大部分Web应用的富文本内容都是以HTML字符串的形式存储的,通过HTML文档去展示HTML内容自然没有问题。但是,在微信小程序(下文简称为「小程序」)中,应当如何渲染这部分内容呢?
解决方案
wxParse
小程序刚上线那会儿,是无法直接渲染HTML内容的,于是就诞生了一个叫做「 wxParse 」的库。它的原理就是把HTML代码解析成树结构的数据,再通过小程序的模板把该数据渲染出来。
rich-text
后来,小程序增加了「rich-text」组件用于展示富文本内容。然而,这个组件存在一个极大的限制: 组件内屏蔽了所有节点的事件 。也就是说,在该组件内,连「预览图片」这样一个简单的功能都无法实现。
web-view
再后来,小程序允许通过「web-view」组件嵌套网页,通过网页展示HTML内容是兼容性最好的解决方案了。然而,因为要多加载一个页面,性能是较差的。
当「WePY」遇上「wxParse」
基于用户体验和功能交互上的考虑,我们抛弃了「rich-text」和「web-view」这两个原生组件,选择了「wxParse」。然而,用着用着却发现,「wxParse」也不能很好地满足需要:
我们的小程序是基于「WePY」框架开发的,而「wxParse」是基于原生的小程序编写的。要想让两者兼容,必须修改「wxParse」的源代码。
「wxParse」只是简单地通过image组件对原img元素的图片进行显示和预览。而在实际使用中,可能会用到云存储的接口对图片进行缩小,达到「 用小图显示,用原图预览 」的目的。
「wxParse」直接使用小程序的video组件展示视频,但是video组件的 层级问题 经常导致UI异常(例如把某个固定定位的元素给挡了)。
此外,围观一下「wxParse」的代码仓库可以发现,它已经两年没有迭代了。所以就萌生了基于「WePY」的组件模式重新写一个富文本组件的想法,其成果就是「WePY HTML」项目。
实现过程
解析HTML
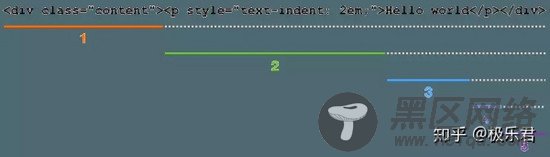
首先仍然是要把HTML字符串解析为树结构的数据,我采用的是「特殊字符分隔法」。HTML中的特殊字符是「<」和「>」,前者为开始符,后者为结束符。
如果待解析内容以开始符开头,则截取 开始符到结束符之间 的内容作为节点进行解析。
如果待解析内容不以开始符开头,则截取 开头到开始符之前 (如果开始符不存在,则为末尾)的内容作为纯文本解析。
剩余内容进入下一轮解析,直到无剩余内容为止。
正如下图所示:
为了形成树结构,解析过程中要维护一个上下文节点(默认为根节点):
如果截取出来的内容是开始标签,则根据匹配出的标签名和属性,在当前上下文节点下创建一个子节点。如果该标签不是自结束标签(br、img等),就把上下文节点设为新节点。
如果截取出来的内容是结束标签,则根据标签名关闭当前上下文节点(把上下文节点设为其父节点)。
如果是纯文本,则在当前上下文节点下创建一个文本节点,上下文节点不变。
过程正如下面的表格所示:

经过上述流程,HTML字符串就被解析为节点树了。
对比
把上述算法与其他类似的解析算法进行对比(性能以「解析10000长度的HTML代码」进行测定):
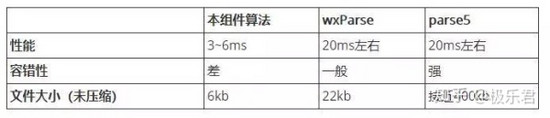
可见,在不考虑容错性(产生错误的结果,而非抛出异常)的情况下,本组件的算法与其余两者相比有压倒性的优势,符合小程序「 小而快 」的需要。而一般情况下,富文本编辑器所生成的代码也不会出现语法错误。因此,即使容错性较差,问题也不大(但这是需要改进的)。
模板渲染
树结构的渲染,必然会涉及到子节点的 递归 处理。然而,小程序的模板并不支持递归,这下仿佛掉入了一个大坑。
看了一下「wxParse」模板的实现,它采用简单粗暴的方式解决这个问题:通过13个长得几乎一模一样的模板进行嵌套调用(1调用2,2调用3,……,12调用13),也就是说最多可以支持12次嵌套。一般来说,这个深度也足够了。
由于「WePY」框架本身是有构建机制的,所以不必手写十来个几乎一模一样的模板,通过一个构建的插件去生成即可。