
目前Firmament通过与容器管理集群结合,大幅度提升容器应用的调度管理能力,解决像Kubernetes原生调度器在10K节点时,性能急剧下降且对批处理作业任务支持不够完善的情况。Kubernetes原生调度器采用的基于队列的模型,需要依赖于队列的性能,而在任务调度失败后,又再次回到队列等待继续调度,在对于计算密集型的任务调度时,对优先级、资源状态的共享支持都有待提升。
Firmament 采用的流图的机制,综合考虑了很多种影响调度结果的因素,比如Rack,AZ,Region等,甚至包括SSD硬件属性,综合这些因素考虑最小的成本,最大的流量来决定最终的调度结果。
Poseidon 主流应用场景Posedion 会充当 Firmament 与 Kubernetes 之间的桥梁,即通过Kubernetes API 获取对象的事件(Event),然后结合资源使用状况,调用 Firmament 获取调度的结果,最终完成 Pod 调度的过程。
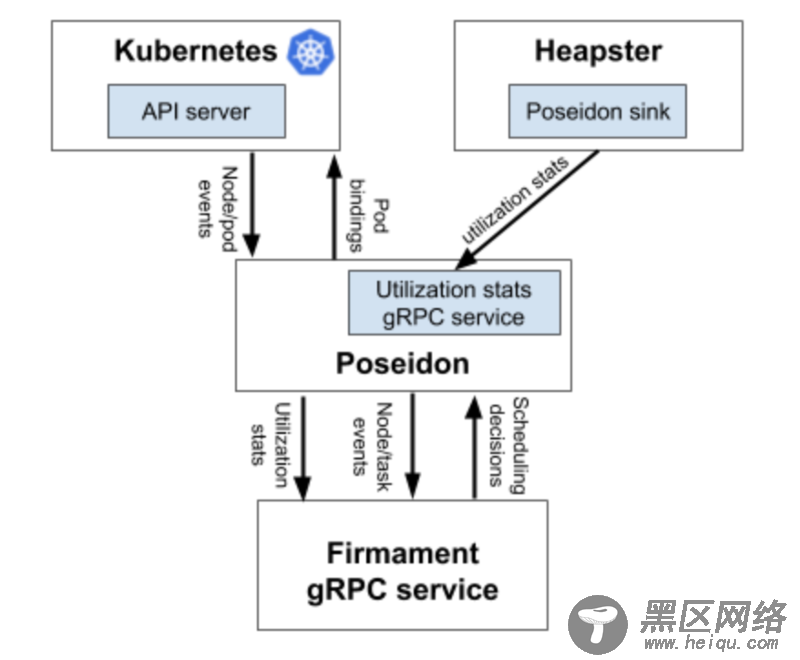
Firmament ���以理解为独立的核心算法模块,功能与原来的默认scheduler 相同,都是根据目前资源情况,给出最佳的调度结果。Firmament 本身由一系列的复杂算法组成,但对于 Posedion 来说,这些细节可以不必关系,只需要了解输入和输出的标准数据结构就好。
在具体使用的时候,Firmament、Poseidon 及 heapster 等模块都是以 Deployment 形式部署在 Kubernetes 集群中的。在部署 Pod 的时候,我们知道 Kubernetes 支持多调度器机制,可以在 Pod 的定义中指定使用哪个调度器,具体示例如下:
apiVersion: batch/v1 kind: Job metadata: name: cpuspin5 spec: completions: 1 parallelism: 1 template: metadata: name: cpuspin5 labels: schedulerName: poseidon spec: schedulerName: poseidon containers: - name: cpuspin image: firmament/libhdfs3 resources: requests: memory: "10Mi" cpu: "10m" limits: memory: "12Mi" cpu: "20m" command: ["/bin/sh", "-c", "/cpu_spin 60"] restartPolicy: Never我们在这里选择 posedion 作为其调度器,那么就可以通过 Firmament 算法来更高效、精细地决策 Pod 在哪个节点运行更合适,值得一提的是,其他的 Pod 如果不适合这些调度机制,完全可以选择默认调度器、甚至自定义的调度器,从而保证了平台的灵活性。
任务调度框架的未来趋势任务调度框架其实已经有很多,集中式和分布式的都有,一时间难以决定孰优孰劣,毕竟调度跟具体的业务场景息息相关。在未来,调度会更加精细化、更灵活,根据用户角色、业务类型、资源需求等等一系列复杂的因素,结合历史调度情况综合给出最终的结论。有些类似梯度递减形式的机器学习模型可以开始应用在调度上,已经有一些公司在做相关的探索,相信在未来大规模分布式调度会变得越来越重要。
Linux公社的RSS地址:https://www.linuxidc.com/rssFeed.aspx