
为什么Kafka使用磁盘文件还能那么快——一个用硬盘的比用内存的还快,这绝对违反常识,因为Kafka作弊了,无论是顺序写入还是MMAP,其实都是Kafka作弊前的准备工作。
Zero Copy
Kafka使用了基于sendfile的Zero Copy提高Web Server静态文件的速度。
传统模式下,从硬盘读取一个文件是这样的:
1.调用read函数,文件数据被copy到内核的缓冲区(read是系统调用,放到了DMA,所以用内核空间)。
2.read函数返回,文件数据从内核缓冲区copy到用户缓冲区。
3.write函数调用,将文件数据从用户缓冲区copy到内核与Socket相关的缓冲区。
4.数据从Socket缓冲区copy到相关协议引擎(网卡)。
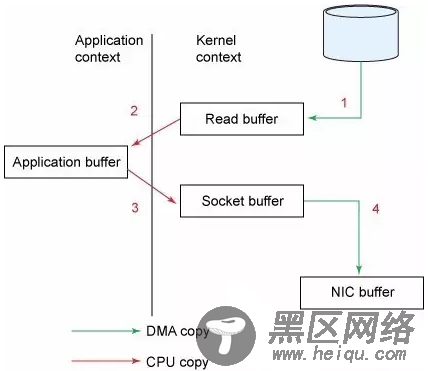
以上细节是传统的read/write方式进行网络传输的方式,我们可以看到,在这个过程当中,文件数据实际上是经过了四次copy操作:硬盘—>内核buf—>用户buf—>socket相关缓冲区—>协议引擎。而sendfile系统调用则是提供了一种减少以上多次copy,提升文件传输性能的方法。Kafka在内核版本2.1中,引用了sendfile系统调用,以此简化网络上和两个本地文件之间的数据传输。sendfile的引入不仅减少了数据复制,还减少了上下文的切换:sendfile(socket, file, len)。
运行流程如下:
1.sendfile系统调用,文件数据被copy至内核缓冲区。
2.再从内核缓冲区copy至内核中socket相关的缓冲区。
3.最后再socket相关的缓冲区copy到协议引擎。
相较传统read/write方式,2.1版本内核引进的sendfile已经减少了内核缓冲区到user缓冲区,再由user缓冲区到socket相关缓冲区的文件copy,而在内核版本2.4之后,文件描述符结果被改变,sendfile实现了更简单的方式,再次减少了一次copy操作。
在apache,nginx,lighttpd等web服务器当中,都有一项sendfile相关的配置,使用sendfile可以大幅提升文件传输性能。
Kafka把所有的消息都存放在一个一个的文件中,当消费者需要数据的时候Kafka直接把文件发送给消费者,配合MMAP作为文件读写方式,直接把它传给sendfile。
Java的NIO提供了FileChannle,它的transferTo()方法和transferFrom()方法就是Zero Copy。
Kafka的批量压缩
在很多情况下,系统的瓶颈不是CPU或磁盘,而是网络IO,对于需要在广域网上的数据中心之间发送消息的数据流水线尤其如此。进行数据压缩会消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要考虑。
1.如果每个消息都压缩,但是压缩率相对很低,所以Kafka使用了批量压缩,即将多个消息一起压缩而不是单个消息压缩。
2.Kafka允许使用递归的消息集合,批量的消息可以通过压缩的形式传输并且在日志中也可以保持压缩格式,直到被消费者解压缩。
3.Kafka支持多种压缩协议,包括Gzip和Snappy压缩协议。
Kafka速度快的秘密——作弊
Kafka把所有的消息都存放在一个一个的文件中,当消费者需要数据的时候Kafka直接把文件发送给消费者。这就是秘诀所在,比如:10W的消息组合在一起是10MB的数据量,然后Kafka用类似于发文件的方式直接扔出去了,如果消费者和生产者之间的网络非常好(只要网络稍微正常一点10MB根本不是事。。。家里上网都是100Mbps的带宽了),10MB可能只需要1s。所以答案是——10W的TPS,Kafka每秒钟处理了10W条消息。
可能你会说:不可能把整个文件发出去吧?里面还有一些不需要的消息呢?是的,Kafka作为一个【高级作弊分子】自然要把作弊做的有逼格。Zero Copy对应的是sendfile这个函数(以Linux为例),这个函数接受:
1.out_fd作为输出(一般及时socket的句柄)。
2.in_fd作为输入文件句柄。
3.off_t表示in_fd的偏移(从哪里开始读取)。
4.size_t表示读取多少个。
没错,Kafka是用MMAP作为文件读写方式的,它就是一个文件句柄,所以直接把它传给sendfile;偏移也好解决,用户会自己保持这个offset,每次请求都会发送这个offset。(还记得吗?放在zookeeper中的);数据量更容易解决了,如果消费者想要更快,就全部扔给消费者。如果这样做一般情况下消费者肯定直接就被压死了;所以Kafka提供了的两种方式——Push,我全部扔给你了,你死了不管我的事情;Pull,好吧你告诉我你需要多少个,我给你多少个。
总结