
RAID系统中会存在一个称之为Write Hole的问题,这到底是一个什么问题?会给用户带来什么影响?目前开源RAID系统中如何解决这个问题?这类问题需要采用什么方式来解决呢?存储老吴从研发的角度和大家一起分析一下这个问题,看看这个问题的本质以及解决思路。
Write Hole是一种非常形象的描述。对于一个采用条带内部通过校验数据进行数据保护的系统,当应用程序正在更新条带内部数据的时候,如果系统突然断电,条带数据无法正常更新完成,那么此时就会出现条带中的数据部分更新完成。在这种情况下,当系统重启之后,条带中的数据是不完整的,校验数据和条带中的有效数据无法匹配上,条带处于数据不一致的情况。这种问题就被称之为Write Hole问题,如下图所示:
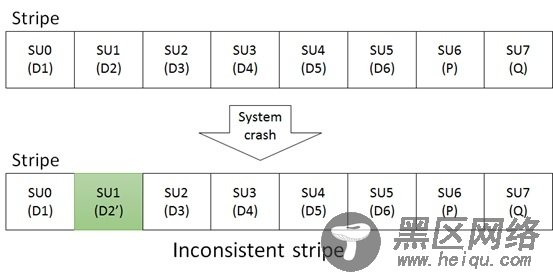
在更新条带数据的时候,D2数据被更新成了D2’,但是条带的校验数据P、Q没有被更新完成,此时系统由于发生故障而重启。在这种情况下,条带数据处于不一致的状态。系统重启之后,通常RAID系统无法感知这种数据不一致的条带。在这种情况下,如果条带中的D3再次发生了故障,那么需要通过校验数据P恢复D3。在数据恢复过程中,使用到了D2’数据,那么显然恢复出来的数据会发生错误,不再是原来的D3数据。所以,数据不一致的条带将会进一步引入数据正确性的问题。即Write Hole问题不仅破坏被更新过的数据,进一步会潜在影响未更新数据的正确性,在极端情况下会影响整条带数据的正确性。
考虑在发生Write Hole问题的时候,即在条带数据更新时,系统突然断电,RAID系统中出现若干数据不一致的条带。在系统重启之后,针对这些数据不一致的条带,可以采用全系统扫描的方式对数据不一致条带进行修复。这也是目前很多RAID系统所常用的方法,通过这种方式可以防止数据不一致条带进一步导致未更新数据的正确性问题。在RAID系统中通常存在SYNC功能,当系统非法重启之后,可以通过SYNC功能对RAID中的所有条带进行检查,并且将数据不一致条带进行修复。这种方式可以防止Write Hole问题的扩散,但是还是会导致RAID系统中部分数据的彻底丢失。
为了彻底解决Write Hole问题,在设计RAID的时候可以采用如下两种方法:
1,采用文件系统的Journal(日志)的设计思想,实现写请求的原子处理
2,借助于采用非易失性内存做为写缓存,达到原子写操作的目的
这两种思路本质上是类似的,第二种是对第一种的优化。我们知道文件系统在数据更新的时候为了保证数据更新的原子性,可以采用日志的方式,把一次数据更新操作看成一次transaction(事务)。即不管一次数据更新操作有多少次IO,从外部来看这是一次原子操作,可以称之为atomic write。当atomic write中间过程发生故障时,系统重启之后可以继续操作,保证数据要么更新完成,要么完全没有写入,不会存在中间状态。RAID系统想要解决Write Hole的问题,也需要引入这种Atomic write的机制。很直接的想法是在每次RAID进行条带数据更新的时候,首先记录一下日志,保存事件类型以及相关的数据;然后再将数据提交到条带中;当条带数据全部更新完成之后,清除日志数据。这种方式可以保证原子写,即使在条带数据更新过程中发生系统故障,系统重启之后,通过日志数据可以继续写过程,保证条带数据完全更新完毕,并处于数据一致的状态。
日志的方式看似完美,但是会严重影响性能。在磁盘存储系统中,日志更新非常耗时,一次更新需要进行多次磁盘IO操作,如果日志存储空间和条带存储空间在物理上不连续,那么将会引入磁盘抖动问题,严重影响性能。对于闪存存储系统,引入日志系统之后,所有的数据操作将会引入双倍的数据写入操作,写放大问题变得非常棘手。所以,在开源RAID系统中,都没有提供这种日志操作方式,通常需要上层的文件系统来解决这种write hole的问题。在商用的一些RAID系统中,为了保证极致的数据可靠性,有些系统实现了这种日志数据更新方式,达到Atomic Write的目的。
另一种比日志方式更好的方法是引入非易失内存NVRAM。在更新RAID数据的时候,首先将数据写入非易失内存中,当NVRAM中的数据聚合完毕之后再更新写入条带。当条带中的数据更新完毕之后,再将NVRAM中的数据清楚。在条带数据更新的过程中,如果系统出现异常重启,由于NVRAM中依然存在未完成更新的数据,所以,条带中的数据将会被再次更新,不会存在中间数据状态,不会存在Write Hole的问题。