
在文章开始之前,我们还是简单来回顾下Pig的的前尘往事:
1,Pig是什么?
Pig最早是雅虎公司的一个基于Hadoop的并行处理架构,后来Yahoo将Pig捐献给Apache(一个开源软件的基金组织)的一个项目,由Apache来负责维护,Pig是一个基于 Hadoop的大规模数据分析平台,它提供的SQL-like语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。Pig为复杂的海量数据并行计算提供了一个简 易的操作和编程接口,这一点和FaceBook开源的Hive(一个以SQL方式,操作hadoop的一个开源框架)一样简洁,清晰,易上手!
2,Pig用来干什么?
要回答这个问题,还得回归到雅虎当初使用Pig的目的:
1)吸收和分析用户的行为日志数据(点击流分析、搜索内容分析等),改进匹配和排名算法,以提高检索和广告业务的质量。
2)构建和更新search index。对于web-crawler抓取了的内容是一个流数据的形式,这包括去冗余、链接分析、内容分类、基于点击次数的受欢迎程度计算(PageRank)、最后建立倒排表。
3)处理半结构化数据订阅(data seeds)服务。包括:deduplcaitin(去冗余),geographic location resolution,以及 named entity recognition.
3, Pig在Hadoop生态系统中的地位
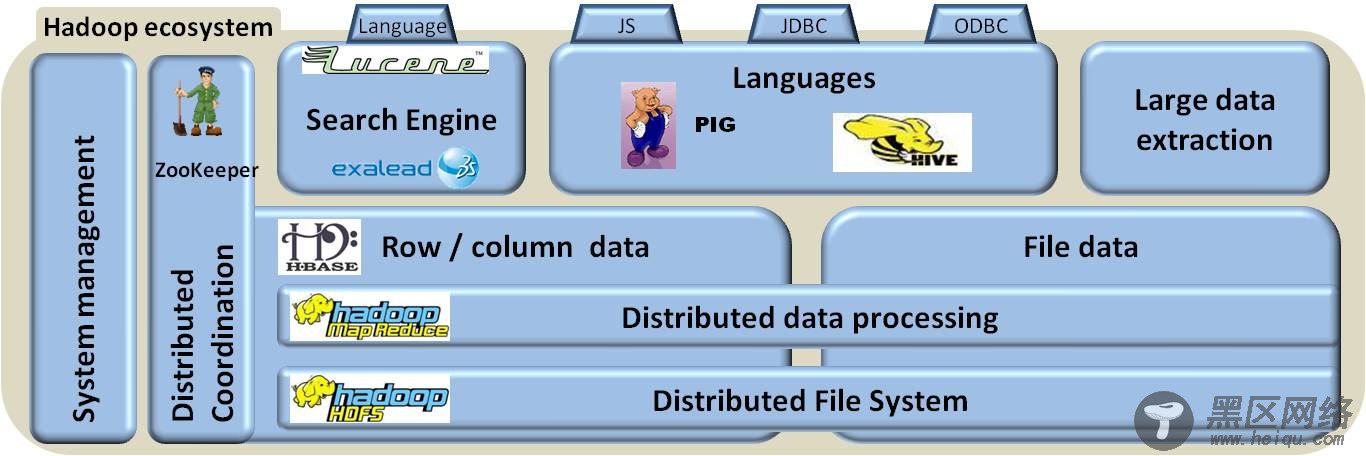
OK,下面回答正题,散仙最近在做的一个项目也是有关我们站搜索的关键词的点击率分析,我们的全站的日志数据,全部记录在Hadoop上,散仙初步要做的任务以及此任务的意义如下:
(1)找出来自我站搜索的数据
(2)分析关键词在某个时期内的搜索次数
(3)分析关键词在某个时期的点击次数
(4)通过这些数据,找出一些搜索无点击,搜索有点击,搜索点击少,和少搜索点击高等的一些边界关键词
(5)通过分析这些关键词,来评估我们站的搜索质量,给搜索方案的优化,以及改良提供一些参考依据
(6)使用Lucene或Solr索引存储分析后的数据,并提供灵活强大的检索方式
具体的使用Pig分析数据过程,散仙在这里就不细写了,感兴趣的朋友,可以在微信公众号的后台留言咨询,今天主要看下,Pig分析完的数据结果如何存储到Lucene索引里,至于为什么选择lucene系列的索引存储,而不选择数据库存储或直接存储在HDFS上,最大的原因还是在速度上,散仙前段时间分析的数据是直接存储在HDFS上,存HDFS上是很好,又能备份,还能容灾,但是! 但是查询,读取,过滤,转换就非常麻烦了,速度慢的没法说,每次都得读取数据,然后使用JAVA程序计算出最终结果,然后给前端展示,即使数据量并不太大,但中间耗费了较多的时间数据的读取,传输和分析上,所以这次在分析关键词的转化率时,干脆就顺便研究下,如何使用Pig和Lucene,Solr或者ElasticSearch集成。
Pig或Hive本身能直接将各种格式的文件包括二进制,json,avro,以及bzip,gzip,lzo,snappy,orc等各种压缩格式存储在HDFS上或Hbase里,但是却不能直接将Lucene索引存储在HDFS上,至于为什么不能直接存储索引在HDFS上,这个与倒排索引的文件结构的组织方式有一定的关系,感兴趣的朋友可以在微信公众号上留言咨询,虽说不能直接存储在HDFS上,但是我们可以间接得通过他们的UDF函数来扩展Pig或Hive,使得他们支持索引存储,注意这里虽然实现了索引存储在HDFS上,但实质却是,在本地的临时目录先生成索引,然后又变相的拷贝到了HDFS上,算是一种折中的算式吧。在Pig里,需要定义两个UDF上来完成索引存储这件事,一个主要是创建索引,另一个是索引输出,在github上已有大牛实现了,我们需要做的工作:
(1)访问这个地址下载这个压缩包。
(2)提取出自己想要的部分,在eclipse工程中,修改定制适合自己环境的的代码(Lucene版本是否兼容?hadoop版本是否兼容?,Pig版本是否兼容?)。
(3)使用ant重新打包成jar
(4)在pig里,注册相关依赖的jar包,并使用索引存储
下面给出,散仙的测试的脚本:
1.---注册依赖相关的包
2.REGISTER /home/search/nsconvent/spig/20150112/lucenepig/pigudf.jar;
3.REGISTER /home/search/nsconvent/spig/20150112/lucenepig/lucene-analyzers-common-4.10.2.jar;
4.REGISTER /home/search/nsconvent/spig/20150112/lucenepig/lucene-core-4.10.2.jar;
5.REGISTER /home/search/nsconvent/spig/20150112/lucenepig/lucene-queryparser-4.10.2.jar;
6.
7.--声明别名引用(注意只能无参的引用,带参数的在反射时候,会出现异常)
8.DEFINE LuceneStore com.pig.support.lucene.LuceneStore;
9.--加载数据
10.a = load '/tmp/data/20150303/tt.txt' using PigStorage(',') as (lbl:chararray,desc:chararray,score:int); ;
11.--生成索引并存储在HDFS上,注意需要配置简单lucene索引方式(是否存储?是否索引?)
12.store a into '/tmp/data/20150303/luceneindex' using LuceneStore('store[true]:tokenize[true]');