对于 spark-sql 项目,分别选择 src/test/java 中的 test.org.apache.spark.sql 以及 test.org.apache.spark.sql.sources 包中的所有类,右键选择 Refactor->Move,移动至 org.apache.spark.sql 以及 org.apache.spark.sql.sources 包。
对于 spark-hive 项目,分别选择 src/test/java 中的 test.org.apache.spark.sql.hive 以及 test.org.apache.spark.sql.hive.execution 包中的所有类,移动至 org.apache.spark.sql.hive 以及 org.apache.spark.sql.hive.execution 包。
--------------------------------------分割线 --------------------------------------
CentOS 6.2(64位)下安装Spark0.8.0详细记录
Spark简介及其在Ubuntu下的安装使用
Hadoop vs Spark性能对比
--------------------------------------分割线 --------------------------------------
9.编译所有项目:
打开 Project->Build Automatically 功能,等待所有项目编译成功。
10.检查是否安装成功:
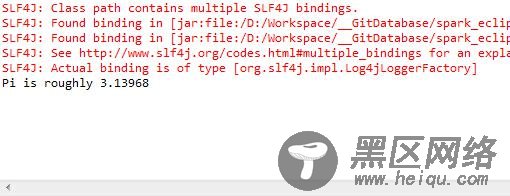
将 core 项目中的 src->main->resources->org 文件夹拷贝到 examples 项目中的 target->scala-2.10->classes 中。而后执行 examples 项目中的 org.apache.spark.examples.SparkPi 程序,并设置其 jvm 参数为-Dspark.master=local,若最后输出如图 7 结果则说明安装成功。
图 7.SparkPi 运行结果