对于正则表达式,相信很多人都知道,但是很多人的第一感觉就是难学,因为看第一眼时,觉得完全没有规律可寻,而且全是一堆各种各样的特殊符号,完全不知所云。
其实只是对正则不了解而以,了解了你就会发现,原来就这样啊正则所用的相关字符其实不多,也不难记,更不难懂,唯一难的就是组合起来之后,可读性比较差,而且不容易理解,本文旨在让大家对正则有一个基本的了解,能看得懂简单的正则表达式,写得出简单的正则表达式,用以满足日常开发中的需求即可。
0\d{2}-\d{8}|0\d{3}-\d{7} 先来一段正则,如果你对正则不了解,是不是完全不知道这一串字符是什么意思?这不要紧文章会详细解释每个字符的含义的。
1.1 什么是正则表达式
正则表达式是一种特殊的字符串模式,用于匹配一组字符串,就好比用模具做产品,而正则就是这个模具,定义一种规则去匹配符合规则的字符。
1.2 常用的正则匹配工具
在线匹配工具:
正则匹配软件 McTracer
用过几个之后还是觉得这个是最好用的,支持将正则导成对应的语言如java C# js等还帮你转义了,Copy直接用就行了很方便,另外支持把正则表达式用法解释,如哪一段是捕获分组,哪段是贪婪匹配等等,总之用起来 So Happy .
二 正则字符简单介绍
2.1 元字符介绍
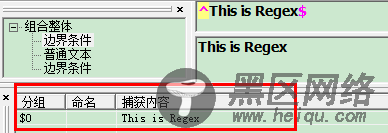
"^" :^会匹配行或者字符串的起始位置,有时还会匹配整个文档的起始位置。
"$" :$会匹配行或字符串的结尾
如图
而且被匹配的字符必须是以This开头有空格也不行,必须以Regex结尾,也不能有空格与其它字符
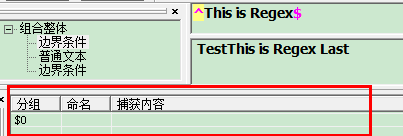
"\b" :不会消耗任何字符只匹配一个位置,常用于匹配单词边界 如 我想从字符串中"This is Regex"匹配单独的单词 "is" 正则就要写成 "\bis\b"
\b 不会匹配is 两边的字符,但它会识别is 两边是否为单词的边界
"\d": 匹配数字,
例如要匹配一个固定格式的电话号码以0开头前4位后7位,如0737-5686123 正则:^0\d\d\d-\d\d\d\d\d\d\d$ 这里只是为了介绍"\d"字符,实际上有更好的写法会在 下面介绍。
"\w":匹配字母,数字,下划线.
例如我要匹配"a2345BCD__TTz" 正则:"\w+" 这里的"+"字符为一个量词指重复的次数,稍后会详细介绍。
"\s":匹配空格
例如字符 "a b c" 正则:"\w\s\w\s\w" 一个字符后跟一个空格,如有字符间有多个空格直接把"\s" 写成 "\s+" 让空格重复
".":匹配除了换行符以外的任何字符
这个算是"\w"的加强版了"\w"不能匹配 空格 如果把字符串加上空格用"\w"就受限了,看下用 "."是如何匹配字符"a23 4 5 B C D__TTz" 正则:".+"
"[abc]": 字符组 匹配包含括号内元素的字符
这个比较简单了只匹配括号内存在的字符,还可以写成[a-z]匹配a至z的所以字母就等于可以用来控制只能输入英文了,
2.2 几种反义
写法很简单改成大写就行了,意思与原来的相反,这里就不举例子了
"\W" 匹配任意不是字母,数字,下划线 的字符
"\S" 匹配任意不是空白符的字符
"\D" 匹配任意非数字的字符
"\B" 匹配不是单词开头或结束的位置
"[^abc]" 匹配除了abc以外的任意字符
2.3 量词
先解释关于量词所涉及到的重要的三个概念
贪婪(贪心) 如"*"字符 贪婪量词会首先匹配整个字符串,尝试匹配时,它会选定尽可能多的内容,如果 失败则回退一个字符,然后再次尝试回退的过程就叫做回溯,它会每次回退一个字符,直到找到匹配的内容或者没有字符可以回退。相比下面两种贪婪量词对资源的消耗是最大的,
懒惰(勉强) 如 "?" 懒惰量词使用另一种方式匹配,它从目标的起始位置开始尝试匹配,每次检查一个字符,并寻找它要匹配的内容,如此循环直到字符结尾处。
占有 如"+" 占有量词会覆盖事个目标字符串,然后尝试寻找匹配内容 ,但它只尝试一次,不会回溯,就好比先抓一把石头,然后从石头中挑出黄金
"*"(贪婪) 重复零次或更多
例如"aaaaaaaa" 匹配字符串中所有的a 正则: "a*" 会出到所有的字符"a"
"+"(懒惰) 重复一次或更多次