
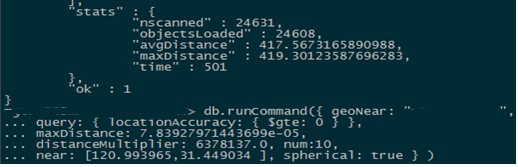
部分大客户在使用MongoDB的geoNear功能查找附近的对象时,经常会发生慢查询较多的问题,早高峰压力是低谷时段的10-20倍,坐标不均匀的情况慢查询严重,濒临雪崩。初步分析发现,这些查询扫描了过多的点集。 如下图,查找500米范围内,距离最近的10条记录,花费了500ms,扫描了24000+的记录。类似的慢查询占据了高峰期5%左右的查询量
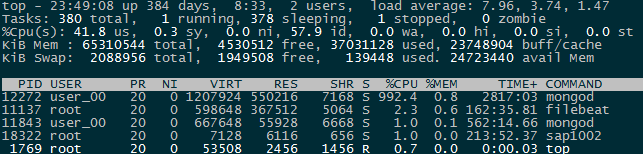
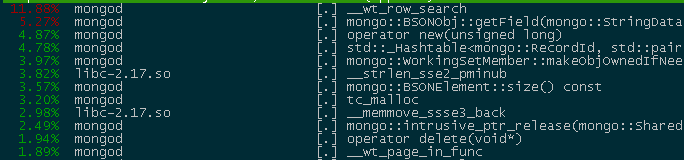
测试环境复现与定位 排查数据库的性能问题,主要从锁等待,IO等待,CPU消耗三封面分析。上面的截图扫描了过多的记录,直觉上是CPU或者IO消耗性的瓶颈。为了严谨起见,我们在测试环境复现后,发现慢日志中无明显的timeAcquiringMicroseconds项排除了MongoDB执行层面的锁竞争问题,并选用较大内存的机器使得数据常驻内存,发现上述用例依旧需要200ms以上的执行时间。10核的CPU资源针对截图中的case,只能支持50QPS。
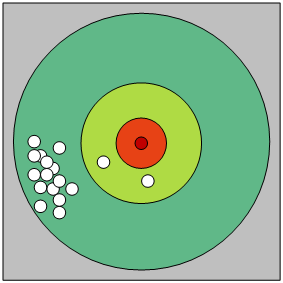
为何扫描集如此大 上面我们说过,MongoDB搜索距离最近的点的过程是一个环形扩张的过程,如果内环满足条件的点不够多,每次的扩张半径都会倍增。因此在遇到内环点稀少,外环有密集点的场景时,容易陷入BadCase。如下图,我们希望找到离中心点距离最近的三个点。由于圆环扩张太快,外环做了很多的无用扫描与排序。 这样的用例很符合实际场景,早高峰车辆聚集在地铁周围,你从家出发一路向地铁,边走边找,共享单车软件上动态搜索距你最近的10辆车,附近只有三两辆,于是扩大搜索半径到地铁周围,将地铁周围的所有几千辆车都扫描计算一遍,返回距离你最近的其余的七八辆
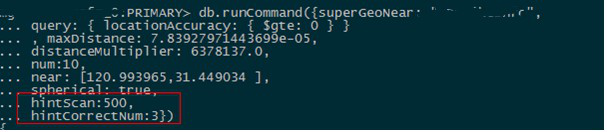
问题我们已经知道了,我们对此的优化方式是控制每一圈的搜索量,为此我们为geoNear命令增加了两个参数,将其传入NearStage中。hintCorrectNum可以控制结果品质的下限,返回的前N个一定是最靠近中心点的N个点。hintScan用以控制扫描集的大小的上限。
hintScan: 已经扫描的点集大小大于hintScan后,做模糊处理。 hintCorrectNum:已经返回的结果数大于hintCorrectNum后,做模糊处理。
该优化本质上是通过牺牲品质来尽快返回结果。对于国内大部分LBS服务来说,完全的严格最近并不是必要的。且可以通过控制参数获得严格最近的效果。在搜索过程中,密集的点落到一个环内,本身距离相差也不会不大。该优化在上线后,将部分大客户的MongoDB性能上限从单机1000QPS提升了10倍到10000QPS以上。
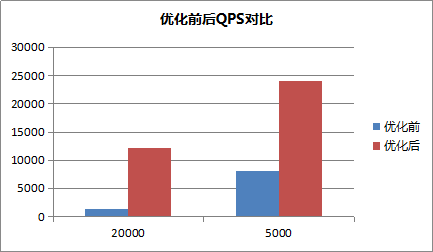
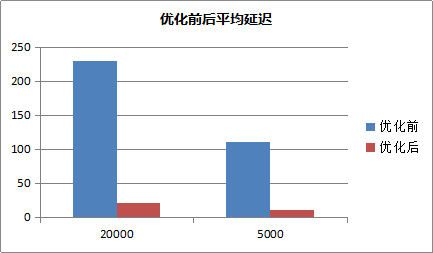
Redis3.2也加入了地理位置查询的功能,我们也将开源Redis和云数据库MongoDB进行对比。 Redis使用方式:GEORADIUS appname 120.993965 31.449034 500 m count 30 asc。在密集数据集场景下,使用腾讯云MongoDB和开源的Redis进行了性能对比。下图是在密集数据集上,在24核CPU机器上,MongoDB单实例与Redis单实例的测试对比。需要注意的是Redis本身是单线程的内存缓存数据库。MongoDB是多线程的高可用持久化的数据库,两者的使用场景有较大不同。
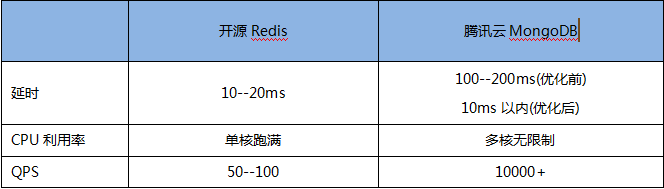
MongoDB原生的geoNear接口是国内各大LBS应用的主流选择。原生MongoDB在点集稠密的情况下,geoNear接口效率会急剧下降,单机甚至不到1000QPS。腾讯云MongoDB团队对此进行了持续的优化,在不影响效果的前提下,geoNear的效率有10倍以上的提升,为我们的客户如摩拜提供了强力的支持,同时相比Redis3.2也有较大的性能优势。