
虽然上面的配置能够操作成功,但是在 Ribbon 中禁用 Eureka 支持会造成一个问题,那就是服务网关代理的所有服务的 Ribbon 支持都没有了,Zuul 无法使用 Ribbon 来缓存服务的查找,每次请求都要调用 Eureka 查询服务实例,这样会对 Eureka 服务器造成巨大的压力,显然不可取的。
目前有两种办法来规避这个问题:
对于不能用 Eureka 管理的应用,可以建立一个单独的 Zuul 服务器来处理这些路由。
建立一个 Spring Cloud Sidecar 实例。Spring Cloud Sidecar 允许开发使用 Eureka 实例注册非 JVM 服务,然后再通过 Zuul 代理,相当于曲线救国。
4、动态重载路由zuul 还有一个动态加载路由的功能,也就是在不重启 zuul 服务的情况下刷新路由。
直接修改application.yml将 prefix 从/api改为/apis。注意这里修改后要让修改生效需编译一次 application.yml 让修改替换到 target 文件中(idea 如此,eclipse 应该类似),或者直接到编译文件夹下修改 application.yml
然后访问/refresh路径,可以看到如下返回值:
响应表明更新 prefix。然后访问/routes路径会发现前缀变成了apis
这个功能与 spring cloud config 配合,用起来就是爽。
5、服务超时Zuul 使用 Netflix 的 Hystrix 和 Ribbon 库来进行 http 请求。so 也是有超时机制存在的。配置方法和前面的一篇类似。但是只能通过配置文件来进行,无法通过注解(这是 Zuul 管理的没有地方给你写注解)。通过配置hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds属性来实现。如果要为特定的服务配置只需将 default 替换为服务名就行了。
注意还要只有有另一个超时机制。虽然覆盖了 hystrix 的超时,但是 Ribbon 也会超时任何超过 5s 的调用。so 如果超时时间大于 5s 还要配置 Ribbon 的超时,配置方式如下:
#对所有服务生效 ribbon.readTimeout: 7000 #对组织服务生效 licensingservice.ribbon.readTimeout: 7000 6、重点:过滤器这才是服务网关真正重要的东西。有了过滤器才能实现自定义的通用处理逻辑。可在此进行通用的安全验证、日志、服务跟踪等操作。和 springboot 中的过滤器概念类似,这里就不做说明了。
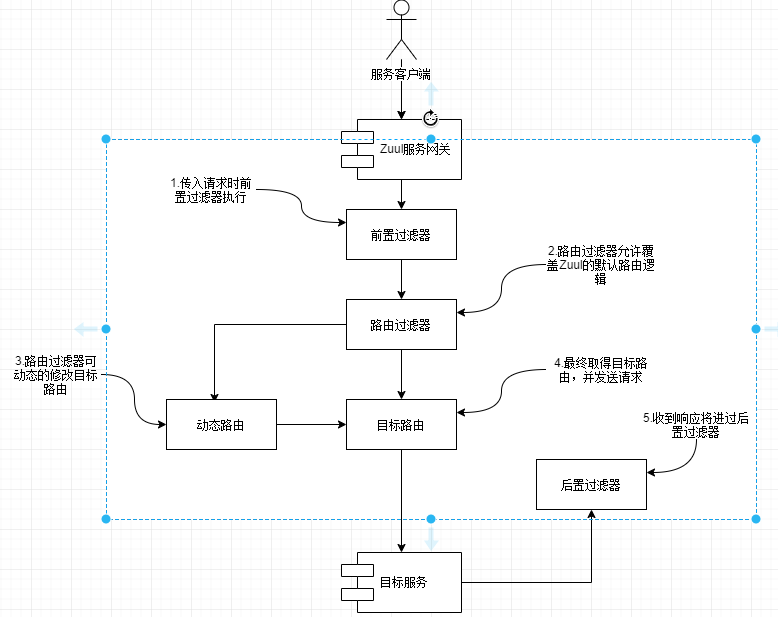
Zuul 支持以下四种过滤器:
前置过滤器——在将请求发送到目的地之前被调用。通常进行请求格式检查、身份验证等操作。
后置过滤器——在目标服务被调用被将响应发回调用者后被调用。通常用于记录从目标服务返回的响应、处理错误或审核敏感信息。
路由过滤器——在目标服务被调用之前拦截调用。通常用来做动态路由。
错误过滤器——在产生错误是调用,用于对错误进行统一处理。
下图展示了在处理客户端请求时,各种过滤器时如何工作的:
下面说说如何来使用这些过滤器:
a、前置过滤器这里我们来实现一个过滤器-IdFilter,对每个请求检查请求头中是否有一个关联 id,无 id 生成一个 id 加入到 header 中。代码如下:
@Component public class IdFilter extends ZuulFilter { private static final Logger LOGGER = LoggerFactory.getLogger(IdFilter.class); /** * 返回过滤器类型 ;pre:前置过滤器。post:后置过滤器。routing:路由过滤器。error:错误过滤器 */ @Override public String filterType() { return "pre"; } /** * 过滤器执行顺序 */ @Override public int filterOrder() { return 1; } /** * 是否启动此过滤器 */ @Override public boolean shouldFilter() { return true; } @Override public Object run() { RequestContext ctx = RequestContext.getCurrentContext(); String id = ctx.getRequest().getHeader("id"); //如果request找不到,再到zuul的方法中找id.request不允许直接修改response中的header, // 所以为了让后续的过滤器能够获取到id才有下面的语法 if(id==null){ id = ctx.getZuulRequestHeaders().get("id"); } if (id == null) { id = UUID.randomUUID().toString(); LOGGER.info("{} 无id,生成id:{}",ctx.getRequest().getRequestURI(), id); ctx.addZuulRequestHeader("id", id); } else { LOGGER.info("{}存在id:{}", ctx.getRequest().getRequestURI(), id); } return null; } }要在 Zuul 中实现过滤器,必须拓展 ZuulFilter 类(2.x 版本中不是这样的),然后覆盖上述 4 个方法。