
以上两种方式都是将一个虚拟的块设备分片存储在RADOS(Ceph Cluster)中,都会利用利用数据条带化提高数据并行传输,都支持块设备的快照,COW(Copy-On-Write)克隆。最重要的是RBD还支持Live migration。目前的OpenStack,CloudStack都采用第一种方式为虚拟机提供块设备。
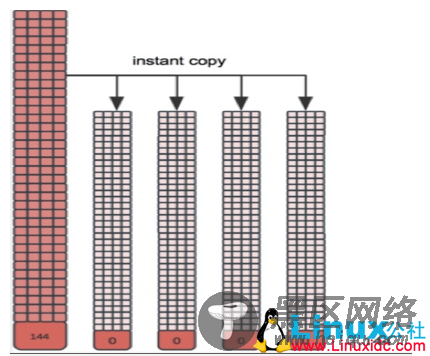
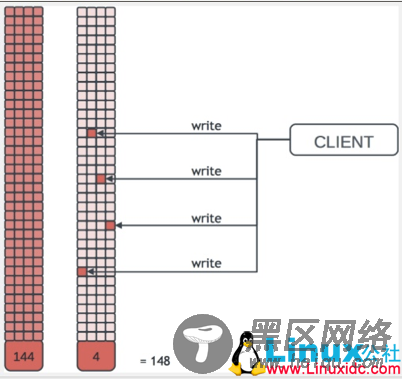
图十三
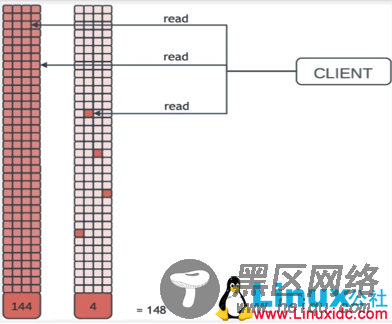
图十四
上述图示也表明了在大量VM的情况下如何使得存储容量利用的最小化和高效性。当大量VM基于同一个Snapshot建立Volume时,所有容量不会立即得到占用,而都是COW。这个特征也是目前众多存储厂商在VDI解决方案一直强调的。在VDI解决方案中,存储成本是最重要的一环,利用Ceph通过Thin provisioning和数据并行化可以大大提高VDI方案的吸引力。
目前Ceph的块存储是大力推荐并且高速开发的模块,因为它提供的接口对于用户更加熟悉,并且在目前流行的OpenStack和CloudStack中可以得到广泛接受和支持。Ceph块存储的计算和存储解耦、Live migration特性、高效的快照和克隆/恢复都是引入注目的特性。
CephFS
CephFS是基于Rados实现的PB级分布式文件系统,这里会引入一个新的组件MDS(Meta Data Server),它主要为兼容POSIX文件系统提供元数据,如目录和文件元数据。同时,MDS会将元数据也存在RADOS(Ceph Cluster)中。元数据存储在RADOS中后,元数据本身也达到了并行化,大大加强了文件操作的速度。需要注意的是MDS并不会直接为Client提供文件数据,而只是为Client提供元数据的操作。
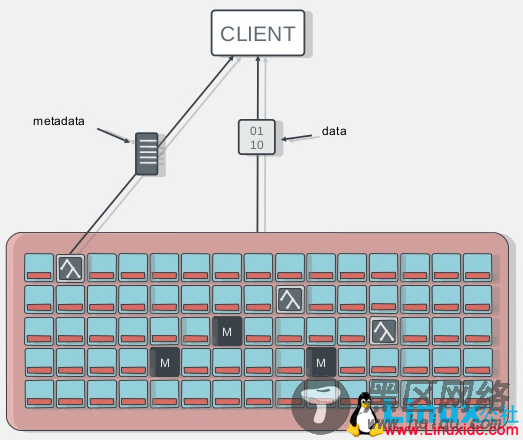
图十五
从上图可以看到,Client当Open一个文件时,会查询并更新MDS相应的元数据如文件包括的对象信息,然后再根据提供的对象信息直接从RADOS(Ceph Cluster)中直接得到文件数据。
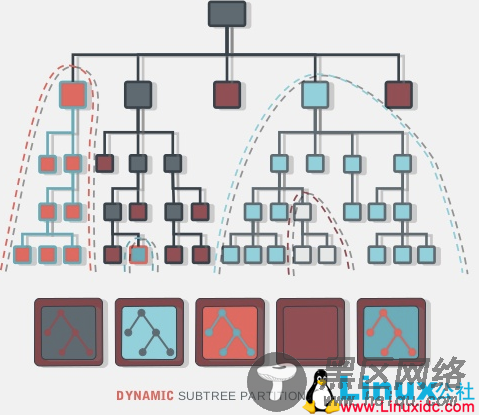
图十六
CephFS既然是分布式文件系统,当面对不同的文件热点和大小时,它需要提供数据负载均衡来避免MDS的热点。通过上图我们可以看到五个MDS管理着不同“面积”的目录树,因为不同文件的访问热点和大小的原因来进行动态调整。
这里还需要介绍引入MDS带来的好处有目录列表操作的加快,如目录下文件大小、数量和时间等。同时,支持对文件的快照。
目前CephFS有多种使用方式: 1. Linux Kernel client: 使用”mount -t ceph 8.8.8.8:/ /mnt”可以直接挂载到本地并访问。 2. ceph-fuse: 通过ceph-fuse可以从用户态空间挂载CephFS如”ceph-fuse -m 192.168.0.1:6789 /home/username/cephfs” 3. libcephfs.so: 通过libcephfs可以替代HDFS来支持不同Hadoop乃至HBase。
Ceph的其他
QoS机制: Ceph Cluster支持多种QoS配置,如集群重平衡,数据恢复的优先级配置,避免影响正常的数据通信。
Geo-replication: 基于地理位置的对象存储
OpenStack: Ceph目前在大力融合入OpenStack,OpenStack的所有存储(除数据库外)都可以将Ceph作为存储后端。如KeyStone和Swfit可以利用RadosGW,Cinder、Glance和Nova利用RBD作为块存储。甚至所有VM的Image都存储在CephFS上。
目前Ceph的优化点也非常多,目前Rados IO路径过于复杂,线程管理得不到有限控制,如果在Rados上优化Small IO的性能,Ceph Cluster的集群性能会得到极大提高。很多人也会担心Ceph实现了如此多样的存储接口会不会一定降低每一个接口的性能要求。但从架构上来说,Ceph的RADOS只是一个单纯的分布式存储机制,其上的接口看到的都是一层统一的存储池,接口实现互相分离而不影响。