
zunionstore sport:ranking:why:last_seven_day 7 sport:ranking:why:20210222 sport:ranking:why:20210223 sport:ranking:why:20210224 sport:ranking:why:20210225 sport:ranking:why:20210226 sport:ranking:why:20210227 sport:ranking:why:20210228 weights 1 1 1 1 1 1 1 aggregate sum
这条命令后面的 weights 和 aggregate 都是可以不用写的,有默认值,我这里为了不隐藏数据,都写了出来。
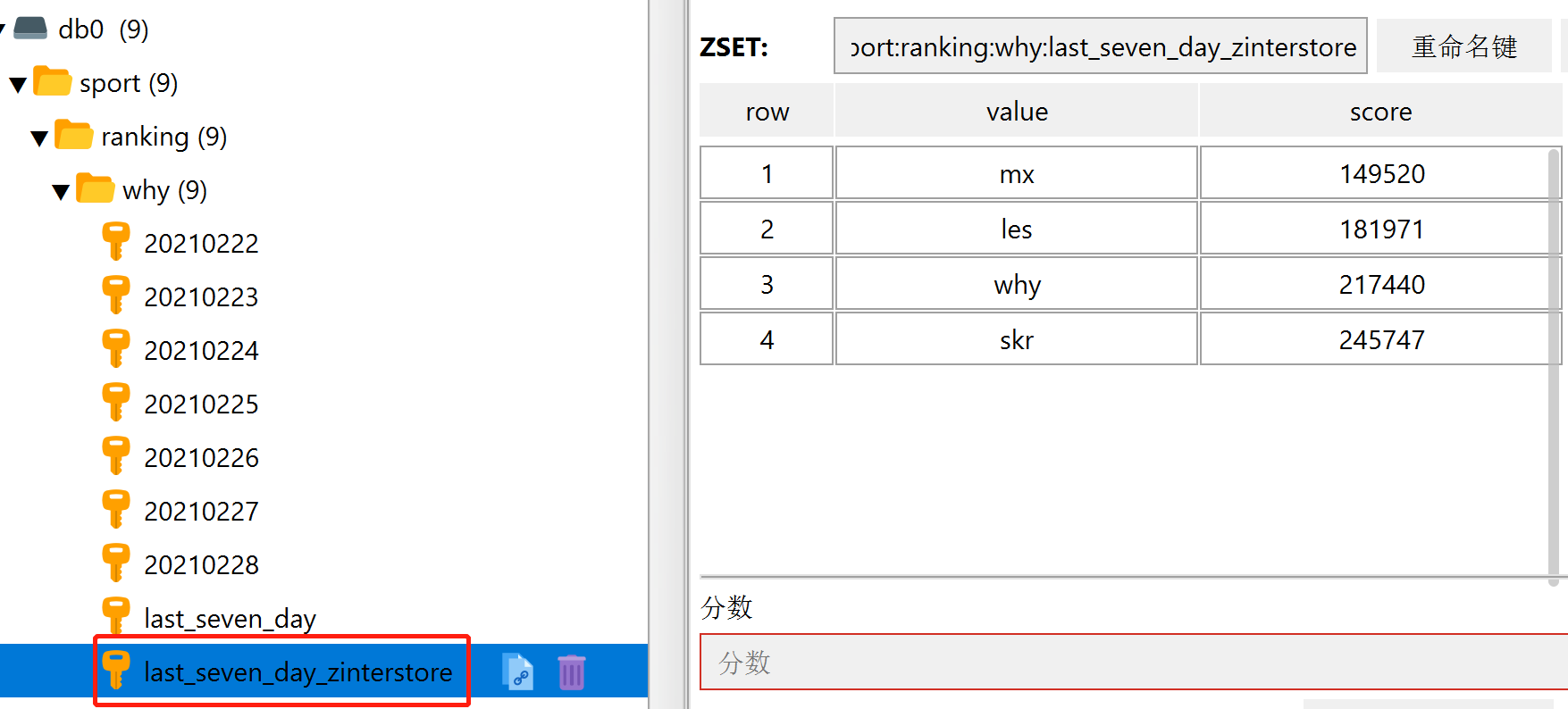
执行完成后,可以看到多了一个 key,里面放的就是最近 7 天的数据汇总:

上面用的是并集,如果我们的要求是对最近 7 天,每天都上传运动数据的人进行排序,就用交集来算。
命令和上面的一致,只是把 zunionstore 修改为 zinterstore 即可。
另外为了有对比,合并之后的队列名称也修改一下,命令如下:
zinterstore sport:ranking:why:last_seven_day_zinterstore 7 sport:ranking:why:20210222 sport:ranking:why:20210223 sport:ranking:why:20210224 sport:ranking:why:20210225 sport:ranking:why:20210226 sport:ranking:why:20210227 sport:ranking:why:20210228 weights 1 1 1 1 1 1 1 aggregate sum
从执行结果可以看出来,由于 jay 同学在 20210222 这一天没有上传运动数据,所以取交集的时候没有他了:
知道最近 7 天的做法了,我们又有每一天数据,上一周、上一月、上个季度、这一年排行榜啥的不都是这个套路吗?
呃......
怎么感觉还是 API 教学呢?
还是不得劲,再换个其他的。
亿级用户排行榜王者荣耀,妥妥的亿级用户吧。比如我想看看我在亿级用户中排多少名,于是我打开了游戏,二十多分钟(玩了一局)之后我终于找到排行榜的位置。
结果,未上榜:
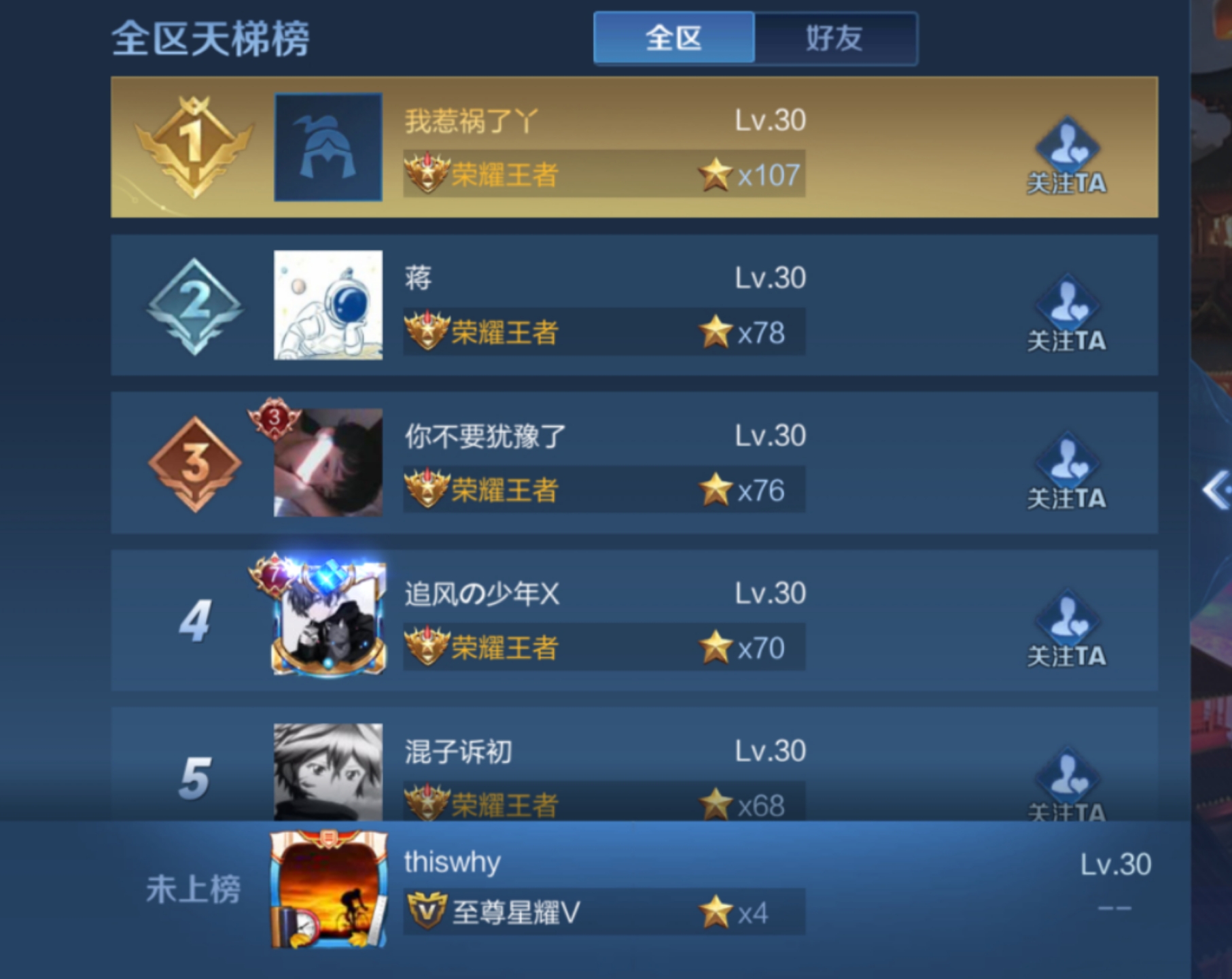
我这个千年老夫子,当然是未上榜了。
就算真的有排名了,排名好几千万,8 位数字,在页面上也不好放呀。
但是假设现在的需求就是要查询用户的全服排名,怎么查?
我瞎说一个我能想到的基于 Redis 的初版方案,注意是我瞎想的,实际做起来肯定是异常复杂的方案。
我是怎么想的呢?
我就寻思,一般面试遇到什么千万条数据、几个 G 文件、上亿的数据啥的,首先想到的方案就是分而治之。
这个亿级用户排行榜的需求也得用分治的思想。
王者一共 8 个段位:
1、倔强青铜
2、秩序白银
3、荣耀黄金
4、尊贵铂金
5、永恒钻石
6、至尊星耀
7、最强王者
8、荣耀王者
所以我们可以有 8 个桶。
这个桶可以是一个 Redis 里面的 8 个不同的 key,甚至可以是 8 个 Redis 里面各一个 key,看面试官给你的经费是多少,钱多就可劲造。
如下图所示:
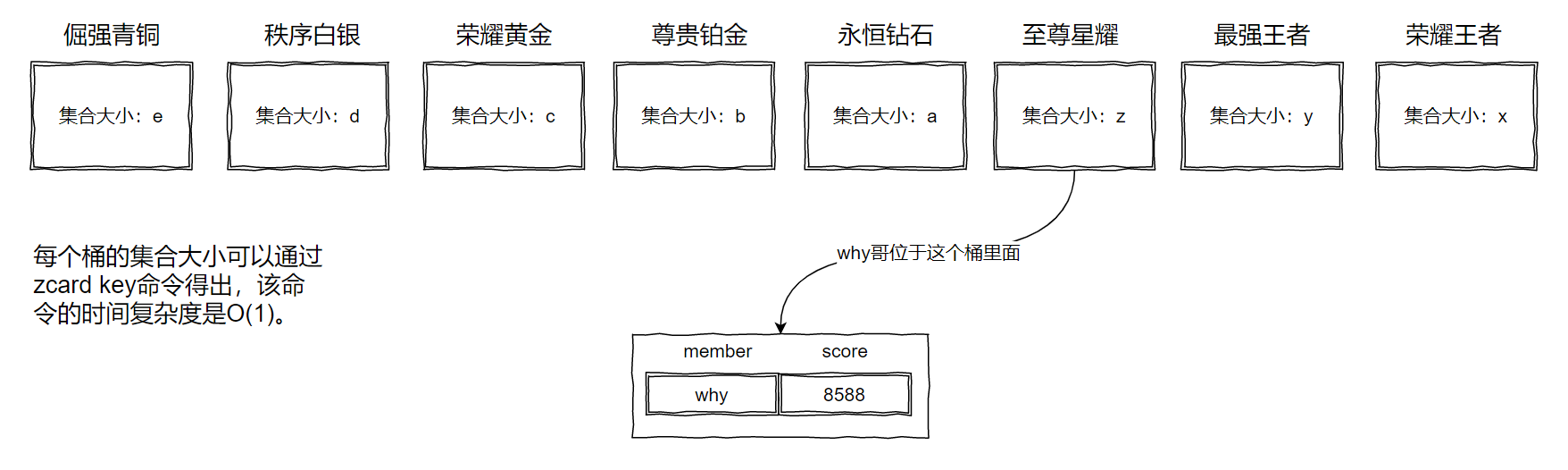
解释一下上面的图片中 score 为 8588 是怎么来的。
首先我们用 Redis 的有序集合,那么我们就得给每个 member 一个 score。
所以,每个用户在桶里面都一个经过公式计算后得出的积分。
比如why哥现在的段位就是星耀,假设计算出来的分数是 8588。
那么现在要算why哥在全服的排名就很好算了:
写程序的时候是可以知道我现在的段位是星耀,那么直接去星耀的桶里面,用 zrevrank 计算出当前桶里面的排名,假设为 n。
然后再通过 zcard 这个 O(1) 的命令获取到,前面的桶,也就是最强王者和荣耀王者这两个桶的集合大小,分别为 y 和 x。
那么why哥的全服排名就是 n+y+x。
所以获取任何一个用户的全服排名,就是看他在自己的桶里面的排名加上前面桶里面的元素个数即可。
而且现在要计算全服 top 100 就很容易了嘛。
直接取最前面的桶,也就是荣耀王者里面的前 100 个就完事了。
搞定。

等等,真的搞定了吗?
思路是对了,但是对于亿级用户只分 8 个桶未免太少了吧?
那就继续分桶呗,别忘了,每个段位里面还有小段位的。
比如星耀,里面就有星耀五到星耀一五个小段位,青铜三到青铜一三个小段位。
全部算上就是 27 个桶。
但是,27 个桶也少。
那么星耀二到星耀一还需要五颗星、青铜三到青铜二要三颗星才行呢。
这样算下来,就是 160 个桶。
160 个桶还是不够?
额。。。
推翻重来,直接把段位加上各种其他条件换算成积分,然后按照积分来拆分:
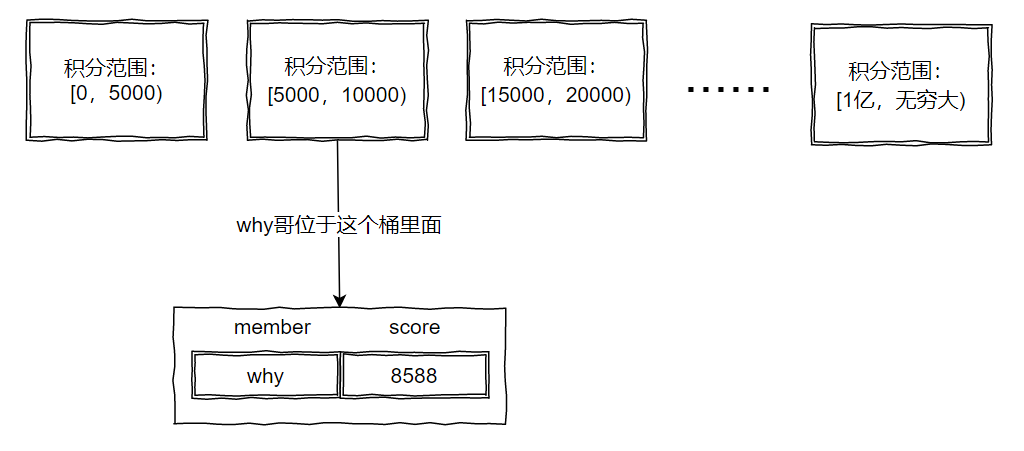
这样,想怎么拆分数段都行、拆多细都行。
完美。
等等,真的完美吗?
你看我的积分范围,都划分的非常的均匀。
按照段位拆分,有些菜鸡选手,打了两把觉得没意思,骂骂咧咧的退出游戏,就一直留在了青铜段位。
所以青铜段位的选手肯定是远大于荣耀王者的。
所以,实际情况下,用户的落点其实并不是均匀的。
怎么办?
这个时候就需要进行数据分析,通过一系列的高数、概率、离散等知识去做个桶大小的预估。
啊,这玩意就超纲了啊。
那就告辞,收工。

做一个排行榜好像是一个很简单的事情。
但是其实不然,特别是推荐类的排行榜,需要避免马太效应:
比如作者推荐榜单,被推荐到前面的作者,曝光度很高。即使输出质量下降,但是还是很容易获得更多的关注。
位于榜单尾部的作者就很没有参与感。
于是两极分化就出现了,马太效应就来了。
对于这种情况怎么处理呢?
里面就涉及到一个复杂的计算公式了,比如掘金社区的掘力值,用于消息流推荐和作者榜单:
https://juejin.cn/book/6844733795329900551/section/6844733795380232206

所以千万不要错误的以为排行榜是一个非常简单的需求,这里面涉及到一些非常复杂的算法。
最后说一句感谢大家的阅读。
才疏学浅,难免会有纰漏,如果你发现了错误的地方,可以在后台提出来,我对其加以修改。
