
如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after- milliseconds 选项所指定的值,则这个实例会被 Sentinel(哨兵)进程标记为主观下线(sdown)
如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器的确进入了主观下线状态。
当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认Master主服务器进入了主观下线状态(SDOWN), 则Master主服务器会被标记为客观下线(ODOWN)。
在一般情况下, 每个Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有Master主服务器、Slave从服务器发送 INFO 命令。
当Master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master主服务器的所有 Slave从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状态就会被移除。若 Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回 复,Master主服务器的主观下线状态就会被移除。
故障切换涉及到的事件和参数:
sdown:主观下线,当某个哨兵与master之间在指定时间内无法正常通讯后该哨兵将产生sdown事件
quorum(仲裁数):是一个整数,表示master从主观下线变为客观下线所需要的哨兵数量(但有quorum个哨兵与master通讯失败则master进入主观下线)
odown:当sdown的事件的数量达到指定值(quorum)时,将产odown事件,表示master客观下线了;
majority(大多数):是一个整数,该值通过计算自动得出,计算公式为floor(哨兵总数量/2)+1 floor为下取整
当odown产生时,会选出一个哨兵准备进行故障切换,在切换前该哨兵还需要获得大多数(majority)哨兵的授权,授权成功则开始进行故障切换;
故障切换完成后,若先前宕机的节点(原来的master)恢复正常,则该节点会降为slave;
部署Sentinel的基本知识
哨兵应与分布式的形式存在,若哨兵仅部署一个则实际上没有办法提高可用性,当仅有的哨兵进程遇到问题退出后,则无法完成故障恢复;
一个健壮的部署至少需要三个Sentinel实例
三个哨兵应该部署在相互的独立的计算机或虚拟机中;
Sentinel无法保证在执行故障转移期间的写入的数据是否能够保留下来;
部署案例:下例图中名称的释义:
S:sentinel
M:master
R:replace(slave)
1.不要采用下例部署
上述部署中若M1(包括S1,因为在同一个机器上)宕机,剩下的S2虽然可以认定M1主观下线,但是却无法得到大多数哨兵的授权并开始故障切换,因为此时majority为2;
2.简单且实用的部署
上述部署由三个节点组成,每个节点都运行着Redis进程和Sentinel进程,结构简单,安全性也有了提高;
当M1发生故障时,S2和S3可以就该故障达成一致,并且能够授权进行故障切换,从而使得客户端可以正常使用;但也存在丢失已写入数据的情况,因为redis内部使用异步复制,Master和Slave之间的数据在某个时间点可能不一致;
注意:
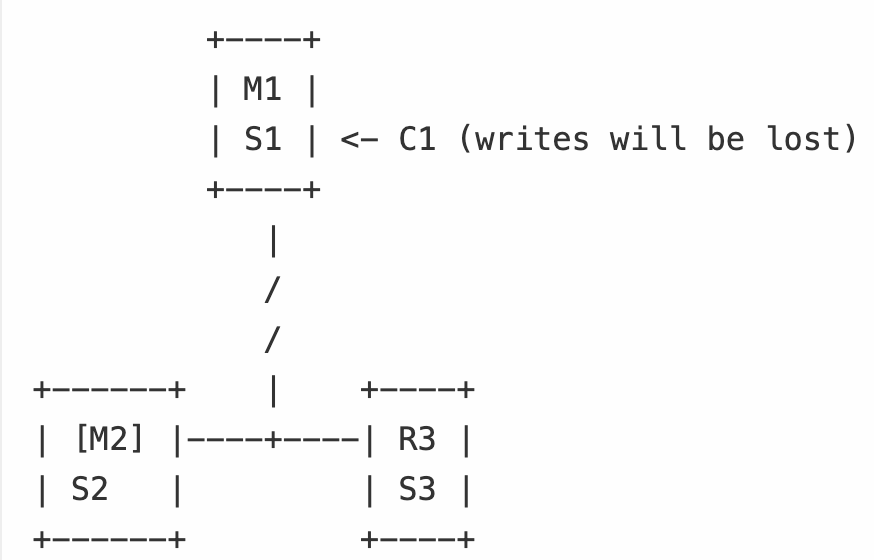
由于网络存在分区性质,若客户端C1和M1处于同一分区,但是该分区与S1,S2所在的分区无法通讯时,C1可以继续向M1写入数据,这写数据将丢失,因为当网络恢复时,M1可会被降为slave,而丢弃自己原本的数据;
使用下例配置可缓解该问题:
min-replicas-to-write 1 min-replicas-max-lag 5上述配置表示,只要master无法写入数据到任何一个slave超过5秒,则master停止接受写入;
3.在客户端部署哨兵若某些原因导致没有足够的服务器节点用于部署哨兵,则可以将哨兵部署至客户端,如下所示

若M1出现故障,则S1,S2,S3可顺利的进行故障切换;但要注意该部署可能出现案例2中的问题