
infobright数据仓库能在高强度的压缩中把大量的数据压缩存储,平时在不断查询的过程就是在做数据解压的过程,当然具体的详细介绍在以前有提过,这里就不做过程的介绍()在infobright中支持所有的MySQL原有的数据类型,其中对整形的效率会比其他类型高,这一点同MySQL差不多,在infobright中比较高效的类型如下:
1、TINYINT,SMALLINT,MEDIUMINT,INT,BIGINT
2、DECIMAL(尽量减少小数点后的精度)
3、DATE ,TIME
这3种类型的数据能有比较高的压缩比例及查询速度,而效率比较低的、不推荐使用的数据类型有这几种:
1、BINARY VARBINARY(二进制类型)
2、FLOAT
3、DOUBLE
4、VARCHAR
5、TINYTEXT TEXT(可变长度的非Unicode类型)
这些数据类型在使用的过程中效率比较低且压缩比例并不是很高,其中VARCHAR字段在MySQL中效率就不如CHAR字段,当然在某些业务场景下可能会不得不用到CHAR(VARCHAR)的时候又经常需要频繁的查询时,但数据的记录数又并不是很多时(不多于10000行,且数据的类型多于10种以上,类似于省份、UUID这类的数据),就可以通过comment lookup的方式创建建表时的DDL来提高平时查询的效率如下:
#原建表DDL
CREATE TABLE `test_default` (
`dstphone` varchar(11) DEFAULT NULL,
`gateid` varchar(255) DEFAULT NULL
) ENGINE=BRIGHTHOUSE DEFAULT CHARSET=utf8;
#comment lookup建表DDL
CREATE TABLE `test_lookup` (
`dstphone` varchar(11) DEFAULT NULL COMMENT 'lookup',
`gateid` varchar(255) DEFAULT NULL COMMENT 'lookup'
) ENGINE=BRIGHTHOUSE DEFAULT CHARSET=utf8;
这里需要注意的是comment lookup的方式目前仅有在CHAR(VARCHAR)中能使用,其次在平时带来更高的查询效率所带来的代价就是磁盘开销,因为infobright在平时查询的时候就是在做解压的过程,所以使用comment lookup的方式就是降低压缩比例,在查询的时候能更快速的解压数据,如下可以看出comment lookup的方式同默认的建表时不同的压缩比例
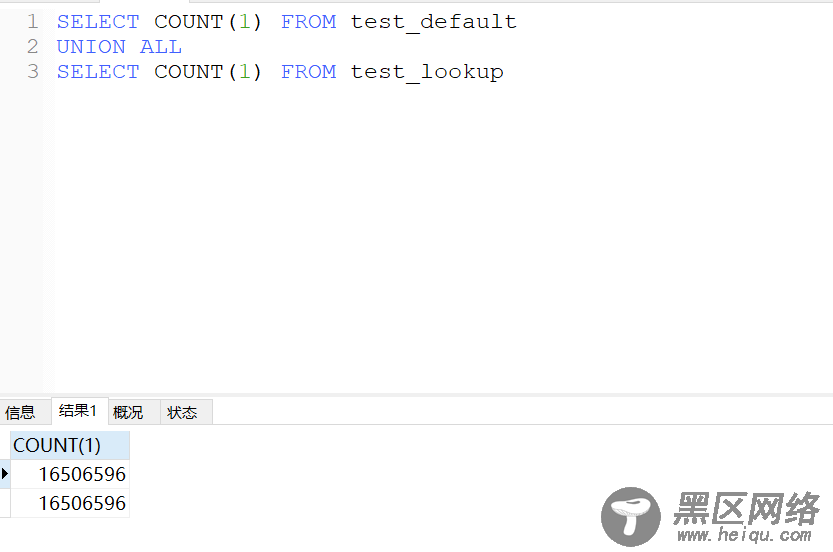

查询效率如下:
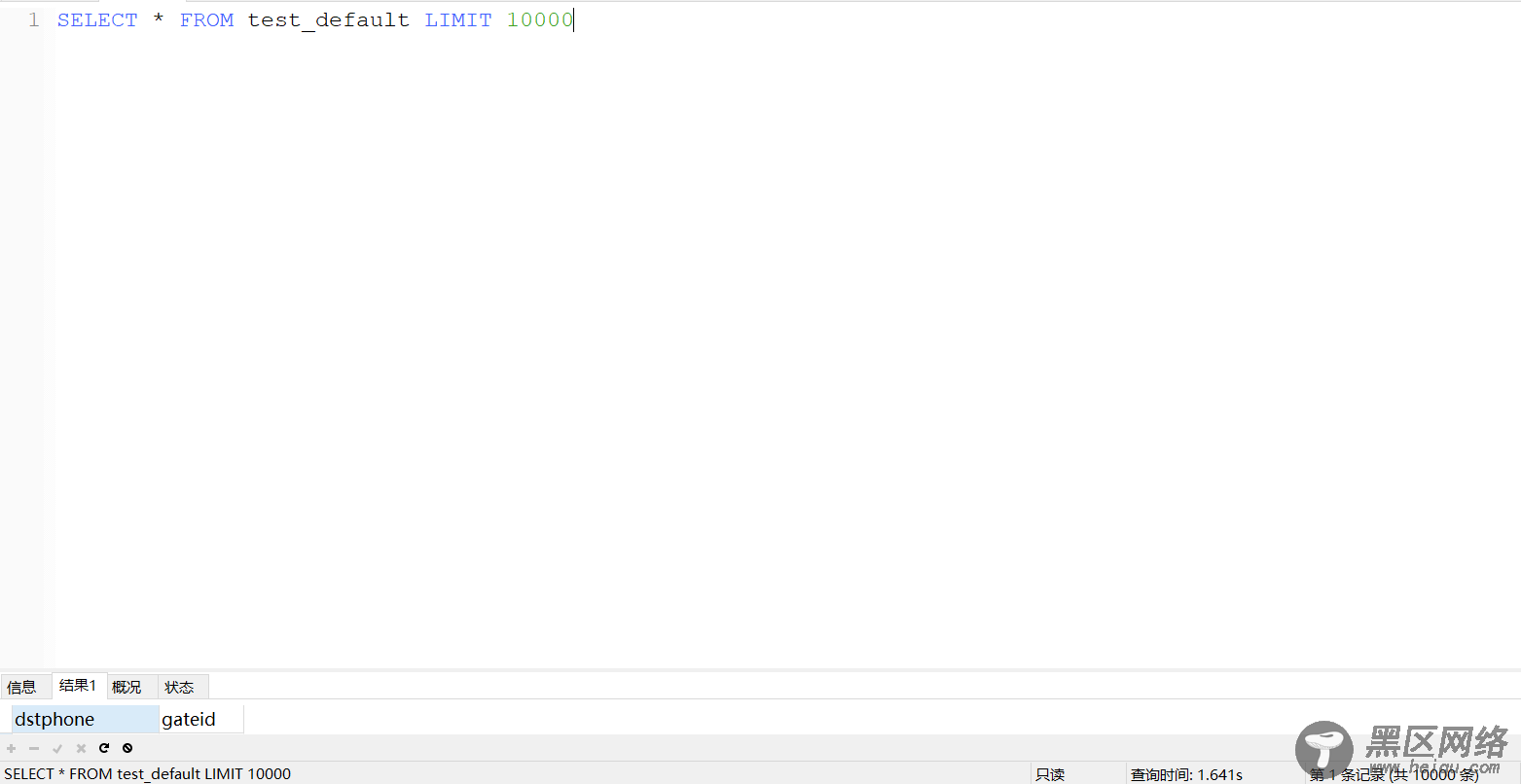
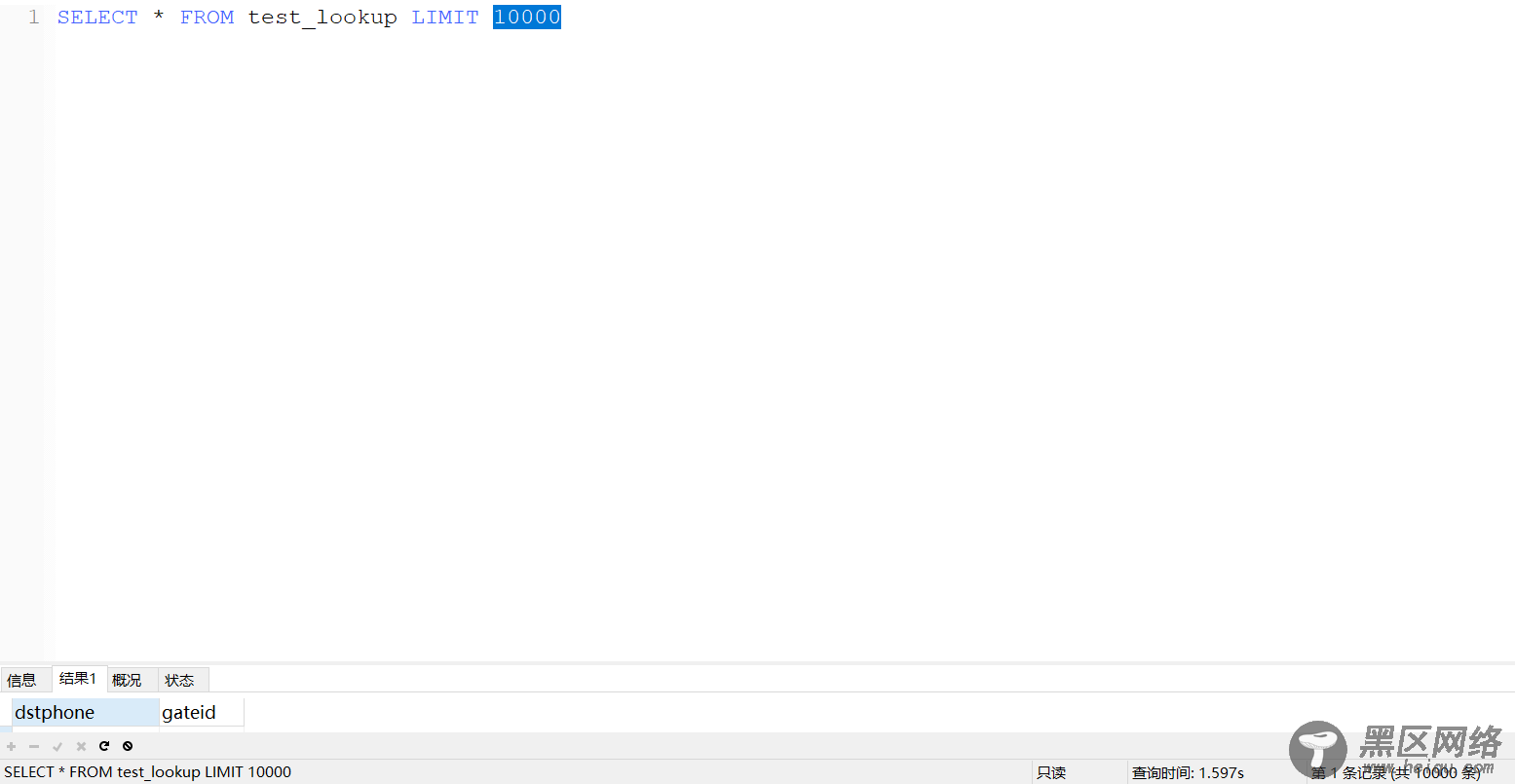
可以看相同的数据下所占用磁盘空间,但相应的在查询记录不能超过10000行,不然反而还会降低其效率:
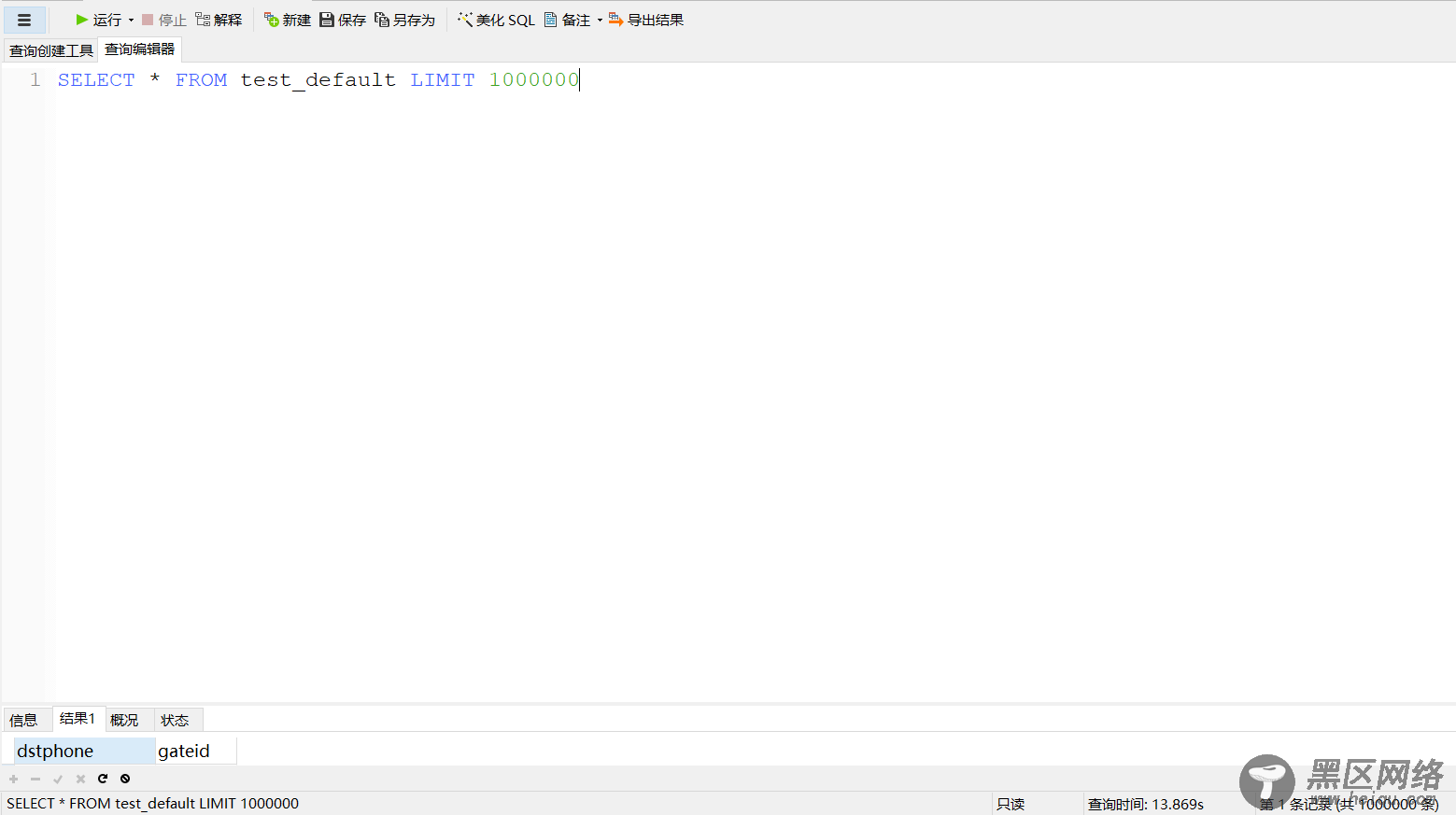
所以在使用的过程中还需要根据实际情况来选择。