那如果DB的 QPS(Query Per Second)上限是1000,此时这个线程数又该设置为多大呢?

同样,这是没有考虑 CPU 数目,接下来就又是细节调优的阶段了
因为一次请求不仅仅包括 CPU 和 I/O操作,具体的调优过程还要考虑内存资源,网络等具体内容
增加 CPU 核数一定能解决问题吗?看到这,有些同学可能会认为,即便我算出了理论线程数,但实际CPU核数不够,会带来线程上下文切换的开销,所以下一步就需要增加 CPU 核数,那我们盲目的增加 CPU 核数就一定能解决问题吗?
在讲互斥锁的内容是,我故意遗留了一个知识:
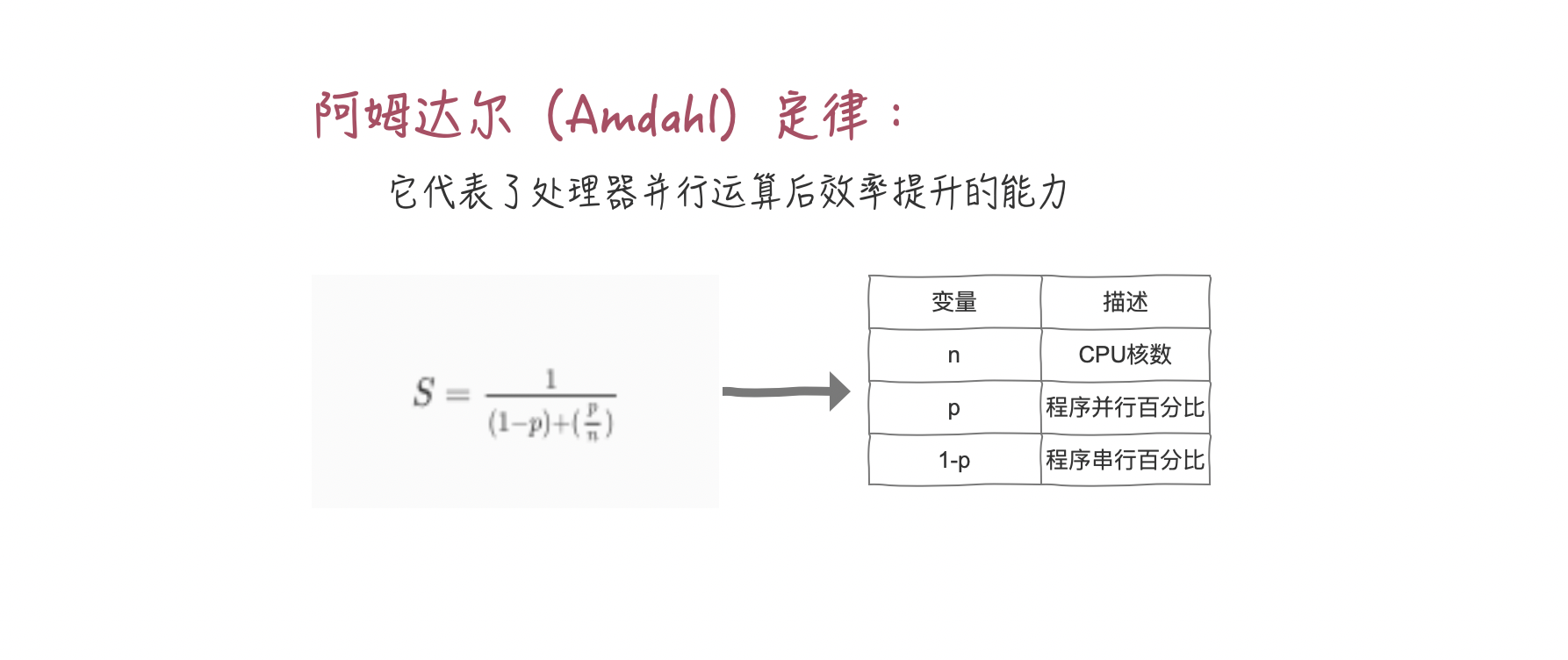
怎么理解这个公式呢?

这个结论告诉我们,假如我们的串行率是 5%,那么我们无论采用什么技术,最高也就只能提高 20 倍的性能。
如何简单粗暴的理解串行百分比(其实都可以通过工具得出这个结果的)呢?来看个小 Tips:
Tips: 临界区都是串行的,非临界区都是并行的,用单线程执行临界区的时间/用单线程执行(临界区+非临界区)的时间就是串行百分比
现在你应该理解我在讲解 synchronized 关键字时所说的:
最小化临界区范围,因为临界区的大小往往就是瓶颈问题的所在,不要像乱用try catch那样一锅端
总结多线程不一定就比但线程高效,比如大名鼎鼎的 Redis (后面会分析),因为它是基于内存操作,这种情况下,单线程可以很高效的利用CPU。而多线程的使用场景一般时存在相当比例的I/O或网络操作
另外,结合小学数学题,我们已经了解了如何从定性到定量的分析的过程,在开始没有任何数据之前,我们可以使用上文提到的经验值作为一个伪标准,其次就是结合实际来逐步的调优(综合 CPU,内存,硬盘读写速度,网络状况等)了
最后,盲目的增加 CPU 核数也不一定能解决我们的问题,这就要求我们严格的编写并发程序代码了
灵魂追问我们已经知道创建多少个线程合适了,为什么还要搞一个线程池出来?
创建一个线程都要做哪些事情?为什么说频繁的创建线程开销很大?
多线程通常要注意共享变量问题,为什么局部变量就没有线程安全问题呢?
......
下一篇文章,我们就来说说,你熟悉又陌生的线程池问题
参考感谢前辈们总结的精华,自己所写的并发系列好多都参考了以下资料
Java 并发编程实战
Java 并发编程之美
码出高效
Java 并发编程的艺术
......
我这面也在逐步总结常见的并发面试问题(总结ing......)答案整理好后会通知大家,请持续关注
同时,这里也整理了一点 Java 硬核资料,有需要的就公众号回复【资料】/【666】吧

8种优化if-else代码的方案请拿走
volatile和synchronized到底啥区别?多图文讲解告诉你
后端的我要学Node.js了,你敢信
漂亮又好用的Redis可视化客户端汇总,总有一款你需要的
一口气说出 9种 分布式ID生成方式,面试官有点懵了