
tensorflow_face.py 这部分代码第一次运行会给每一个人创建一个标签,,获得标签集,,然后和训练集一同训练,,,而第二次运行就是识别,,,
import os import logging as log import matplotlib.pyplot as plt import common import numpy as np from tensorflow.examples.tutorials.mnist import input_data import tensorflow as tf import cv2 # import convert as myconv import tensorflow_face_conv as myconv import dlib import random from sklearn.model_selection import train_test_split import time import sys # rm import shutil def createdir(*args): # 创建一个文件夹 ''' create dir''' for item in args: if not os.path.exists(item): os.makedirs(item) IMGSIZE = 64 SIZE = 64 rootpath = 'G:\\DIP\\mine' def getpaddingSize(shape): # 将相片两侧填充为正方形 ''' get size to make image to be a square rect ''' h, w = shape longest = max(h, w) result = (np.array([longest]*4, int) - np.array([h, h, w, w], int)) // 2 return result.tolist() def dealwithimage(img, h=64, w=64): # 裁剪出人脸的图片 ''' dealwithimage ''' #img = cv2.imread(imgpath) top, bottom, left, right = getpaddingSize(img.shape[0:2]) img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=[0, 0, 0]) img = cv2.resize(img, (h, w)) return img def relight(imgsrc, alpha=1, bias=0): # 更改图片为二值图 '''relight''' imgsrc = imgsrc.astype(float) imgsrc = imgsrc * alpha + bias imgsrc[imgsrc < 0] = 0 imgsrc[imgsrc > 255] = 255 imgsrc = imgsrc.astype(np.uint8) return imgsrc def getfilesinpath(filedir): # 得到一个文件夹下的所有文件 ''' get all file from file directory''' for (path, dirnames, filenames) in os.walk(filedir): for filename in filenames: if filename.endswith('.jpg'): yield os.path.join(path, filename) for diritem in dirnames: getfilesinpath(os.path.join(path, diritem)) # 递归调用得到改文件夹下的文件 def readimage(pairpathlabel): # 得到一个文件夹下的照片文件名和标记labels, 返回一个列表 '''read image to list''' imgs = [] labels = [] for filepath, label in pairpathlabel: for fileitem in getfilesinpath(filepath): img = cv2.imread(fileitem) imgs.append(img) labels.append(label) return np.array(imgs), np.array(labels) def onehot(numlist): # 用于得到一个人的标签 ''' get one hot return host matrix is len * max+1 demensions''' b = np.zeros([len(numlist), max(numlist)+1]) b[np.arange(len(numlist)), numlist] = 1 return b.tolist() def getfileandlabel(filedir): # 用字典保存一个人名的照片和对应的labels ''' get path and host paire and class index to name''' dictdir = dict([[name, os.path.join(filedir, name)] \ for name in os.listdir(filedir) if os.path.isdir(os.path.join(filedir, name))]) #for (path, dirnames, _) in os.walk(filedir) for dirname in dirnames]) dirnamelist, dirpathlist = dictdir.keys(), dictdir.values() indexlist = list(range(len(dirnamelist))) return list(zip(dirpathlist, onehot(indexlist))), dict(zip(indexlist, dirnamelist)) def main(_): ''' main ''' ''' 人脸识别项目主main函数 + 在第一次运行该文件时,会将上一次拍照保存的多个人的照片数据进行处理,卷积、训练等得到一个适合的模型 + 在第二次运行该文件时,会打开摄像头获取一个照片,然后根据上一步得到的模型处理后分类(识别)出照片上出现的人脸是之前录入的所有人中哪一个 + 目前无法判断其他未录入人的人脸,即others ''' #shutil.rmtree('./checkpoint') savepath = './checkpoint/face.ckpt' # 记录下模型的索引路径 isneedtrain = False # 不存在时认为时第一次运行,即进行卷积训练 if os.path.exists(savepath+'.meta') is False: isneedtrain = True # 根据录入保存的照片得到一个label和字典的路径的列表 pathlabelpair, indextoname = getfileandlabel(rootpath + '\\image\\trainfaces') print(indextoname) sys.stdout.flush() print(pathlabelpair) sys.stdout.flush() # 得到训练集、测试集的照片和labels的列表 train_x, train_y = readimage(pathlabelpair) # 将数据集归一化 ??? train_x = train_x.astype(np.float32) / 255.0 #### log.debug('len of train_x : %s', train_x.shape) if isneedtrain: # first generate all face # 调用另一文件进行卷积训练模型 myconv.train(train_x, train_y, savepath) #### # log.debug('training is over, please run again') else: # second recognize faces # 调用下面的函数进行实时识别 testfromcamera(train_x, train_y, savepath) #print(np.column_stack((out, argmax))) def testfromcamera(train_x, train_y, chkpoint): # 打开默认摄像头 camera = cv2.VideoCapture(0) #haar = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') pathlabelpair, indextoname = getfileandlabel(rootpath + '\\image\\trainfaces') # 得到预测值 output = myconv.cnnLayer(len(pathlabelpair),False) predict = output # 得到dlib的人脸检测器 detector = dlib.get_frontal_face_detector() # 加载模型 saver = tf.train.Saver() with tf.Session() as sess: #sess.run(tf.global_variables_initializer()) saver.restore(sess, chkpoint) n = 1 while 1: if (n <= 20000): print('It`s processing %s image.' % n) sys.stdout.flush() # 间隔0.2s time.sleep(0.2) # 读帧 success, img = camera.read() # 得到灰度图 gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 使用detector进行人脸检测 faces = detector(gray_img, 1) #faces = haar.detectMultiScale(gray_img, 1.3, 5) for i, d in enumerate(faces): x1 = d.top() if d.top() > 0 else 0 y1 = d.bottom() if d.bottom() > 0 else 0 x2 = d.left() if d.left() > 0 else 0 y2 = d.right() if d.right() > 0 else 0 face = img[x1:y1,x2:y2] face = cv2.resize(face, (IMGSIZE, IMGSIZE)) #could deal with face to train test_x = np.array([face]) test_x = test_x.astype(np.float32) / 255.0 res = sess.run([predict, tf.argmax(output, 1)],\ feed_dict={myconv.x: test_x,\ myconv.keep_prob_5:1.0, myconv.keep_prob_75: 1.0}) print(res, indextoname[res[1][0]], res[0][0][res[1][0]]) sys.stdout.flush() # 得到一组随机的颜色值 r = random.randint(0, 255) g = random.randint(0, 255) b = random.randint(0, 255) # 绘制检测到的人脸的方框 cv2.rectangle(img, (x2,x1),(y2,y1), (r, g, b),3) # if res[0][0][res[1][0]] >= 500: # cv2.putText(img, 'others', (x1, y1 + 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (col, col, col), 2) #显示名字 # else: # cv2.putText(img, indextoname[res[1][0]], (x1, y1 - 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (col, col, col), 2) #显示名字 cv2.putText(img, indextoname[res[1][0]], (x2 + 25, y1 + 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (r, g, b), 2) #显示名字 n+=1 cv2.imshow('img', img) key = cv2.waitKey(30) & 0xff if key == 27: break else: break camera.release() cv2.destroyAllWindows() if __name__ == '__main__': # first generate all face main(0) #onehot([1, 3, 9]) #print(getfileandlabel('./image/trainimages')) #generateface([['./image/trainimages', './image/trainfaces']]) 总结最后的模型的准确度还行,,但是不能识别未录入者,,它会认为是与已录入者最接近的人,,,
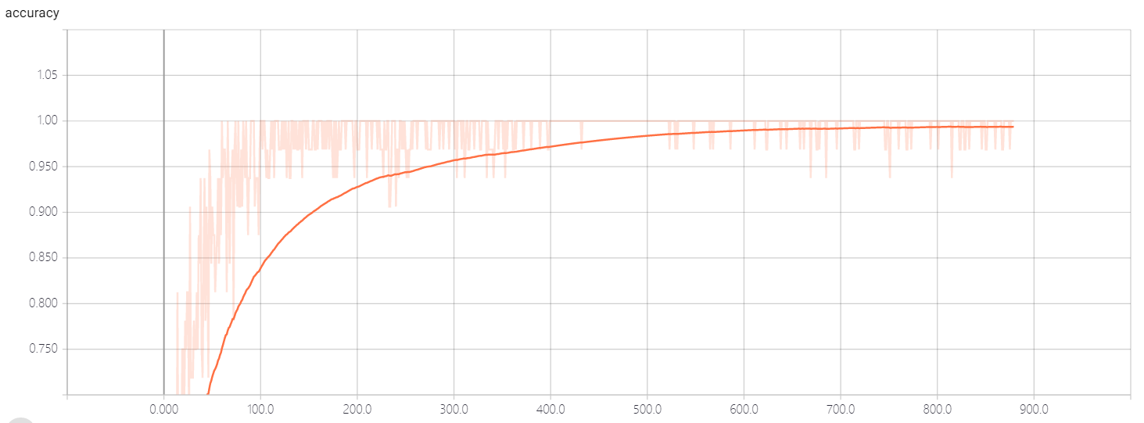
acc:
loss:
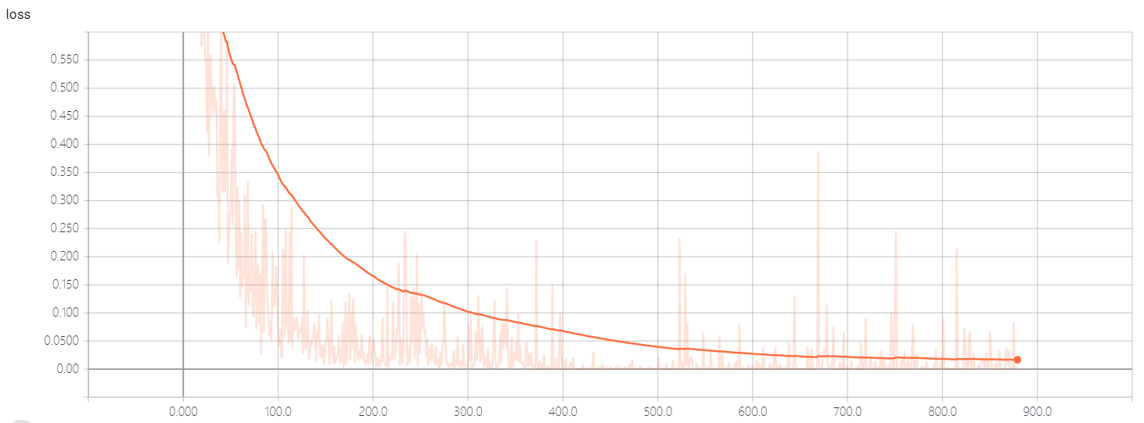
这个数据是通过tensorboard生成的,,