
它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
这样实现简单,运行高效,不过其缺陷也显而易见,这种复制回收算法的代价是将可用内存缩小为了原来的一半,空间浪费较多。
标记-复制算法的执行过程如图所示。
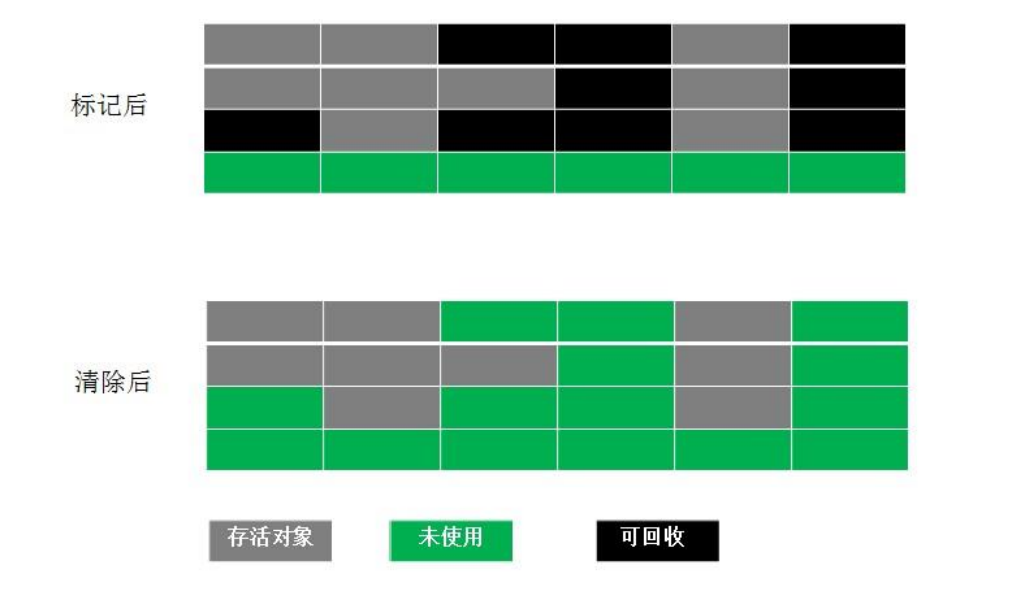
标记-整理算法的标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向内存空间一端移动,然后直接清理掉边界以外的内存。
“标记-整理”算法的示意图如图:

当前商业虚拟机的垃圾收集器,大多数都遵循了“分代收集”(Generational Collection)的理论进行设计,分代收集名为理论,实质是一套符合大多数程序运行实际情况的经验法则,它建立在两个分代假说之上:
1)弱分代假说(Weak Generational Hypothesis):绝大多数对象都是朝生夕灭的。
2)强分代假说(Strong Generational Hypothesis):熬过越多次垃圾收集过程的对象就越难以消亡。
基于这两个假说,收集器应该将Java堆划分出不同的区域,然后将回收对象依据其年龄(年龄即对象熬过垃圾收集过程的次数)分配到不同的区域之中存储。
设计者一般至少会把Java堆划分为新生代 (Young Generation)和老年代(Old Generation)两个区域。顾名思义,在新生代中,每次垃圾收集
时都发现有大批对象死去,而每次回收后存活的少量对象,将会逐步晋升到老年代中存放。
基于这种分代,老年代和新生代具备不同的特点,可以采用不同的垃圾收集算法。
⽐如在新⽣代中,每次收集都会有⼤量对象死去,所以可以选择标记-复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。
⽽⽼年代的对象存活⼏率是⽐较⾼的,⽽且没有额外的空间对它进⾏分配担保,所以必须选择标记-清除或标记-整理算法进⾏垃圾收集。
因为有了分代收集理论,所以就有了了“Minor GC(新⽣代GC)”、“Major GC(⽼年代GC)”、“Full GC(全局GC)”这样的回收类型的划分
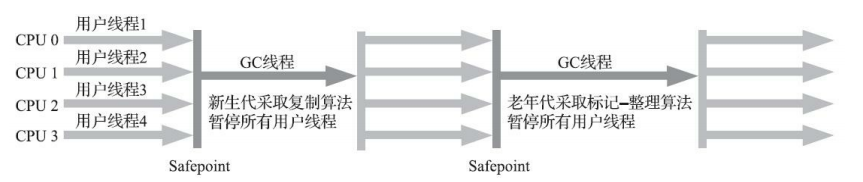
4.4、垃圾收集器 4.4.1、Serial收集器Serial收集器是最基础、历史最悠久的收集器,曾经(在JDK 1.3.1之前)是HotSpot虚拟机新生代收集器的唯一选择。这个收集器是一个单线程工作的收集器,但它的“单线 程”的意义并不仅仅是说明它只会使用一个处理器或一条收集线程去完成垃圾收集工作,更重要的是强调在它进行垃圾收集时,必须暂停其他所有工作线程,直到它收集结束。
Serial/Serial Old收 集器的运行过程如下:
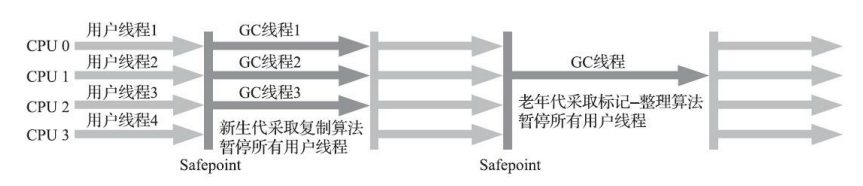
ParNew收集器实质上是Serial收集器的多线程并行版本,除了同时使用多条线程进行垃圾收集之外,其余的行为包括Serial收集器可用的所有控制参数(例如:-XX:SurvivorRatio、-XX: PretenureSizeThreshold、-XX:HandlePromotionFailure等)、收集算法、Stop The World、对象分配规则、回收策略等都与Serial收集器完全一致,在实现上这两种收集器也共用了相当多的代码。
ParNew收集器的工作过程如图所示:
Parallel Scavenge收集器也是一款新生代收集器,它同样是基于标记-复制算法实现的收集器,也是能够并行收集的多线程收集器
Parallel Scavenge收集器的目标则是达到一个可控制的吞吐量(Throughput)。由于与吞吐量关系密切,Parallel Scavenge收集器也经常被称作“吞吐量优先收集器”。
Parallel Scavenge收集器提供了两个参数用于精确控制吞吐量,分别是控制最大垃圾收集停顿时间的-XX:MaxGCPauseMillis参数以及直接设置吞吐量大小的-XX:GCTimeRatio参数。
4.4.4、Serial Old收集器