
Proxy模式也是新版etcd的一个重要变更,etcd作为一个反向代理把客户的请求转发给可用的etcd集群。这样,你就可以在每一台机器都部署一个Proxy模式的etcd作为本地服务,如果这些etcd Proxy都能正常运行,那么你的服务发现必然是稳定可靠的。
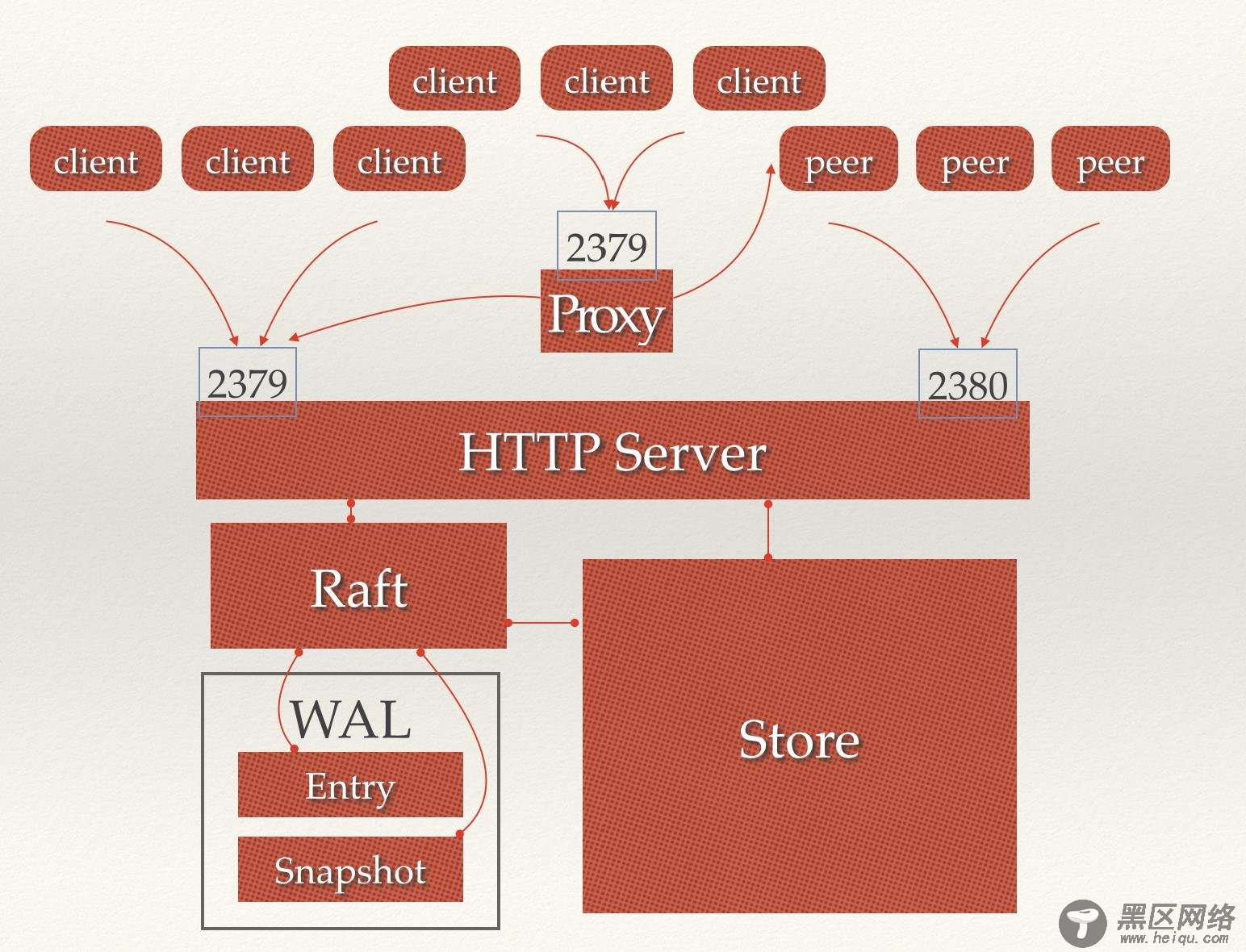
图11 Proxy模式示意图
所以Proxy并不是直接加入到符合强一致性的etcd集群中,也同样的,Proxy并没有增加集群的可靠性,当然也没有降低集群的写入性能。
5.1 Proxy取代Standby模式的原因那么,为什么要有Proxy模式而不是直接增加etcd核心节点呢?实际上etcd每增加一个核心节点(peer),都会增加Leader节点一定 程度的包括网络、CPU和磁盘的负担,因为每次信息的变化都需要进行同步备份。增加etcd的核心节点可以让整个集群具有更高的可靠性,但是当数量达到一 定程度以后,增加可靠性带来的好处就变得不那么明显,反倒是降低了集群写入同步的性能。因此,增加一个轻量级的Proxy模式etcd节点是对直接增加 etcd核心节点的一个有效代替。
熟悉0.4.6这个旧版本etcd的用户会发现,Proxy模式实际上是取代了原先的Standby模式。Standby模式除了转发代理的功能以 外,还会在核心节点因为故障导致数量不足的时候,从Standby模式转为正常节点模式。而当那个故障的节点恢复时,发现etcd的核心节点数量已经达到 的预先设置的值,就会转为Standby模式。
但是新版etcd中,只会在最初启动etcd集群时,发现核心节点的数量已经满足要求时,自动启用Proxy模式,反之则并未实现。主要原因如下。
etcd是用来保证高可用的组件,因此它所需要的系统资源(包括内存、硬盘和CPU等)都应该得到充分保障以保证高可用。任由集群的自动变换随意地改变核心节点,无法让机器保证性能。所以etcd官方鼓励大家在大型集群中为运行etcd准备专有机器集群。
因为etcd集群是支持高可用的,部分机器故障并不会导致功能失效。所以机器发生故障时,管理员有充分的时间对机器进行检查和修复。
自动转换使得etcd集群变得复杂,尤其是如今etcd支持多种网络环境的监听和交互。在不同网络间进行转换,更容易发生错误,导致集群不稳定。
基于上述原因,目前Proxy模式有转发代理功能,而不会进行角色转换。
5.2 关键部分源码解析从代码中可以看到,Proxy模式的本质就是起一个HTTP代理服务器,把客户发到这个服务器的请求转发给别的etcd节点。
etcd目前支持读写皆可和只读两种模式。默认情况下是读写皆可,就是把读、写两种请求都进行转发。而只读模式只转发读的请求,对所有其他请求返回501错误。
值得注意的是,除了启动过程中因为设置了proxy参数会作为Proxy模式启动。在etcd集群化启动时,节点注册自身的时候监测到集群的实际节点数量已经符合要求,那么就会退化为Proxy模式。
6 数据存储etcd的存储分为内存存储和持久化(硬盘)存储两部分,内存中的存储除了顺序化的记录下所有用户对节点数据变更的记录外,还会对用户数据进行索引、建堆等方便查询的操作。而持久化则使用预写式日志(WAL:Write Ahead Log)进行记录存储。
在WAL的体系中,所有的数据在提交之前都会进行日志记录。在etcd的持久化存储目录中,有两个子目录。一个是WAL,存储着所有事务的变化记 录;另一个则是snapshot,用于存储某一个时刻etcd所有目录的数据。通过WAL和snapshot相结合的方式,etcd可以有效的进行数据存 储和节点故障恢复等操作。
既然有了WAL实时存储了所有的变更,为什么还需要snapshot呢?随着使用量的增加,WAL存储的数据会暴增,为了防止磁盘很快就爆 满,etcd默认每10000条记录做一次snapshot,经过snapshot以后的WAL文件就可以删除。而通过API可以查询的历史etcd操作 默认为1000条。
首次启动时,etcd会把启动的配置信息存储到data-dir参数指定的数据目录中。配置信息包括本地节点的ID、集 群ID和初始时集群信息。用户需要避免etcd从一个过期的数据目录中重新启动,因为使用过期的数据目录启动的节点会与集群中的其他节点产生不一致(如: 之前已经记录并同意Leader节点存储某个信息,重启后又向Leader节点申请这个信息)。所以,为了最大化集群的安全性,一旦有任何数据损坏或丢失 的可能性,你就应该把这个节点从集群中移除,然后加入一个不带数据目录的新节点。
6.1 预写式日志(WAL)WAL(Write Ahead Log)最大的作用是记录了整个数据变化的全部历程。在etcd中,所有数据的修改在提交前,都要先写入到WAL中。使用WAL进行数据的存储使得etcd拥有两个重要功能。
故障快速恢复: 当你的数据遭到破坏时,就可以通过执行所有WAL中记录的修改操作,快速从最原始的数据恢复到数据损坏前的状态。
数据回滚(undo)/重做(redo):因为所有的修改操作都被记录在WAL中,需要回滚或重做,只需要方向或正向执行日志中的操作即可。
WAL与snapshot在etcd中的命名规则在etcd的数据目录中,WAL文件以$seq-$index.wal的格式存储。最初始的WAL文件是0000000000000000-0000000000000000.wal,表示是所有WAL文件中的第0个,初始的Raft状态编号为0。运行一段时间后可能需要进行日志切分,把新的条目放到一个新的WAL文件中。
假设,当集群运行到Raft状态为20时,需要进行WAL文件的切分时,下一份WAL文件就会变为0000000000000001-0000000000000021.wal。如果在10次操作后又进行了一次日志切分,那么后一次的WAL文件名会变为0000000000000002-0000000000000031.wal。可以看到-符号前面的数字是每次切分后自增1,而-符号后面的数字则是根据实际存储的Raft起始状态来定。
snapshot的存储命名则比较容易理解,以$term-$index.wal格式进行命名存储。term和index就表示存储snapshot时数据所在的raft节点状态,当前的任期编号以及数据项位置信息。
6.2 关键部分源码解析从代码逻辑中可以看到,WAL有两种模式,读模式(read)和数据添加(append)模式,两种模式不能同时成立。一个新创建的WAL文件处于 append模式,并且不会进入到read模式。一个本来存在的WAL文件被打开的时候必然是read模式,并且只有在所有记录都被读完的时候,才能进入 append模式,进入append模式后也不会再进入read模式。这样做有助于保证数据的完整与准确。
集群在进入到etcdserver/server.go的NewServer函数准备启动一个etcd节点时,会检测是否存在以前的遗留WAL数据。
检测的第一步是查看snapshot文件夹下是否有符合规范的文件,若检测到snapshot格式是v0.4的,则调用函数升级到v0.5。从 snapshot中获得集群的配置信息,包括token、其他节点的信息等等,然后载入WAL目录的内容,从小到大进行排序。根据snapshot中得到 的term和index,找到WAL紧接着snapshot下一条的记录,然后向后更新,直到所有WAL包的entry都已经遍历完毕,Entry记录到 ents变量中存储在内存里。此时WAL就进入append模式,为数据项添加进行准备。
当WAL文件中数据项内容过大达到设定值(默认为10000)时,会进行WAL的切分,同时进行snapshot操作。这个过程可以在etcdserver/server.go的snapshot函数中看到。所以,实际上数据目录中有用的snapshot和WAL文件各只有一个,默认情况下etcd会各保留5个历史文件。