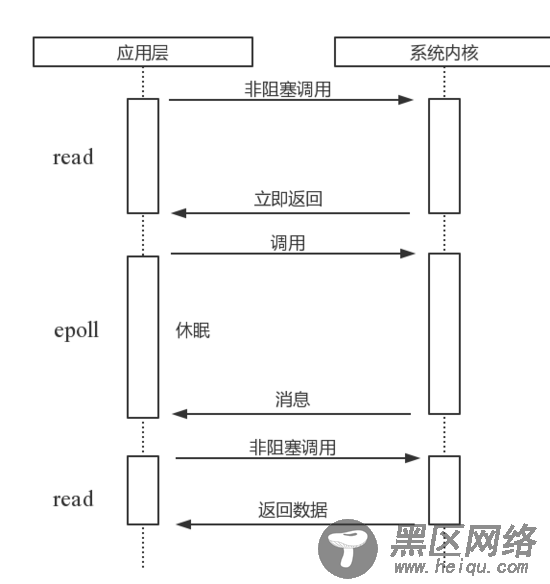
epoll
该方案是Linux下效率最高的I/O事件通知机制,在进入轮询的时候如果没有检查到I/O事件,将会进行休眠,直到事件发生将它唤醒。它是真实利用了事件通知,执行回调的方式,而不是遍历查询,所以不会浪费CPU,执行效率较高。
除此之外, 另外的poll和select还具有以下的缺点(引用自 文章 ):
每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
select支持的文件描述符数量太小了,默认是1024
epoll对于上述的改进
epoll既然是对select和poll的改进,就应该能避免上述的三个缺点。那epoll都是怎么解决的呢?在此之前,我们先看一下epoll和select和poll的调用接口上的不同,select和poll都只提供了一个函数——select或者poll函数。而epoll提供了三个函数,epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄;epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。
对于第一个缺点,epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。
对于第二个缺点,epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,而只在epoll_ctl时把current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调函数,而这个回调函数会把就绪的fd加入一个就绪链表)。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd(利用schedule_timeout()实现睡一会,判断一会的效果,和select实现中的第7步是类似的)。
对于第三个缺点,epoll没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,一般来说这个数目和系统内存关系很大。
Node中的异步网络Io就是利用了epoll来实现, 简单来说, 就是利用一个线程来管理众多的IO请求, 通过事件机制实现消息通讯。
事件循环
理解了Node中磁盘IO和网络IO的底层实现后, 基于上面的代码, 可以看出Node是基于事件注册的方式在完成Io后进行一系列的处理, 其内部是利用了事件循环的机制。
关于事件循环, 是指JS在每次执行完同步任务后会检查执行栈是否为空, 是的话就会去执行注册的事件列表, 不断的循环该过程。Node中的事件循环有六个阶段:
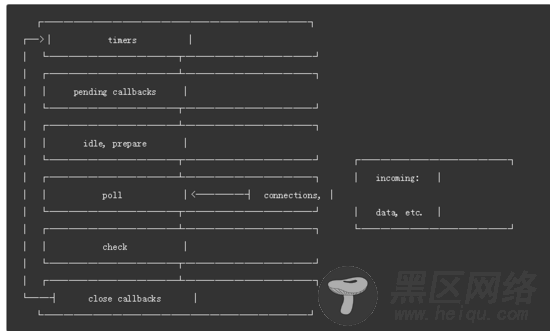
其中的每个阶段都会处理相关的事件:
timers: 执行setTimeout和setInterval中到期的callback。
pending callback: 执行延迟到下一个循环迭代的 I/O 回调。
idle, prepare:仅系统内部使用。