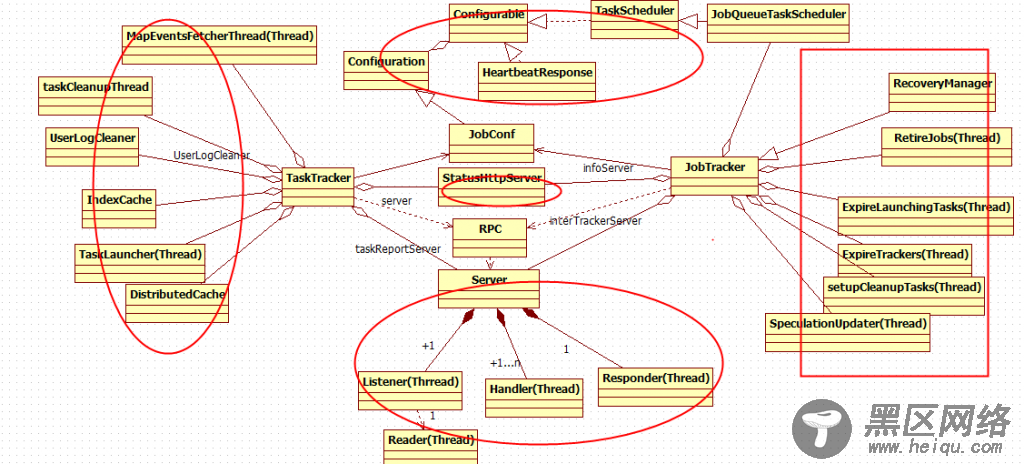
Hadoop中mr类图大致如下所示,其中只是简单列出了一些主要的功能模块。
JobConf、JobTracker、TaskTracker、RPC Server等组件。在图中,我用红色框框框出了一些基本的类。此图基本反映了MR的类图结构。
一个简单的job在hadoop上面跑起来,基本可以分为10个步骤。如下图所示:
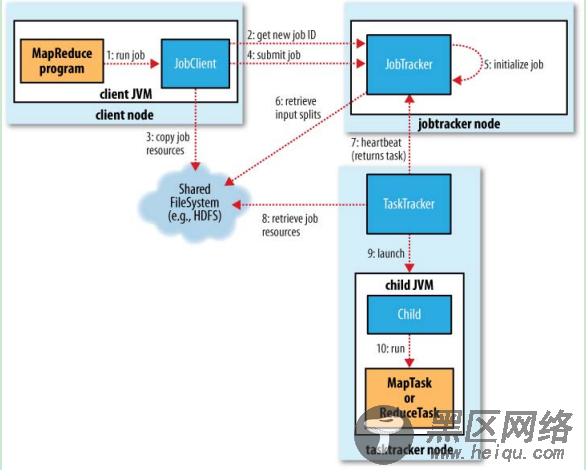
其中第7条线heartbeat应该是比较复杂且具有代表性的。接下来,我主要分析下,mr心跳的具体流程。(包括RPC)
二、分析heartbeat及RPC
hadoop是master-slave结构,所以需要slave报告自身的情况。为了得到一个HeartbeatResponse,大致需要经过以下的流程。

上图是一个序列图,是代码实现的调用序列,我们简化为流程图如下:

我们大致认为一次心跳(包括RPC)需要经过7个步骤。在这个7个步骤中,有大约6个主要的线程在服务。
TaskTracker端的:TaskTreacker,Client.Connection
JobTracker端的:Server.Listener,Server.Reader,Server.Handler,Server.Responder
7个步骤为:
1)、TaskTracker定期发送请求。TaskTracker持有一个代理对象InterTrackerProtocol.此对象经过动态代理处理,实际上是调用RPC.Invoker类。此类再调用 client.call()。此方法中,会实例化一个Client.Connection对象,并启动此对象。发送远程请求后,TaskTracker会阻塞在Call上面,等待Client.Connection线程被唤醒后调用call.notify()。
Call call = new Call(param);
Connection connection = getConnection(addr, ticket, call);
connection.sendParam(call); // send the parameter
synchronized (call) {
while (!call. done) {
try {
call.wait(); // wait for the result
} catch (InterruptedException ignored) {}
}
注意Client.Connection线程一直阻塞在DataInputStream.readInt()等待JobTracker的响应。
图:Client.Connection线程
2)、Server.Listener会监听到请求并建立连接,再调用Reader来做读取网络数据。与Server.Reader的协同主要是通过adding变量、Server.Reader.wait()、readSelector;完成后阻塞在selector.select();
while ( adding) {