
root@pve-1:~# ceph -w cluster: id: 0320d45c-fe5b-4e3d-b515-e223ed5b5686 health: HEALTH_OK services: mon: 3 daemons, quorum pve-1,pve-2,pve-3 mgr: pve-1(active), standbys: pve-2, pve-3 osd: 6 osds: 6 up, 6 in data: pools: 1 pools, 64 pgs objects: 158 objects, 577MiB usage: 7.66GiB used, 172GiB / 180GiB avail pgs: 64 active+clean io: client: 19.2KiB/s rd, 1.83MiB/s wr, 2op/s rd, 111op/s wr 2018-09-25 20:00:00.000168 mon.pve-1 [INF] overall HEALTH_OK
其中,io client: 19.2KiB/s rd, 1.83MiB/s wr, 2op/s rd, 111op/s wr 显示了io读取实时数据。
五.高可用测试
上面建了一个虚拟机CentOS7-1使用的是ceph分布式存储,具备虚拟机热迁移的条件,首先实现一下虚拟机热迁移,然后再模拟虚拟机所在物理机故障的情况下,虚拟机自动迁移是否能够实现。
热迁移测试:
<> 如下图,虚拟机从pve-1主机迁移到pve-2主机:
<>
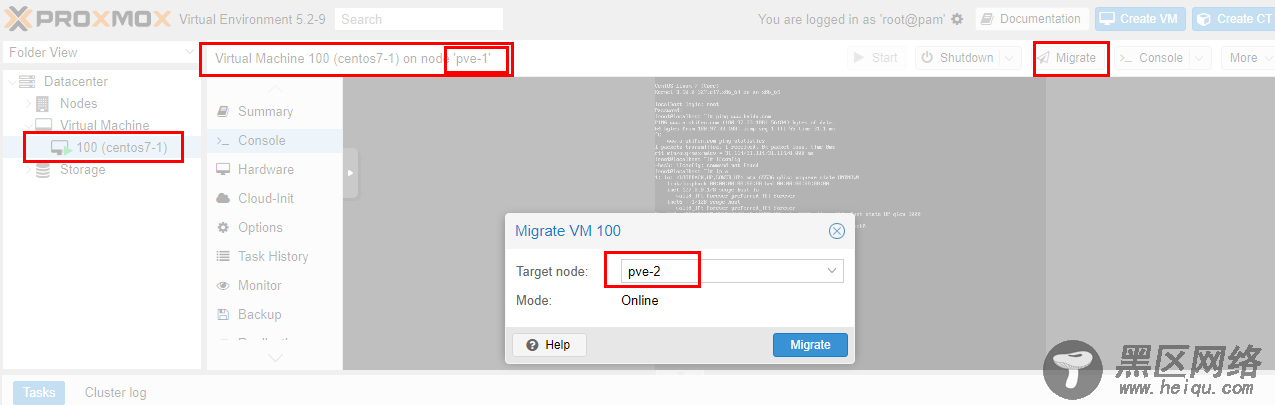
经过大概20秒钟左右,迁移完成,如下图:

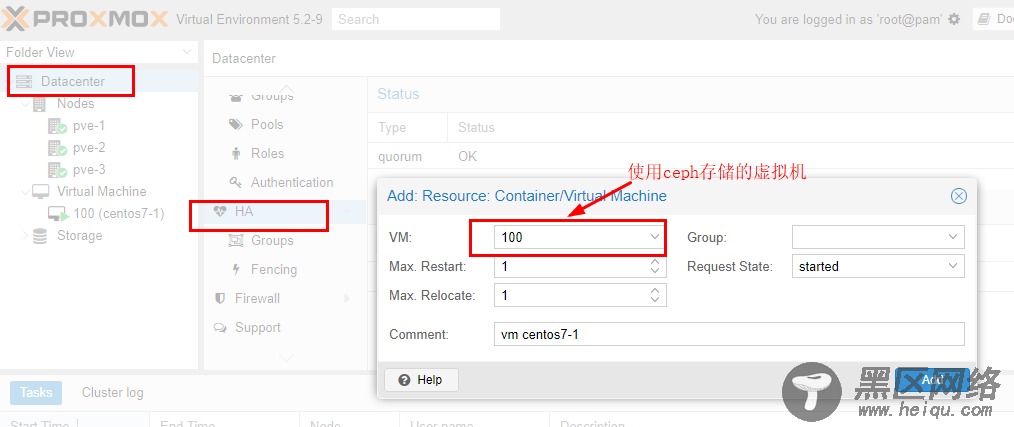
接下来将这个虚拟机加入HA,如下图:
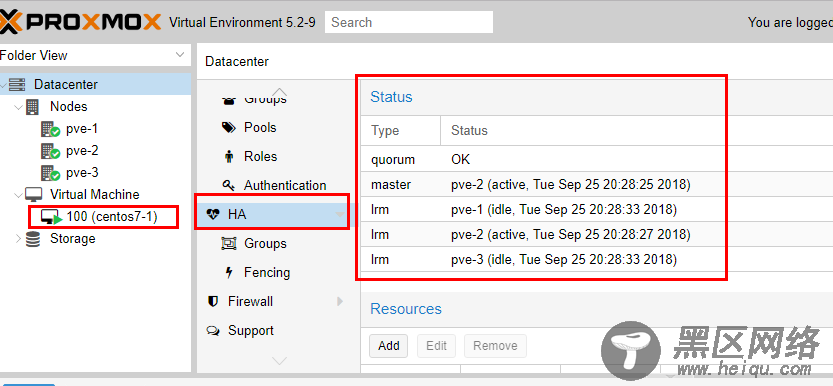
模拟物理机故障,将pve-2强制stop,如下图:

大概过了4分钟左右,加入HA的虚拟机在另一台主机pve-3中自动启动了,如下图:
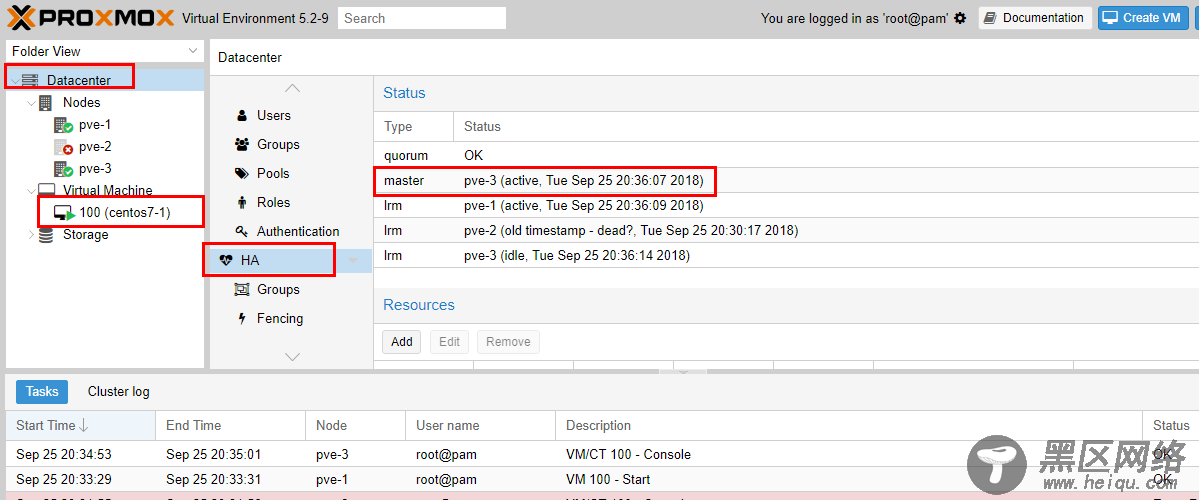
测试成功!
总结:
整体测试下来,难点在于ceph集群的搭建,对于proxmoxVE来说,只要有外部的ceph存储池,直接配置进来使用就行了,最多要再配置一下ceph的认证配置,使用了ceph存储池之后,结合ProxmoxVE的集群功能,就可以很开心的使用虚拟机在线热迁移,甚至实现虚拟机HA,即虚拟机所在物理机故障,虚拟机可以自动迁移到其他正常物理机上。
有一点需要注意,其中如果物理机故障,虚拟机HA自动迁移需要耗费的时间是以分钟计算的。这也很好理解,因为集群需要经过一段时间才能决定物理机确实脱离集群,之后才会开始重新安排物理机恢复HA虚拟机,能够实现物理机故障的情况下自动迁移还是已经很不错了,因为一般情况下,如果物理机故障,上面的虚拟机恢复其实也是一件很头疼的事情,如果能够后台在几分钟之内帮忙正常恢复,其实也是解决了大问题。