
让我们来看看这个例子的样子System.IO.Pipelines:
async Task ProcessLinesAsync(Socket socket) { var pipe = new Pipe(); Task writing = FillPipeAsync(socket, pipe.Writer); Task reading = ReadPipeAsync(pipe.Reader); return Task.WhenAll(reading, writing); } async Task FillPipeAsync(Socket socket, PipeWriter writer) { const int minimumBufferSize = 512; while (true) { // 从PipeWriter至少分配512字节 Memory<byte> memory = writer.GetMemory(minimumBufferSize); try { int bytesRead = await socket.ReceiveAsync(memory, SocketFlags.None); if (bytesRead == 0) { break; } // 告诉PipeWriter从套接字读取了多少 writer.Advance(bytesRead); } catch (Exception ex) { LogError(ex); break; } // 标记数据可用,让PipeReader读取 FlushResult result = await writer.FlushAsync(); if (result.IsCompleted) { break; } } // 告诉PipeReader没有更多的数据 writer.Complete(); } async Task ReadPipeAsync(PipeReader reader) { while (true) { ReadResult result = await reader.ReadAsync(); ReadOnlySequence<byte> buffer = result.Buffer; SequencePosition? position = null; do { // 在缓冲数据中查找找一个行末尾 position = buffer.PositionOf((byte)'\n'); if (position != null) { // 处理这一行 ProcessLine(buffer.Slice(0, position.Value)); // 跳过 这一行+\n (basically position 主要位置?) buffer = buffer.Slice(buffer.GetPosition(1, position.Value)); } } while (position != null); // 告诉PipeReader我们以及处理多少缓冲 reader.AdvanceTo(buffer.Start, buffer.End); // 如果没有更多的数据,停止都去 if (result.IsCompleted) { break; } } // 将PipeReader标记为完成 reader.Complete(); }我们的行读取器的pipelines版本有2个循环:
FillPipeAsync从Socket读取并写入PipeWriter。
ReadPipeAsync从PipeReader中读取并解析传入的行。
与原始示例不同,在任何地方都没有分配显式缓冲区。这是管道的核心功能之一。所有缓冲区管理都委托给PipeReader/PipeWriter实现。
这使得使用代码更容易专注于业务逻辑而不是复杂的缓冲区管理。
在第一个循环中,我们首先调用PipeWriter.GetMemory(int)从底层编写器获取一些内存; 然后我们调用PipeWriter.Advance(int)告诉PipeWriter我们实际写入缓冲区的数据量。然后我们调用PipeWriter.FlushAsync()来提供数据给PipeReader。
在第二个循环中,我们正在使用PipeWriter最终来自的缓冲区Socket。当调用PipeReader.ReadAsync()返回时,我们得到一个ReadResult包含2条重要信息,包括以ReadOnlySequence<byte>形式读取的数据和bool IsCompleted,让reader知道writer是否写完(EOF)。在找到行尾(EOL)分隔符并解析该行之后,我们将缓冲区切片以跳过我们已经处理过的内容,然后我们调用PipeReader.AdvanceTo告诉PipeReader我们消耗了多少数据。
在每个循环结束时,我们完成了reader和writer。这允许底层Pipe释放它分配的所有内存。
System.IO.Pipelines除了处理内存管理之外,其他核心管道功能还包括能够在Pipe不实际消耗数据的情况下查看数据。
PipeReader有两个核心API ReadAsync和AdvanceTo。ReadAsync获取Pipe数据,AdvanceTo告诉PipeReader不再需要这些缓冲区,以便可以丢弃它们(例如返回到底层缓冲池)。
这是一个http解析器的示例,它在接收Pipe到有效起始行之前读取部分数据缓冲区数据。
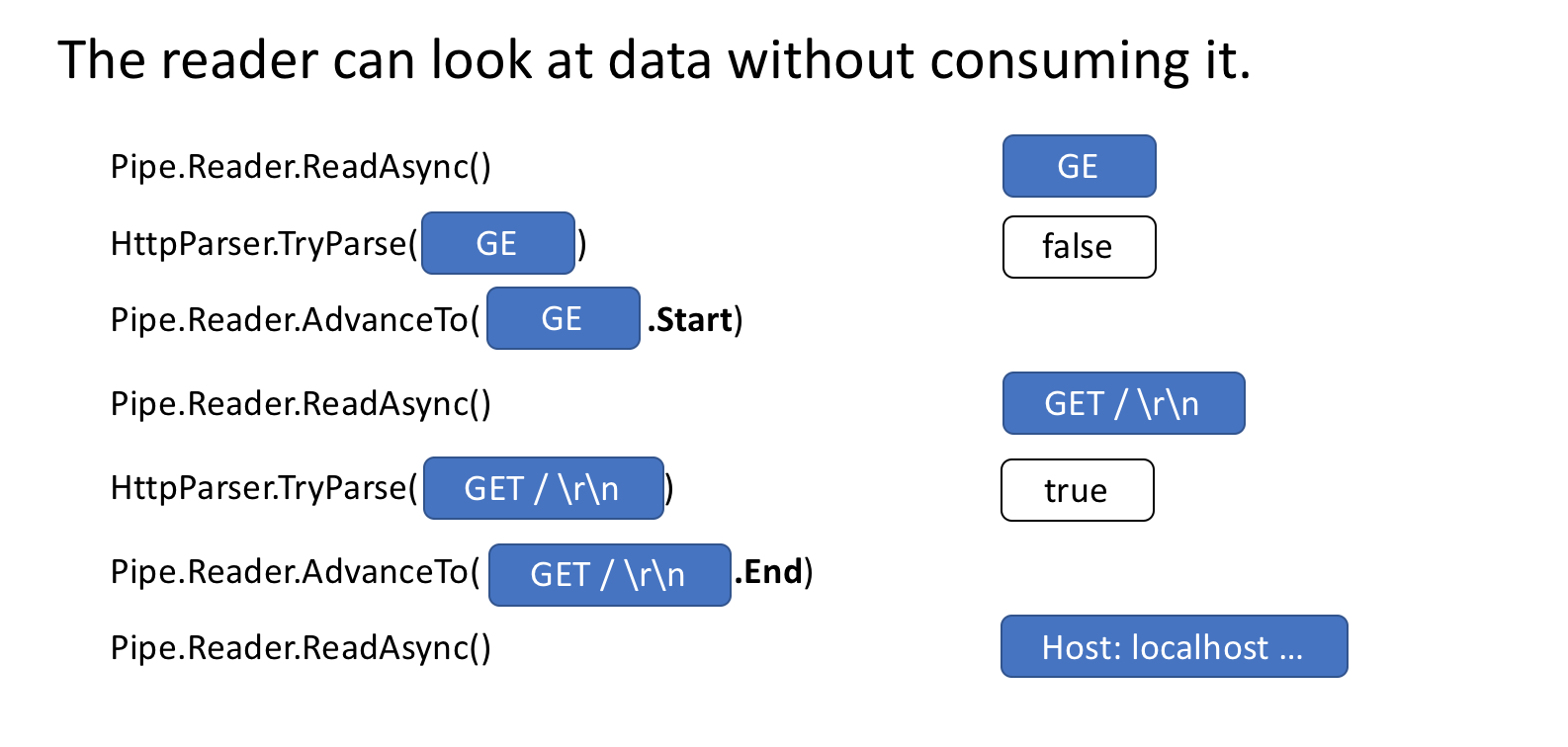
该Pipe实现存储了在PipeWriter和PipeReader之间传递的缓冲区的链接列表。PipeReader.ReadAsync暴露一个ReadOnlySequence<T>新的BCL类型,它表示一个或多个ReadOnlyMemory<T>段的视图,类似于Span<T>和Memory<T>提供数组和字符串的视图。

该Pipe内部维护指向reader和writer可以分配或更新它们的数据集合,。SequencePosition表示缓冲区链表中的单个点,可用于有效地对ReadOnlySequence<T>进行切片。
这段实在翻译困难,给出原文
The Pipe internally maintains pointers to where the reader and writer are in the overall set of allocated data and updates them as data is written or read. The SequencePosition represents a single point in the linked list of buffers and can be used to efficiently slice the ReadOnlySequence
由于ReadOnlySequence<T>可以支持一个或多个段,因此高性能处理逻辑通常基于单个或多个段来分割快速和慢速路径(fast and slow paths?)。
例如,这是一个将ASCII ReadOnlySequence<byte>转换为string以下内容的例程:
string GetAsciiString(ReadOnlySequence<byte> buffer) { if (buffer.IsSingleSegment) { return Encoding.ASCII.GetString(buffer.First.Span); } return string.Create((int)buffer.Length, buffer, (span, sequence) => { foreach (var segment in sequence) { Encoding.ASCII.GetChars(segment.Span, span); span = span.Slice(segment.Length); } }); } 背压和流量控制