Serverless 的诸多优势业内有很多讨论,也有不少文章谈及。我想聚焦到前端开发者身上来说一说,Serverless 能够帮助前端工程师实现真全栈的梦想。可能有人会质疑,为什么你又提出一个真全栈,和之前的全栈有什么区别吗?
我先明确一下真全栈的定义:如何判断一个工程师是真全栈工程师?
当公司有了一堆产品功能需求,招了一个程序员张全占,如果他能从 0 到 1 把需求做成产品,那才叫真全栈。如果张全占完成了前端功能开发、后端开发以及数据库开发,实现了所有的需求功能,并且部署到对应的服务上,就完事了,那么问题也就来了:服务挂了谁来重启?环境稳定性谁来做?日志把磁盘写满了谁来清理?定时任务怎么搞?产品突然火爆了,流量一夜间突然扩大了十几倍的时候(产品经理狂喜中),谁负责扩容?这些问题虽然不是核心业务需求,却是每一个线上产品都必须考虑的东西,否则只能称为功能集合,不能称之为产品。
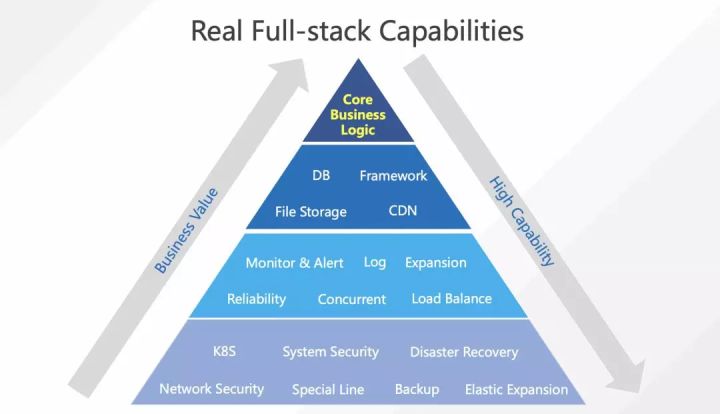
Serverless 架构的出现,将刚才说到的一些非核心业务逻辑,以及运维相关的事情给“屏蔽”了。前端工程师张全占只需关注前台功能、后台功能和数据这些核心的业务逻辑,就可以独立做出产品。例如目前的微信小程序云开发就是 Serverless 式的,开发者完全不用关注底层架构。
Serverless 对前端工程师群体来说是一个机会。让一个前端工程师能够得到独立负责某些产品研发的机会,完成某些产品从需求到上线的从 0 到 1 的机会,一个回归到互联网研发工程师角色的机会。我希望所有的前端工程师都有机会成为 Serverless 工程师,有机会独立负责研发整个产品。
采用 Serverless 的准备总体上来说,采用 Serverless 不需要工程师大量的学习和准备过程。
Serverless 本身就是在现有的架构中做减法,减去那些服务器的管理和配置工作。当然在具体落地的时候,还是有一些准备工作要做:
首先是明确目标,开发者在了解 Serverless 之后,应该去思考对于自身业务和开发架构,采用 Serverless 是为了解决什么问题?想取得哪方面的提升?没有一种技术是为了用而用,都是针对具体场景解决具体问题。这是第一个需要搞明白的。
明确了目标之后,接着是 Serverless 模式下架构的一些设计工作。与传统的开发模式一样,系统设计的工作量是根据业务的复杂程度决定的。对于复杂业务逻辑来说,在开发之前需要明确有多少个云函数,每个云函数的输入输出定义、采用哪些 BaaS 后端服务,都需要提前设计规划好。
特别要说明的是,这些设计和非 Serverless 并没有什么本质上的不同,Serverless 云函数也不是神秘莫测的。简单理解,它所提供的就是一个语言的 Runtime。在非 Serverless 架构下如何执行的代码,Serverless 架构下还是那样执行。如果业务是基于 Express 或者 koa 这类应用框架,那么 Serverless 云函数下,还是直接使用这些框架即可。

最后是一些实施上的准备,以腾讯云函数为例,只要是写过代码的,花小半天时间阅读一些基础文档、教程,或者是跟着 Demo 走一遍,就可以立刻开始写代码,几乎没有什么门槛和不同。要敲黑板强调的是,别忘记了工程化和 CI/CD 方面的考虑,尤其是和现有研发流程的结合。这块有一些小小的工作量,毕竟是开发模式的升级,但基于云函数提供的 CLI 和 SDK 都很容易实现。
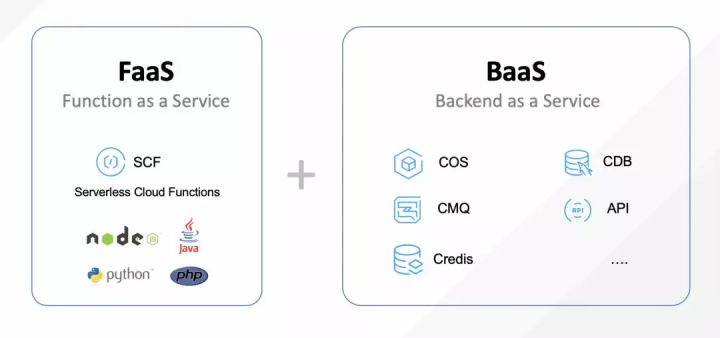
Serverless 和云函数的关系Serverless 架构由两部分构成,分别是 FaaS(Functions as a Service)和 BasS(Backend as a Sevice)。其中 FaaS 就是指云函数,它是一种新的算力组织和提供方式,它让用户不再需要关心服务器的管理和配置,只用专注于核心业务逻辑业务代码的编写。BaaS 指的是一些服务化的后端功能,包括数据库 / 对象存储、账户权鉴、消息队列、社交媒体整合和 AI 能力等,这些服务和接口在 FaaS 层使用相应的 SDK 或 API 来连接和调用。