hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
2. 按照Hive的准备条件
2.1 Hadoop集群环境已经安装完毕
2.2 本文使用Ubuntu做为开发环境(14.04)
3. 安装步骤
3.1 下载Hive包:apache-hive-0.13.1-bin.tar.gz
3.2 将其解压到/opt目录下
tar xzvf apache-hive-0.13.1-bin.tar.gz
3.3 设置环境变量
export HIVE_HOME=/opt/apache-hive-0.13
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:$HIVE_HOME/bin
3.4. 修改hive-env.xml,复制hive-env.xml.template.
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/opt/hadoop-1.2.1
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/opt/apache-hive-0.13/conf
3.5 修改hive-site.xml,主要修改数据库的连接信息.
<property>
<name>hive.metastore.uris</name>
<value>thrift://127.0.0.1:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
<property>
<name>Javax.jdo.option.ConnectionURL</name>
<value>jdbc:MySQL://BladeStone-Laptop:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
基于Hadoop集群的Hive安装
Hadoop + Hive + Map +reduce 集群安装部署
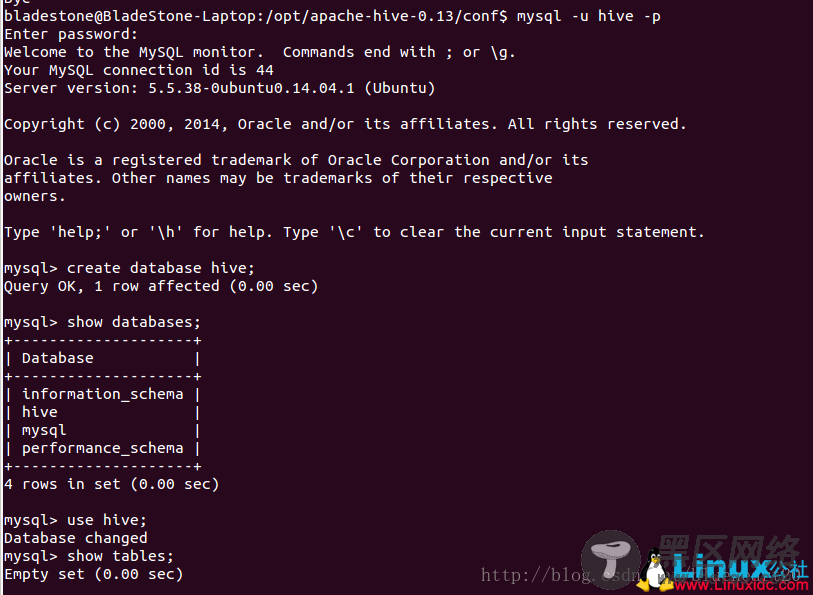
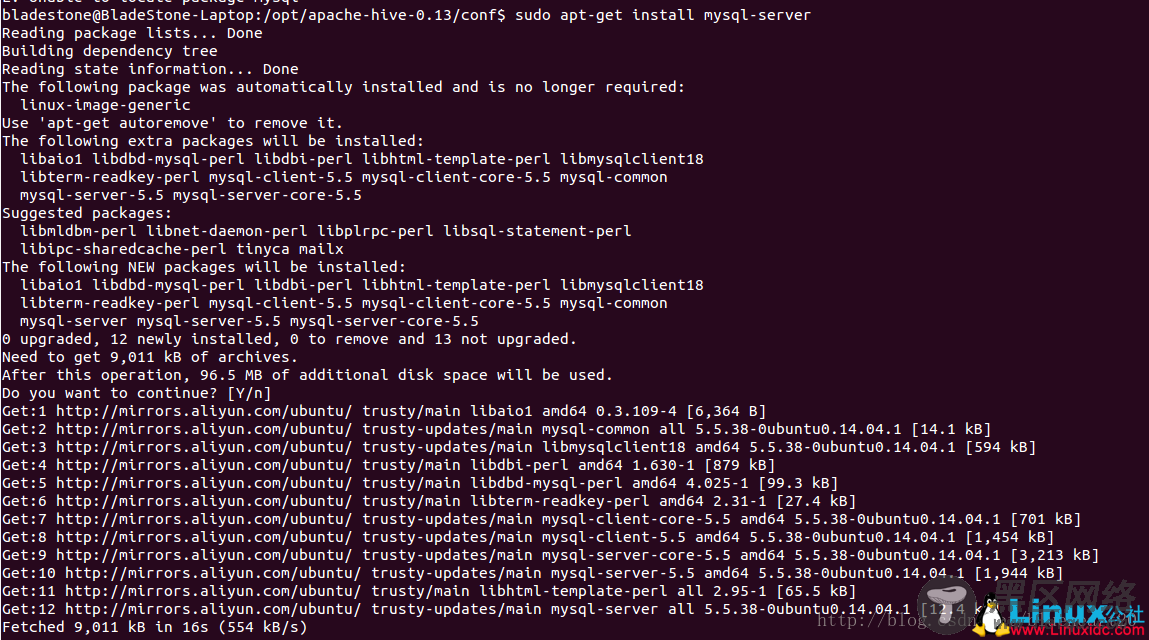
3.6 安装mysql数据库(Ubuntu系统)
sudo apt-get install mysql-server
3.7 创建mysql用户hive
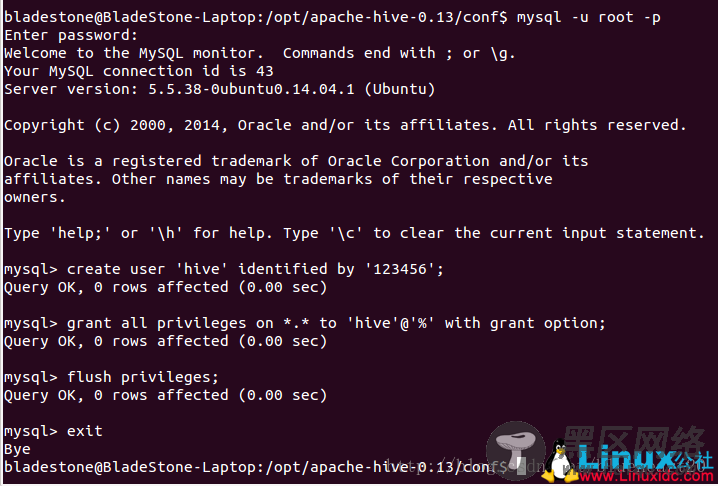
3.8 在mysql中创建hive数据库