
单独型比较好理解,执行顺序是按照id=1,id=2,id=3执行,由远及近
先scott登录,然后执行sql,例子来自《收获,不止SQL优化》一书
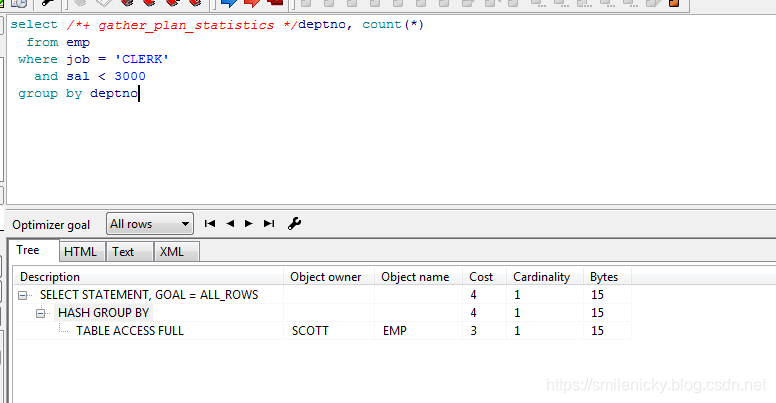
所以可以给出单独型的图例:

【联合型关联型】
(1) 联合型的关联型(NL)
这里使用Hint的nl
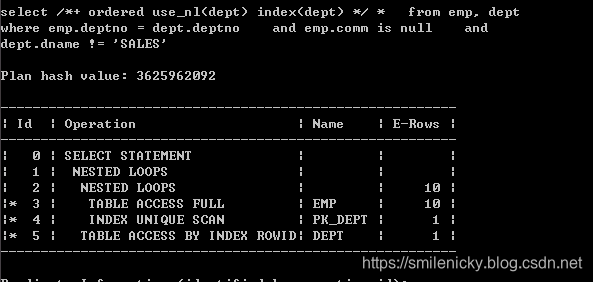
select /*+ ordered use_nl(dept) index(dept) */ * from emp, dept where emp.deptno = dept.deptno and emp.comm is null and dept.dname != 'SALES'这图来自《收获,不止SQL优化》,可以看出id为2的A-Rows实践返回行数为10,id为3的Starts为10,说明驱动表emp访问的结果集返回多少条记录,被驱动表就被访问多少次,这是关联型的显著特征

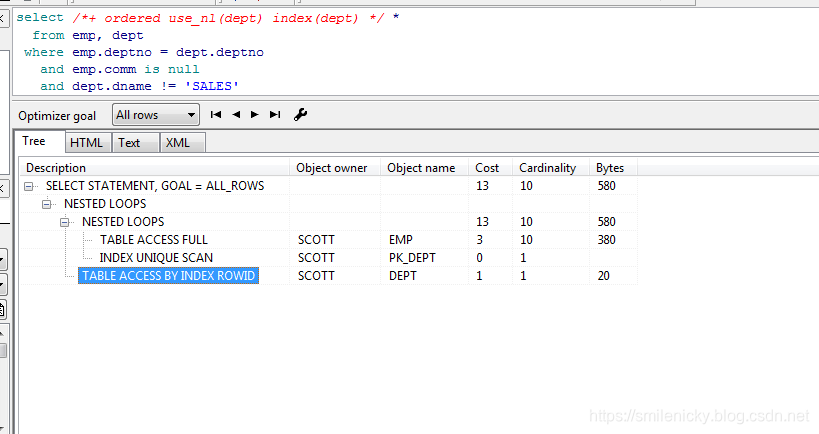
关联型不一定是驱动表返回多少条,被驱动表就被访问多少次的,注意FILTER模式也是关联型的
(2) 联合型的关联型(FILTER)
前面已经介绍了联合型关联型(nl)这种方法的,这种方法是驱动表返回多少条记录,被驱动表就被访问了多少次,不过这种情况对于FILTER模式下并不适用
执行SQL,这里使用Hint /+ no_unnset /
select * from emp where not exists (select /*+ no_unnset */ 0 from dept where dept.dname='SALES' and dept.deptno = emp.deptno) and not exists(select /*+ no_unnset */ 0 from bonus where bonus.ename = emp.ename)ps:图来自《收获,不止SQL优化》一书,这里可以看出id为2的地方,A-Rows实际返回行数为8,而id为3的地方,Starts为3,说明对应SQL执行3次,也即dept被驱动表被访问了3次,这和刚才介绍的nl方式不同,为什么不同?
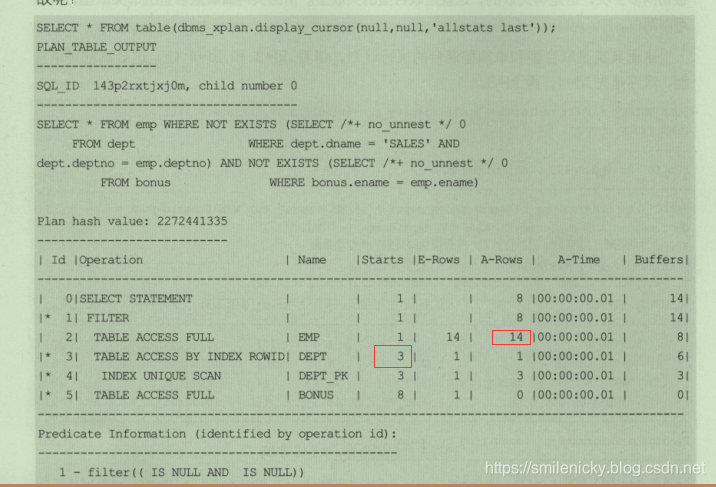
所以,就很明显了,被过滤了重复数据,也就是说FILTER模式的对数据进行过滤,驱动表执行结果集返回多少行不重复数据,被驱动表就被访问多少次,FILTER模式可以说是对nl模式的改善
(3) 联合型的关联型(UPDATE)
update emp e1 set sal = (select avg(sal) from emp e2 where e2.deptno = e1.deptno),comm = (select avg(comm) from emp e3)联合型的关联型(UPDATE)和FILTER模式类似,所以就不重复介绍
(4) 联合型的关联型(CONNECT BY WITH FILTERING)
select /*+ connect_by_filtering */ level, ename ,prior ename as manager from emp start with mgr is null connect by prior empno = mgr给出联合型关联型图例:

【联合型非关联型】
可以执行SQL
select ename from emp union all select dname from dept union all select '%' from dual对于plsql可以使用工具查看执行计划,sqlplus客户端的可以使用statistics_level=all的方法获取执行计划,具体步骤
1:alter session set statistics_level=all;
2:在此处执行你的SQL;
3:select * from table(dbms_xplan.display_cursor(null , null,'allstats last'));