
以上就完成了哨兵模式搭建的演示啦,是不是很简单,只要稍微改改配置文件即可完成自动化故障恢复。 到这小伙伴可能会问,原来故障的主服务器恢复了会怎么样? 一个哨兵误判主服务器下线或高并发抗不住怎么办?嘿嘿嘿,接着来搞,接下来边操作边总结;
原故障的主服务器恢复之后只能当小兵原有通讯异常的主服务器如果恢复正常,那它还能恢复原来的地位吗?,还是另有安排呢?这个很好演示,直接将之前shutdown的主服务器重新起来即可;6377启动后查看主从关系信息如下图:
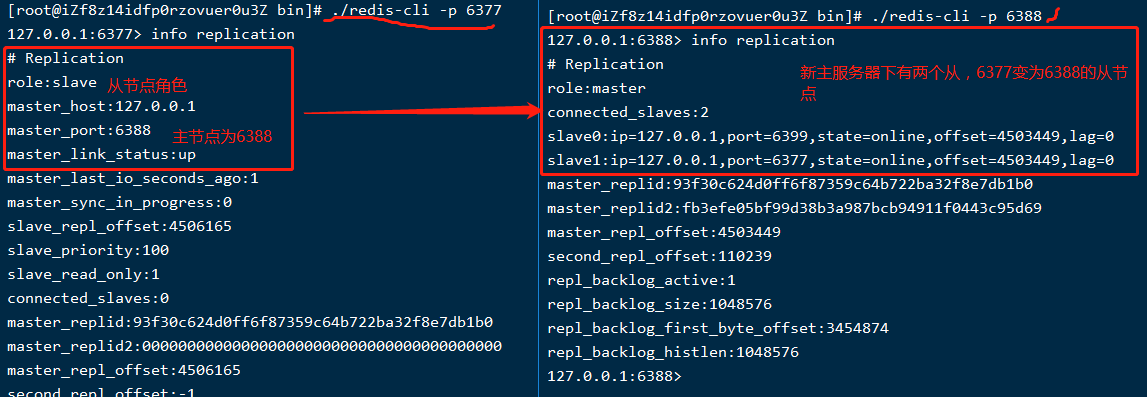
如上图实操验证,原来异常的主服务器(6377)恢复之后就变成新主服务器(6388)的从服务器了(原来再屌,现在也只是小弟,重新再混等机会)。
哨兵集群高可用以上演示就一个哨兵,这样有很明显的两个缺点,如下:
单个哨兵容易导致误判主节点下线,比如主节点正常,只是在与哨兵之间通讯出现短暂异常,如果是单个哨兵,在指定的时间间隔没有通讯就认为主节点下线了,但其实没有;如果哨兵集群,可以询问多个哨兵指定的主节点是否下线,这样就显得更有保障;
哨兵挂了,故障转移就没法继续啦,哨兵集群的话就会选择其他哨兵继续处理;
配置哨兵集群超级简单,就是增加节点即可,哨兵节点会通过发布与订阅功能来自动发现正在监视相同主服务器的其他哨兵 , 这一功能是通过向频道 sentinel:hello 发送信息来实现的。如下图再新增一个哨兵节点,同时增加一个配置文件,由于默认端口为26379,上一个哨兵已经占用,这里在新增的配置文件中指定新哨兵的端口为:26388;
配置文件名为sentinel26388.conf,内容如下:
sentinel monitor mymaster 127.0.0.1 6388 1 port 26388指定配置文件启动第二个哨兵,启动命令为./redis-sentinel ZoeConfig/sentinel26388.conf,效果如下:

到这应该有小伙伴会有疑问:在配置哨兵的时候,只配置监控主服务器,从服务器是怎么知道的?哨兵之间的交流是通过什么形式实现的?
关于从服务器: 哨兵会自动询问主服务器获得对应从服务器的信息,因为从服务器会在连接主服务器的时候把相关信息给主服务器,所以哨兵能通过主服务器拿到从服务器的信息;
关于哨兵之间:哨兵节点会通过发布与订阅功能来自动发现正在监视相同主服务器的其他哨兵 , 这一功能是通过向频道 sentinel:hello 发送信息来实现的;
注:一个哨兵可以同时监控多个主服务器;
哨兵配置文件介绍以上配置只是为了快速实现演示,其实关于哨兵还有其他很多配置,接下来都过一遍:
port:哨兵的端口,默认是26379,可以通过此配置项进行修改;
dir:哨兵的工作目录;
sentinel monitor :指定哨兵监控的主服务器;
master-name:对监控的节点进行命名,方便后续根据名称获取信息;
ip:主节点ip;
redis-port:主节点的端口;
quorum:整数,及设置有几个哨兵统一认为主节点下线为条件,满足这个数量就将主节点标记为客观下线;
例:sentinel monitor mymaster 127.0.0.1 6388 2,意思就是当有两个哨兵都认为监控的mymaster主节点下线了,就将此主节点标记为客观下线;则可以进行下一步故障转移操作了;
sentinel auth-pass :设置主节点和从节点的连接密码,这里只能统一设置,所以主节点和从节点的密码要一样;
sentinel down-after-milliseconds :设置失联时间,单位为毫秒,默认为30秒,如果哨兵在30秒内没有接收到主节点的应答,就认为主节点异常了,并将其标记为主观下线;
sentinel parallel-syncs :故障转移之后,在新的主从关系下,同时有多少个从节点向主节点要求进行数据同步; 默认设置是1,即一个一个同步,这样可以减少主节点同步压力;如果主节点机器性能允许,可以适当增加数量;
sentinel failover-timeout :用于故障转移超时过程判断,默认设置为180000,即3分钟;