正则表达式零宽断言:
零宽断言是正则表达式中的难点,所以本章节重点从匹配原理方面进行一下分析。零宽断言还有其他的名称,例如"环视"或者"预搜索"等等,不过这些都不是我们关注的重点。
一.基本概念:
零宽断言正如它的名字一样,是一种零宽度的匹配,它匹配到的内容不会保存到匹配结果中去,最终匹配结果只是一个位置而已。
作用是给指定位置添加一个限定条件,用来规定此位置之前或者之后的字符必须满足限定条件才能使正则中的字表达式匹配成功。
注意:这里所说的子表达式并非只有用小括号括起来的表达式,而是正则表达式中的任意匹配单元。
javascript只支持零宽先行断言,而零宽先行断言又可以分为正向零宽先行断言,和负向零宽先行断言。
代码实例如下:
实例代码一:
var str="abZW863"; var reg=https://www.jb51.net/ab(?=[A-Z])/; console.log(str.match(reg));
在以上代码中,正则表达式的语义是:匹配后面跟随任意一个大写字母的字符串"ab"。最终匹配结果是"ab",因为零宽断言"(?=[A-Z])"并不匹配任何字符,只是用来规定当前位置的后面必须是一个大写字母。
实例代码二:
var str="abZW863"; var reg=https://www.jb51.net/ab(?![A-Z])/; console.log(str.match(reg));
以上代码中,正则表达式的语义是:匹配后面不跟随任意一个大写字母的字符串"ab"。正则表达式没能匹配任何字符,因为在字符串中,ab的后面跟随有大写字母。
二.匹配原理:
上面代码只是用概念的方式介绍了零宽断言是如何匹配的。
下面就以匹配原理的方式分别介绍一下正向零宽断言和负向零宽断言是如何匹配的。
1.正向零宽断言:
代码实例如下:
var str="<div>antzone"; var reg=https://www.jb51.net/^(?=<)<[^>]+>\w+/; console.log(str.match(reg));

匹配过程如下:
首先由正则表达式中的"^"获取控制权,首先由位置0开始进行匹配,它匹配开始位置0,匹配成功,然后控制权转交给"(?=<)",,由于"^"是零宽的,所以"(?=<)"也是从位置0处开始匹配,它要求所在的位置右侧必须是字符"<",位置0的右侧恰好是字符"<",匹配成功,然后控制权转交个"<",由于"(?=<)"也是零宽的,所以它也是从位置0处开始匹配,于是匹配成功,后面的匹配过程就不介绍了。
2.负向零宽断言:
代码实例如下:
var str="abZW863ab88"; var reg=https://www.jb51.net/ab(?![A-Z])/g; console.log(str.match(reg));
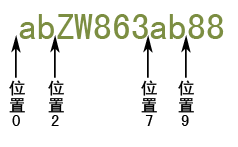
匹配过程如下:
首先由正则表达式的字符"a"获取控制权,从位置0处开始匹配,匹配字符"a"成功,然后控制权转交给"b",从位置1处开始匹配,配字符"b"成功,然后控制权转交给"(?![A-Z])",它从位置2处开始匹配,它要求所在位置的右边不能够是任意一个大写字母,而位置的右边是大写字母"Z",匹配失败,然后控制权又重新交给字符"a",并从位置1处开始尝试,匹配失败,然后控制权再次交给字符"a",从位置2处开始尝试匹配,依然失败,如此往复尝试,直到从位置7处开始尝试匹配成功,然后将控制权转交给"b",然后从位置8处开始尝试匹配,匹配成功,然后再将控制权转交给"(?![A-Z])",它从位置9处开始尝试匹配,它规定它所在的位置右边不能够是大写字母,匹配成功,但是它并不会真正匹配字符,所以最终匹配结果是"ab"。
以下是补充
零宽断言是正则表达式中的一种方法,正则表达式在计算机科学中,是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。
定义解释
零宽断言是正则表达式中的一种方法
正则表达式在计算机科学中,是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。在很多文本编辑器或其他工具里,正则表达式通常被用来检索和/或替换那些符合某个模式的文本内容。许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。
零宽断言