之前写了个现在看来很不完美的小爬虫,很多地方没有处理好,比如说在知乎点开一个问题的时候,它的所有回答并不是全部加载好了的,当你拉到回答的尾部时,点击加载更多,回答才会再加载一部分,所以说如果直接发送一个问题的请求链接,取得的页面是不完整的。还有就是我们通过发送链接下载图片的时候,是一张一张来下的,如果图片数量太多的话,真的是下到你睡完觉它还在下,而且我们用nodejs写的爬虫,却竟然没有用到nodejs最牛逼的异步并发的特性,太浪费了啊。
思路
这次的的爬虫是上次那个的升级版,不过呢,上次那个虽然是简单,但是很适合新手学习啊。这次的爬虫代码在我的github上可以找到=>NodeSpider。
整个爬虫的思路是这样的:在一开始我们通过请求问题的链接抓取到部分页面数据,接下来我们在代码中模拟ajax请求截取剩余页面的数据,当然在这里也是可以通过异步来实现并发的,对于小规模的异步流程控制,可以用这个模块=>eventproxy,但这里我就没有用啦!我们通过分析获取到的页面从中截取出所有图片的链接,再通过异步并发来实现对这些图片的批量下载。
抓取页面初始的数据很简单啊,这里就不做多解释啦
/*获取首屏所有图片链接*/ var getInitUrlList=function(){ request.get("https://www.zhihu.com/question/") .end(function(err,res){ if(err){ console.log(err); }else{ var $=cheerio.load(res.text); var answerList=$(".zm-item-answer"); answerList.map(function(i,answer){ var images=$(answer).find('.zm-item-rich-text img'); images.map(function(i,image){ photos.push($(image).attr("src")); }); }); console.log("已成功抓取"+photos.length+"张图片的链接"); getIAjaxUrlList(); } }); }
模拟ajax请求获取完整页面
接下来就是怎么去模拟点击加载更多时发出的ajax请求了,去知乎看一下吧!
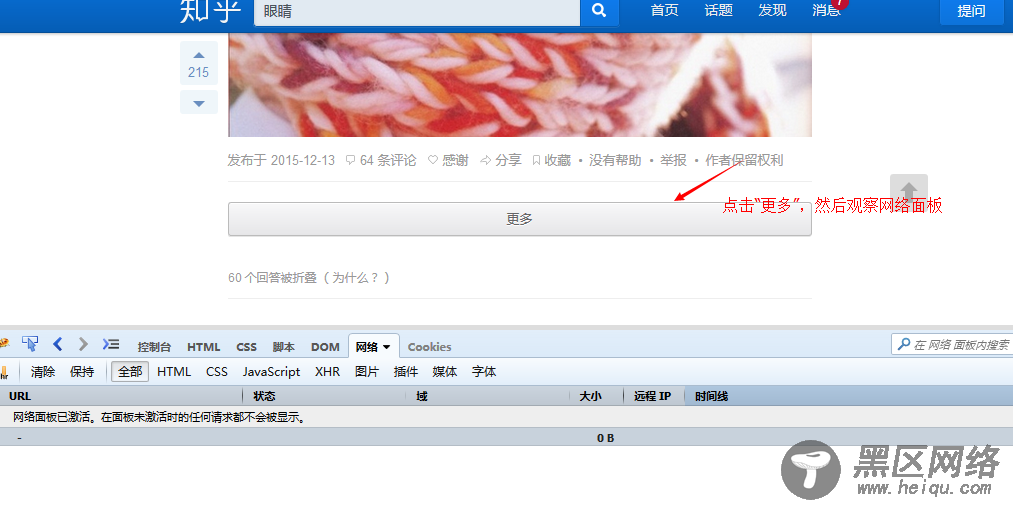
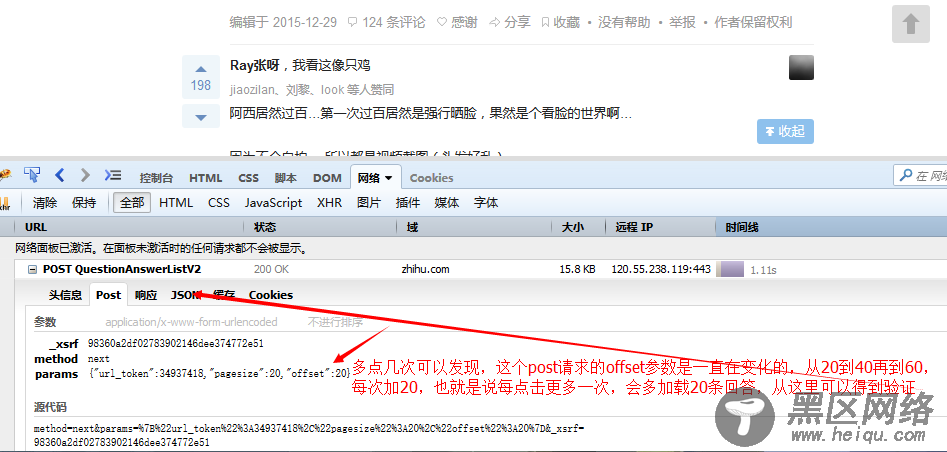
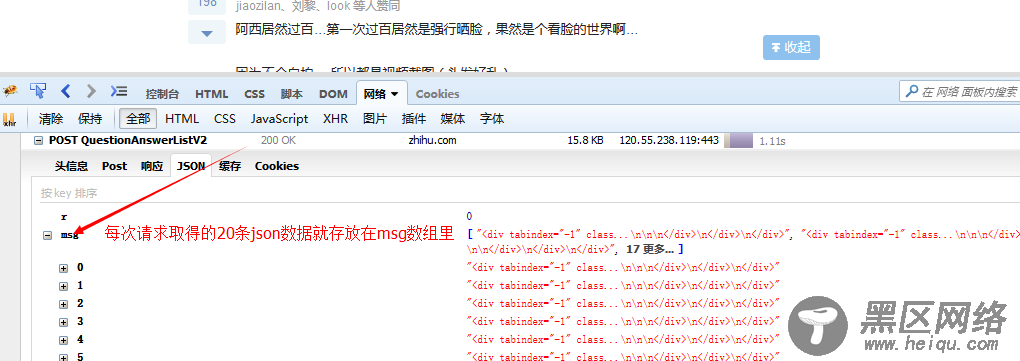
有了这些信息,就可以来模拟发送相同的请求来获得这些数据啦。
/*每隔毫秒模拟发送ajax请求,并获取请求结果中所有的图片链接*/ var getIAjaxUrlList=function(offset){ request.post("https://www.zhihu.com/node/QuestionAnswerListV") .set(config) .send("method=next¶ms=%B%url_token%%A%C%pagesize%%A%C%offset%%A" +offset+ "%D&_xsrf=adfdeee") .end(function(err,res){ if(err){ console.log(err); }else{ var response=JSON.parse(res.text);/*想用json的话对json序列化即可,提交json的话需要对json进行反序列化*/ if(response.msg&&response.msg.length){ var $=cheerio.load(response.msg.join(""));/*把所有的数组元素拼接在一起,以空白符分隔,不要这样join(),它会默认数组元素以逗号分隔*/ var answerList=$(".zm-item-answer"); answerList.map(function(i,answer){ var images=$(answer).find('.zm-item-rich-text img'); images.map(function(i,image){ photos.push($(image).attr("src")); }); }); setTimeout(function(){ offset+=; console.log("已成功抓取"+photos.length+"张图片的链接"); getIAjaxUrlList(offset); },); }else{ console.log("图片链接全部获取完毕,一共有"+photos.length+"条图片链接"); // console.log(photos); return downloadImg(); } } }); }
在代码中post这条请求https://www.zhihu.com/node/QuestionAnswerListV2,把原请求头和请求参数复制下来,作为我们的请求头和请求参数,superagent的set方法可用来设置请求头,send方法可以用来发送请求参数。我们把请求参数中的offset初始为20,每隔一定时间offset再加20,再重新发送请求,这样就相当于我们每隔一定时间发送了一条ajax请求,获取到最新的20条数据,每获取到了数据,我们再对这些数据进行一定的处理,让它们变成一整段的html,便于后面的提取链接处理。 异步并发控制下载图片再获取完了所有的图片链接之后,即判定response.msg为空时,我们就要对这些图片进行下载了,不可能一条一条下对不对,因为如你所看到的,我们的图片足足有
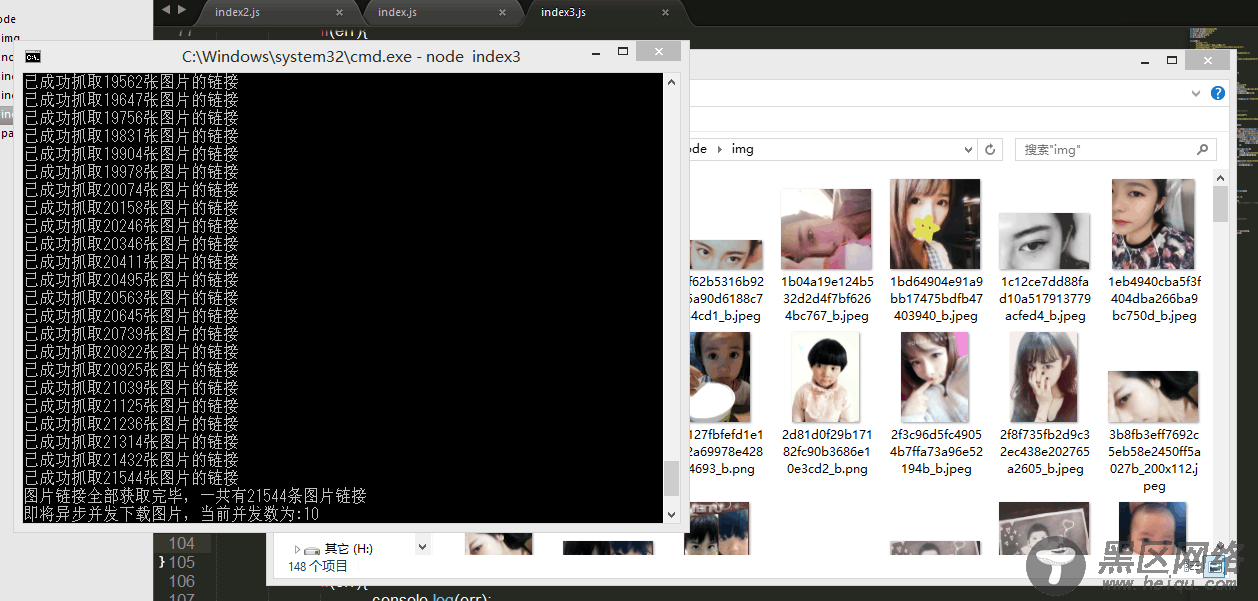
没错,2万多张,不过幸好nodejs拥有神奇的单线程异步特性,我们可以同时对这些图片进行下载。但这个时候问题来了,听说同时发送请求太多的话会被网站封ip哒!这是真的吗?我不知道啊,没试过,因为我也不想去试( ̄ー ̄〃),所以这个时候我们就需要对异步并发数量进行一些控制了。