
开发机器上安装jdk1.7.0_60和scala2.10.4,配置好相关环境变量。网上资料很多,安装过程忽略。此外,Eclipse使用Luna4.4.1,IDEA使用14.0.2版本。
1. Eclipse开发环境搭建
1.1. 安装scala插件

解压缩以后把plugins和features复制到eclipse目录,重启eclipse以后即可。
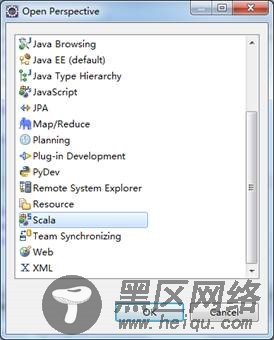
Window -> Open Perspective -> Other…,打开Scala,说明安装成功。
1.2. 创建maven工程
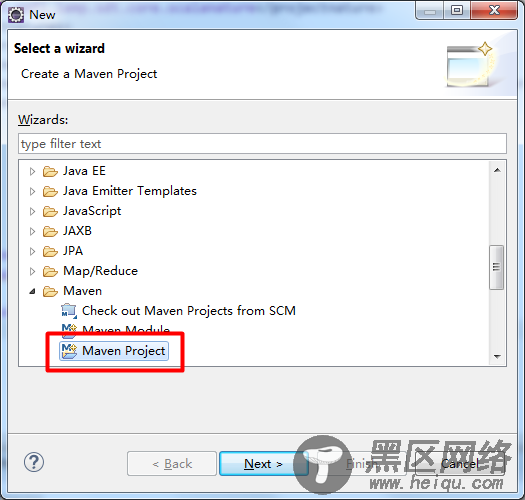
打开File -> New -> Other…,选择Maven Project:
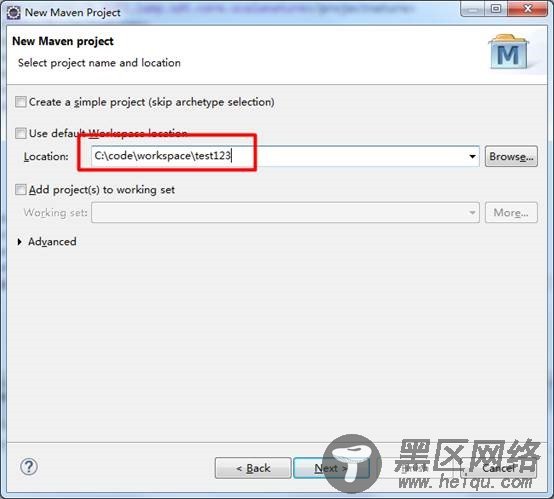
点击Next,输入项目存放路径:
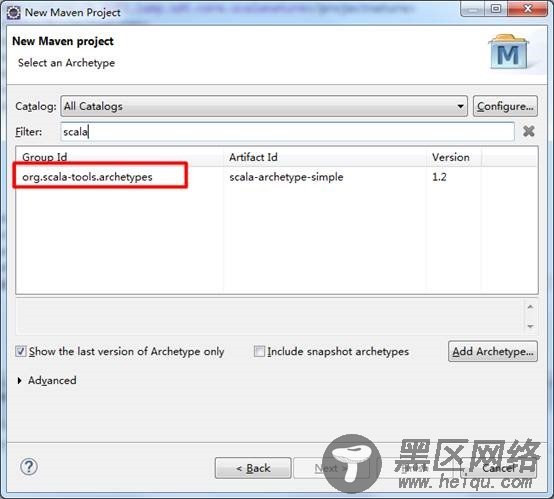
点击Next,选择org.scala-tools.archetypes:
点击Next,输入artifact相关信息:
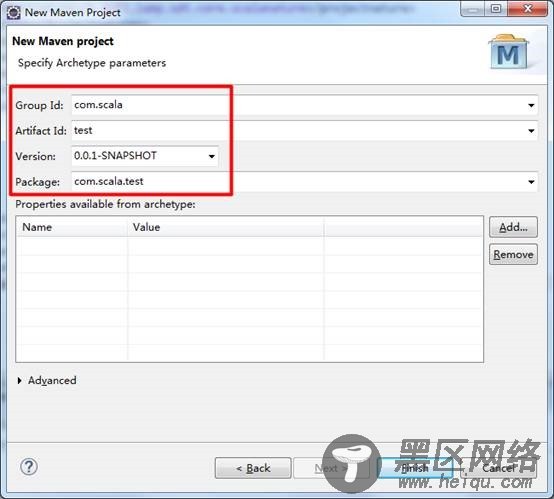
点击Finish即可。默认创建好的工程目录结构如下:
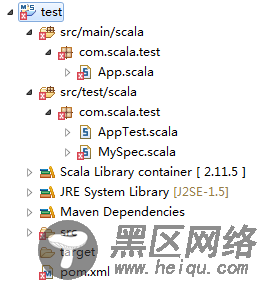
修改pom.xml文件:
至此,一个默认的scala工程新建完成。
2. Spark开发环境搭建
2.1. 安装scala插件
开发机器使用的IDEA版本为IntelliJ IEDA 14.0.2。为了使IDEA支持scala开发,需要安装scala插件,如图:
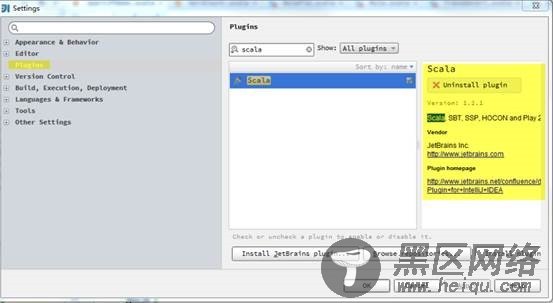
插件安装完成后,IntelliJ IDEA会要求重启。
2.2. 创建maven工程
点击Create New Project,在Project SDK选择jdk安装目录(建议开发环境中的jdk版本与Spark集群上的jdk版本保持一致)。点击左侧的Maven,勾选Create from archetype,选择org.scala-tools.archetypes:scala-archetype-simple:
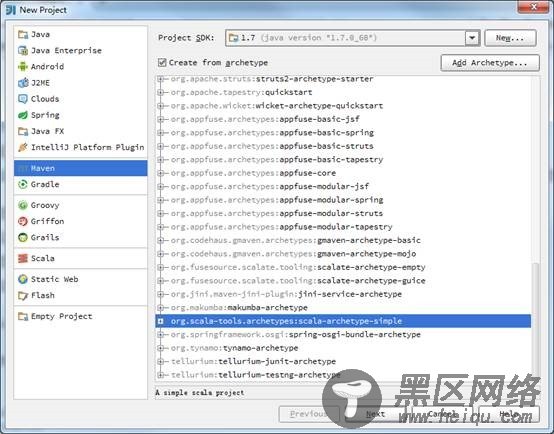
点击Next后,可根据需求自行填写GroupId,ArtifactId和Version(请保证之前已经安装maven)。点击Finish后,maven会自动生成pom.xml和下载依赖包。同1.2章节中eclipse下创建maven工程一样,需要修改pom.xml中scala版本。
至此,IDEA下的一个默认scala工程创建完毕。
3. WordCount示例程序
3.1. 修改pom文件
在pom文件中添加spark和Hadoop相关依赖包:
<!-- Spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.1.0</version>
</dependency>
<!-- Spark Steaming-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.1.0</version>
</dependency>
<!-- HDFS -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
在<build></build>中使用maven-assembly-plugin插件,目的是package时把依赖jar也打包。
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.5.5</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.ccb.WordCount</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
3.2. WordCount示例
WordCount用来统计输入文件中所有单词出现的次数,代码参考:
package com.ccb
import org.apache.spark.{ SparkConf, SparkContext }
import org.apache.spark.SparkContext._
/**
* 统计输入目录中所有单词出现的总次数
*/
object WordCount {
def main(args: Array[String]) {
val dirIn = "hdfs://192.168.62.129:9000/user/vm/count_in"
val dirOut = "hdfs://192.168.62.129:9000/user/vm/count_out"
val conf = new SparkConf()
val sc = new SparkContext(conf)
val line = sc.textFile(dirIn)
val cnt = line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _) // 文件按空格拆分,统计单词次数
val sortedCnt = cnt.map(x => (x._2, x._1)).sortByKey(ascending = false).map(x => (x._2, x._1)) // 按出现次数由高到低排序
sortedCnt.collect().foreach(println) // 控制台输出
sortedCnt.saveAsTextFile(dirOut) // 写入文本文件
sc.stop()
}
}
3.3. 提交spark执行
使用maven pacakge打包得到sparktest-1.0-SNAPSHOT.jar,并提交到spark集群运行。
执行命令参考:
./spark-submit --name WordCountDemo --class com.ccb.WordCount sparktest-1.0-SNAPSHOT.jar
即可得到统计结果。