
这个是由编排的目标对象的复杂度决定的:创建一个RDS数据库,就是会比单独创建一台VM,需要有更多的控制参数。于是一种新的模板语法,相当于一种新的编程语言。写过代码的你肯定知道,想要快速的编码,当然需要合适的IDE支撑。也正因此,一些有实力的编排系统就会推出相应的图形化设计器,其定位就是配套的模板写作IDE。
比如AWS,阿里和华为都提供了在线的模板编辑IDE。设计器好坏的评价标准就是能否支撑方便的写作模板。
5 如何实现云上编排系统一个编排系统的核心就是一个工作流引擎,负责分析各个步骤间的依赖关系,并按照DAG(有向无环图)模型来控制这些流程的执行顺序。而云上的编排,更加的具化,就是按依赖顺序创建各个云服务。
算法层面,我们可以称每个云服务为元素。创建各种云服务的过程,就是按顺序创建各个元素的过程。
5.1有向无环图DAG有向无环图(Directed Acyclic Graph, DAG), 是有向图的一种,字面意思的理解就是图中没有环。常常被用来表示事件之间的依赖关系,用于管理任务之间的调度。
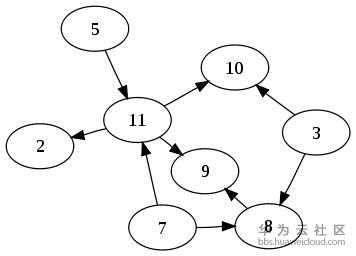
图:一个有向无环图的例子
其中所有节点的拓扑排序是有向无环图中经常需要使用到的算法,我们的系统原型也是按照此理论基础进行实现的。就是把所有元素按照DAG依赖关系确定好谁先谁后的顺序,具体算法大家可以在网上或者资料中搜索获得,这里就不细介绍了。排好序后,接下里的实现就是先完成底层的元素,再完成上层元素,直到所有元素都初始化完毕。以上就是我们的编排系统模型的理论参照。
5.2 编排系统原型在这里我们假设有一个系统的初始化流程如下:
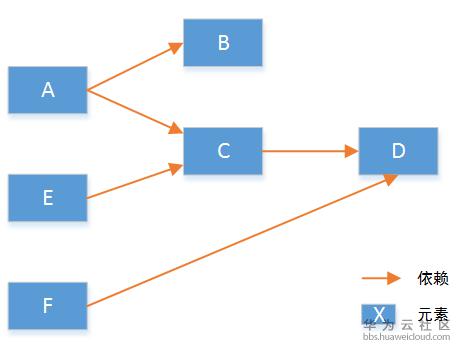
要实现所有元素按照设定好的顺序创建,我们遵从两个要点:(1)默认并行执行。(2)无依赖的先执行。具体算法实现上,我们首先将元素启动顺序分解为有向图,并遍历计算得到每个节点的依赖数。如下:
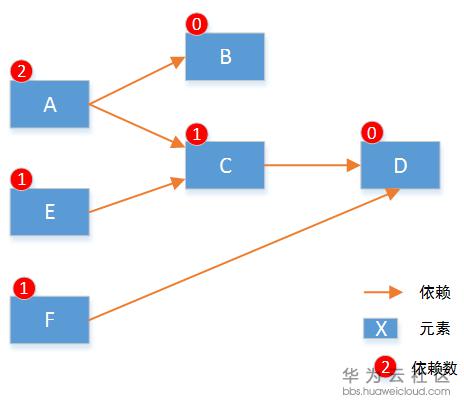
注:依赖只需要计算临近的节点就可以。
遵循之前的两个原则:那么元素B和元素D的依赖数是0,所以这两个元素可以先执行初始化。同时B和D之间无关,可以并行执行。
在任意一个元素执行完之后,所有依赖这些节点的依赖数减一,重新得到所有节点的依赖数:
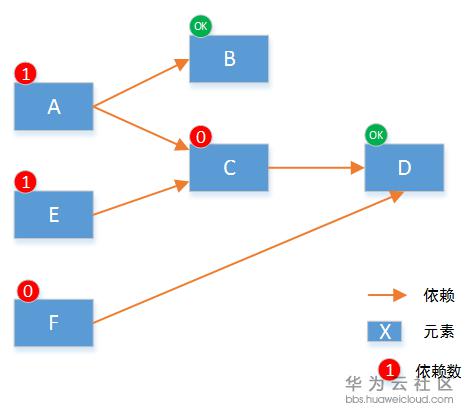
本次可以执行的元素就是C和F,因为它们的依赖数为0。在这两个元素执行完后,将依赖他们的元素的依赖数减一,重新得到所有节点依赖数:
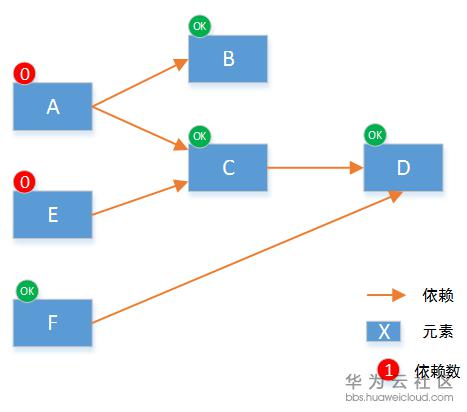
按照上述的逻辑递归执行,直到所有的元素都被执行完,整个工作流就完成了。它保证整个流程是按顺序用时最短的。从工作流实现原理可知,编排的能力强弱并不强调流程控制,而是编排元素,及编排语法的丰富程度。好的编排系统,可以快速的完成新元素的驱动开发,从而提供新服务的编排能力。
5.3 元素间信息传递如果每个元素初始化,都得记录着其他元素的信息,这种在实现上元素间就很耦合。为了保持每个元素在执行时候的独立性(即当前元素在初始化时,不用去了解其他元素的信息)。主体框架需要保持一个全局信息,然后在初始化一个元素的时候,把这个元素需要的信息告诉它就行。它自己完全不知道还有哪些其他元素,反正它自己需要的信息都有了。