
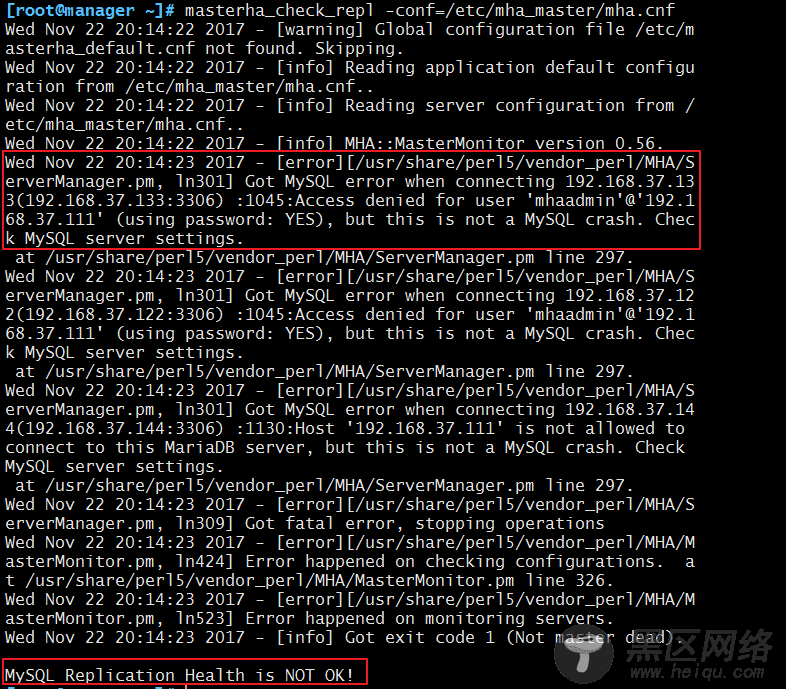
我们发现检测失败,这可能是因为从节点上没有账号,因为这个架构,任何一个从节点, 将有可能成为主节点, 所以也需要创建账号。
因此,我们需要在master节点上再次执行以下操作: MariaDB [(none)]> grant replication slave,replication client on *.* to 'slave'@'192.168.%.%' identified by 'keer'; MariaDB [(none)]> flush privileges;
执行完这段操作之后,我们再次运行检测命令:
[root@manager ~]# masterha_check_repl -conf=/etc/mha_master/mha.cnf Thu Nov 23 09:07:08 2017 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Thu Nov 23 09:07:08 2017 - [info] Reading application default configuration from /etc/mha_master/mha.cnf.. Thu Nov 23 09:07:08 2017 - [info] Reading server configuration from /etc/mha_master/mha.cnf.. …… MySQL Replication Health is OK. 可以看出,我们的检测已经ok了。
此步骤完成。
我们在 manager 节点上执行以下命令来启动 MHA:
[root@manager ~]# nohup masterha_manager -conf=/etc/mha_master/mha.cnf &> /etc/mha_master/manager.log & [1] 7598启动成功以后,我们来查看一下 master 节点的状态:
[root@manager ~]# masterha_check_status -conf=/etc/mha_master/mha.cnf mha (pid:7598) is running(0:PING_OK), master:192.168.37.122 上面的信息中“mha (pid:7598) is running(0:PING_OK)”表示MHA服务运行OK,否则, 则会显示为类似“mha is stopped(1:NOT_RUNNING).”
如果,我们想要停止 MHA ,则需要使用 stop 命令:
我们来查看日志:
[root@manager ~]# tail -200 /etc/mha_master/manager.log …… Thu Nov 23 09:17:19 2017 - [info] Master failover to 192.168.37.133(192.168.37.133:3306) completed successfully. 表示 manager 检测到192.168.37.122节点故障, 而后自动执行故障转移, 将192.168.37.133提升为主节点。
注意,故障转移完成后, manager将会自动停止, 此时使用 masterha_check_status 命令检测将会遇到错误提示, 如下所示:
原有 master 节点故障后,需要重新准备好一个新的 MySQL 节点。基于来自于master 节点的备份恢复数据后,将其配置为新的 master 的从节点即可。注意,新加入的节点如果为新增节点,其 IP 地址要配置为原来 master 节点的 IP,否则,还需要修改 mha.cnf 中相应的 ip 地址。随后再次启动 manager ,并再次检测其状态。
我们就以刚刚关闭的那台主作为新添加的机器,来进行数据库的恢复:
原本的 slave1 已经成为了新的主机器,所以,我们对其进行完全备份,而后把备份的数据发送到我们新添加的机器上:
然后在 node2 节点上进行数据恢复:
[root@master ~]# mysql < mysql-backup-2017-11-23-09\:57\:09-all.sql接下来就是配置主从。照例查看一下现在的主的二进制日志和位置,然后就进行如下设置:
MariaDB [(none)]> change master to master_host='192.168.37.133', master_user='slave', master_password='keer', master_log_file='mysql-bin.000006', master_log_pos=925; MariaDB [(none)]> start slave; MariaDB [(none)]> show slave status\G; Slave_IO_State: Waiting for master to send event Master_Host: 192.168.37.133 Master_User: slave Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000006 Read_Master_Log_Pos: 925 Relay_Log_File: mysql-relay-bin.000002 Relay_Log_Pos: 529 Relay_Master_Log_File: mysql-bin.000006 Slave_IO_Running: Yes Slave_SQL_Running: Yes …… 可以看出,我们的主从已经配置好了。
本步骤完成。
我们来再次检测状态:
[root@manager ~]# masterha_check_repl -conf=/etc/mha_master/mha.cnf