$regex = '/HE(?=L)LLO/i';
$str = 'HELLO';
$matches = array();
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
能打印出结果!
说明:(?=L)意思是HE后面紧跟一个L字符。但是(?=L)本身不占字符,要与(L)区分,(L)本身占一个字符。
捕获数据
没有指明类型而进行的分组,将会被获取,供以后使用。
> 指明类型指的是通配符。所以只有圆括号起始位置没有问号的才能被捕捉。
> 在同一个表达式内的引用叫做反向引用。
> 调用格式: \编号(如\1)。
复制代码 代码如下:
$regex = '/^(Chuanshanjia)[\w\s!]+\1$/';
$str = 'Chuanshanjia thank Chuanshanjia';
$matches = array();
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
> 避免捕获数据
格式:(?:pattern)
优点:将使有效反向引用数量保持在最小,代码更加、清楚。
>命名捕获组
格式:(?P<组名>) 调用方式 (?P=组名)
复制代码 代码如下:
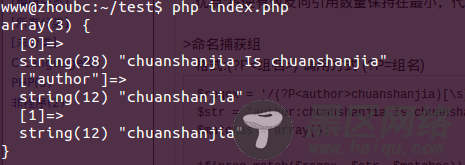
$regex = '/(?P<author>chuanshanjia)[\s]Is[\s](?P=author)/i';
$str = 'author:chuanshanjia Is chuanshanjia';
$matches = array();
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
运行结果
惰性匹配(记住:会进行两部操作,请看下面的原理部分)
格式:限定符?
原理:先匹配"?"前面的部分,然后再匹配右侧表达式,右侧表达式匹配成功则整个匹配结束。
先看下面的两个代码:
代码1.
复制代码 代码如下:
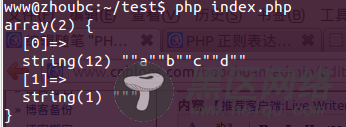
$regex = '/(")[^\1]+\1/i';
$str = '"a""b""c""d"';
$matches = array();
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
结果1.
复制代码 代码如下:
$regex = '/(")[^\1]+?\1/i';
$str = '"a""b""c""d"';
$matches = array();
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
结果2

比较两个正则表达式:第一个加了"?",第二个没有。
结果:主要看第一个参数:第一个把所有字符打印了出来,第二个只打印了个""a"".
结论:
>> 首先满足(")[^\1]+\1条件的有
"a", "a""b","a""b""c", "a""b""c""d", "b","b""c","b""c""d", "c","c""d", "d"
而第一个正则表达式却选择了最大的"a""b""c""d",说明非惰性匹配会把最大的匹配结果拿出来做比较。
>> 第二个正则表达式:先匹配(")[^\1]+,如果匹配成功,那么我们在匹配“?”右边的\1,如果匹配成功,则整个匹配结束。
其他案例:
"Oh, \"my\" God" =====> /(")([^\1] | \\1)*?(?<!\\)\1/i
正则表达式的注释
格式:(?# 注释内容)
用途:主要用于复杂的注释
贡献代码:是一个用于连接MYSQL数据库的正则表达式
复制代码 代码如下:
$regex = '/
^host=(?<!\.)([\d.]+)(?!\.) (?#主机地址)
\|
([\w!@#$%^&*()_+\-]+) (?#用户名)
\|
([\w!@#$%^&*()_+\-]+) (?#密码)
(?!\|)$/ix';
$str = 'host=192.168.10.221|root|123456';
$matches = array();
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
特殊字符
特殊字符 解释
* 0到多次
+ 1到多次还可以写成{1,}
? 0或1次
. 匹配除换行符外的所有单个的字符
\w [a-zA-Z0-9_]
\s 空白字符(空格,换行符,回车符)[\t\n\r]
\d [0-9]
您可能感兴趣的文章: