
通过Collection接口的默认方法
//通过Stream接口的静态工厂方法 Stream stream = Stream.of("hello", "world", "hello world"); String[] strArray = new String[]{"hello", "world", "hello world"}; //通过Stream接口的静态工厂方法 Stream stream1 = Stream.of(strArray); //通过Arrays方法 Stream stream2 = Arrays.stream(strArray); List<String> list = Arrays.asList(strArray); //通过Collection接口的默认方法 Stream stream3 = list.stream();

本质都是StreamSupport.stream。
通过Collection接口的默认方法获取并行流。

或者通过stream流调用parallel获取并行流
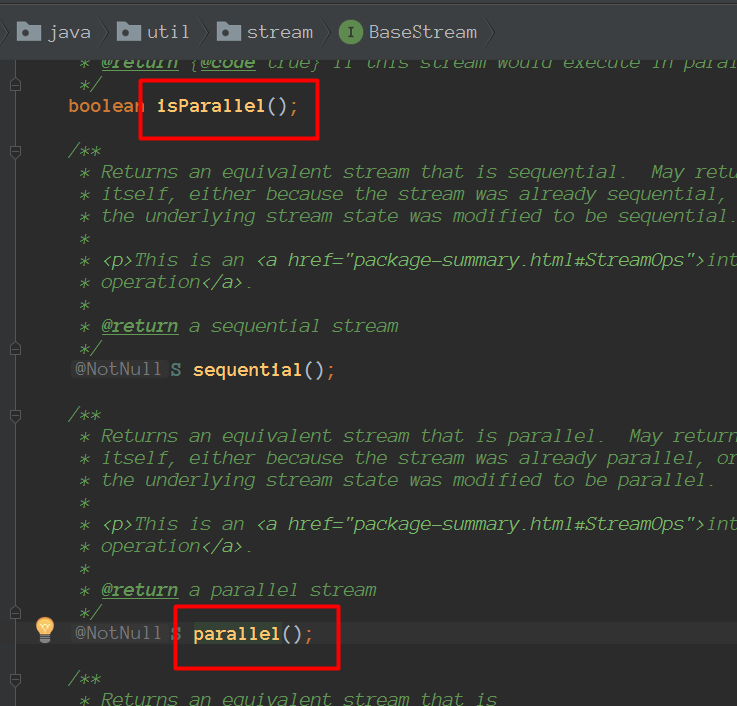
只需要对并行流调用sequential方法就可以把它变成顺序流
中间操作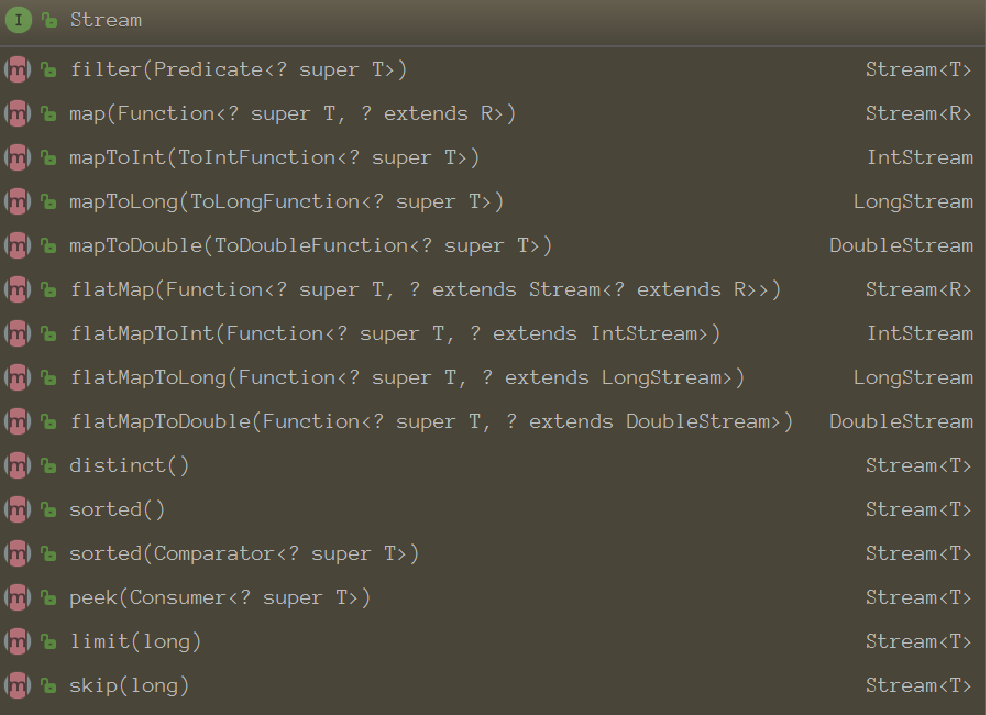
可以通过对收集源调用parallelStream方法来把集合转换为并行流。并行流就是一个把内容分成多个数据
块,并用不同的线程分别处理每个数据块的流。这样一来,你就可以自动把给定操作的工作负荷分配给多核处理器的所有内核,让它们都忙起来。
并行流用的线程是从哪儿来的?有多少个?怎么自定义这个过程呢?
并行流内部使用了默认的ForkJoinPool,它默认的线程数量就是你的处理器数量,这个值是由 Runtime.getRuntime().availableProcessors()得到的。但是你可以通过系统属性 java.util.concurrent.ForkJoinPool.common. parallelism来改变线程池大小,如下所示:
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","12");
这是一个全局设置,因此它将影响代码中所有的并行流。反过来说,目前还无法专为某个
并行流指定这个值。一般而言,让ForkJoinPool的大小等于处理器数量是个不错的默认值,
除非你有很好的理由,否则我们强烈建议你不要修改它
测试并行流和顺序流速度
//Sequential Sort, 采用顺序流进行排序 @Test public void sequentialSort(){ long t0 = System.nanoTime(); long count = values.stream().sorted().count(); System.err.println("count = " + count); long t1 = System.nanoTime(); long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0); System.out.println(String.format("sequential sort took: %d ms", millis)); //sequential sort took: 1932 ms } //parallel Sort, 采用并行流进行排序 @Test public void parallelSort(){ long t0 = System.nanoTime(); long count = values.parallelStream().sorted().count(); System.err.println("count = " + count); long t1 = System.nanoTime(); long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0); System.out.println(String.format("parallel sort took: %d ms", millis)); //parallel sort took: 1373 ms 并行排序所花费的时间大约是顺序排序的一半。 }
