
从上面的图可以发现二分的次数越多就越接近经纬度的实际值,和前面提到的不断递归正方形是一个意思。按照上面的方式我们选定一个二分的深度(也就是精度)分别对经纬度进行编码。然后按照以奇数为纬度,偶数为经度组合成一个二进制序列,再将获取到的经纬度组合二进制序列以每5个数为一组,将每一组都进行转换成十进制数字,最后采用Base32对应编码规则进行转换可得到编码,也就是最后的索引。
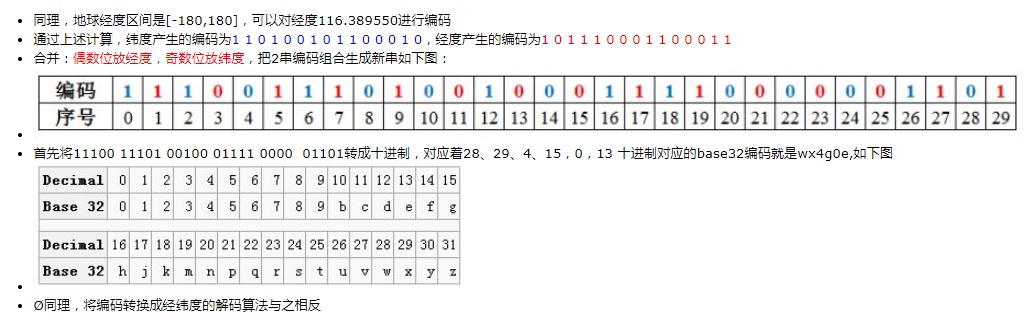
通过上面几个步骤介绍了一下GeoHash具体的流程、有了上面这个知识点,理解Redis GEO原理就很简单了,Redis使用ZSet的方式存储Geo类型的数据,有序集合里面的member是具体的业务对象,score就是该业务对象的经纬度进行GeoHash编码之后将二级制序列转成52位整数值数据。当我们想要获取某个经纬度附近的元素时候,先根据当前经纬度计算出对应的GeoHash块(52位整数值),在根据半径计算出当前hash块周围的8个hash块,然后在根据score值获取这8个hash块范围内的元素返回。
GEO HASH 延伸对于一个经纬度,如果我们编码的时候选择对经度二分3次(3位二进制),对维度二分2次(2位二进制),最后组合成一个5位的二级进序列,经过Base32编码得到一个字符。那么这个字符的一共有2^5=32个,这样就将地图划分为32个块。如下图所示
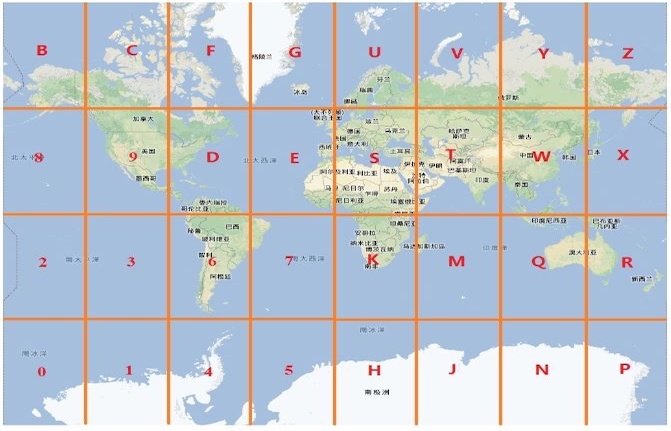
GeoHash将每一个区域画成一块块矩形块,每个矩形块使用一个字符串表示,当我们需要查询附近的点时,通过自己的坐标计算出一个字符串,根据这个字符串定位到我们所在的矩形块,然后返回这个矩形块中的点。然后根据编码的深度来确定精度,或者根据Base32编码之后字符的长度来确定块的所表示的区域大小。

1 5000km 5000km
2 1250km 625km
3 156km 156km
4 39.1km 19.5km
5 4.89km 4.89km
6 1.22km 0.61km
7 153m 153m
8 38.2m 19.1m
9 4.77m 4.77m
10 1.19m 0.596m
11 149mm 149mm
12 37.2mm 18.6mm
对于这样的编码方式有一定的局限性:在拥有局部保序性的同时,具有突变性。导致一些邻近点真实并不是距离较近的点。
参考
https://halfrost.com/go_spatial_search/
https://www.cnblogs.com/LBSer/p/3310455.html