安装情况:CentOS-7.0.1708
安装方法:源码安装
软件:jdk-6u45-linux-x64.bin
下载地点:Oracle.com/technetwork/Java/javase/downloads/java-archive-downloads-javase6-419409.html
第一步:更该权限
chmod 775 jdk-6u45-linux-x64.bin
第二步:执行jdk安装
./jdk-6u45-linux-x64.bin
第三步:设置情况变量
情况变量的设置分为几种方法,按照本身的选择设置:
方法一:vi /etc/profile文件中设置JAVA_HOME以及PATH和CLASS_PATH
因为这样的配置将对所有用户的shell都生效,对系统安详会发生影响。
就是在这个文件的最后加上:
export JAVA_HOME=/usr/local/softWare/jdk1.6.0_45
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
执行 source /etc/profile 是设置当即生效
方法二:
修改.bashrc文件来设置情况变量:
#vi .bashrc
export JAVA_HOME=/usr/local/softWare/java/jdk1.6.0_45
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
设置完成之后,利用logout呼吁退出,然后从头登入使其生效.
验证一下是否安装乐成,利用java -version查察一下。
2.安装scala
下载路径: https://downloads.lightbend.com/scala/2.12.8/scala-2.12.8.tgz scala-2.12.8.tgz
把下载包上传解压
tar -zxvf scala-2.12.8.tgz
rm -rf scala-2.12.8.tgz
设置情况变量
vi /etc/profile
export SCALA_HOME=/usr/local/scala-2.12.8
export PATH=$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin
复制到其他节点:
scp -r scala-2.12.8 192.168.0.109:/usr/local/
scp -r scala-2.12.8 192.168.0.110:/usr/local/
scp /etc/profile 192.168.0.109:/etc/
scp /etc/profile 192.168.0.110:/etc/
使情况变量生效:source /etc/profile
验证:scala -version
3.ssh 免暗码登录
参考https://blog.51cto.com/13001751/2487972
4.安装Hadoop
参考https://blog.51cto.com/13001751/2487972
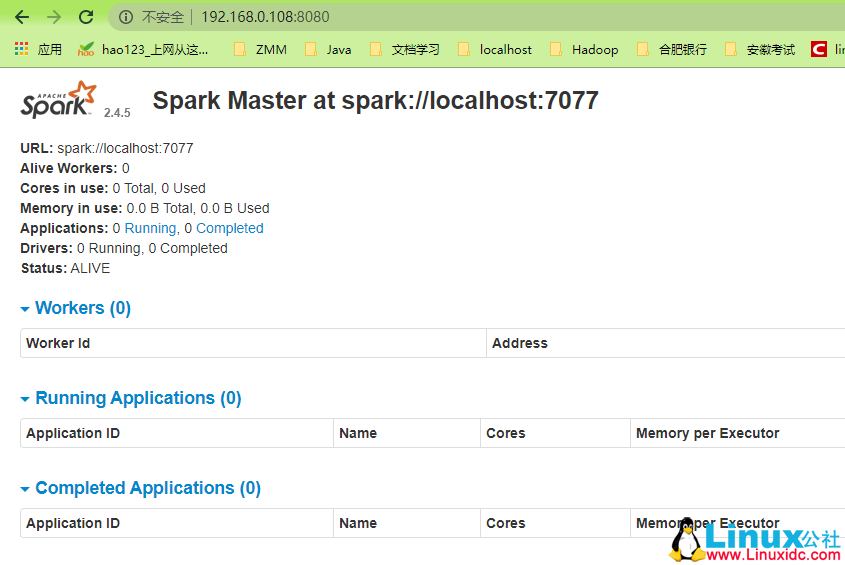
5.安装spark
把下载包上传解压
cd /usr/local/
tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz
cd /usr/local/spark-2.4.5-bin-hadoop2.7/conf/ #进入spark设置目次
mv spark-env.sh.template spark-env.sh #从设置模板复制
vi spark-env.sh #添加设置内容
export SPARK_HOME=/usr/local/spark-2.4.5-bin-hadoop2.7
export SCALA_HOME=/usr/local/scala-2.12.8
export JAVA_HOME=/usr/local/jdk1.8.0_191
export HADOOP_HOME=/usr/local/hadoop-2.7.7
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_IP=spark1
SPARK_LOCAL_DIRS=/usr/local/spark-2.4.5-bin-hadoop2.7
SPARK_DRIVER_MEMORY=1G
export SPARK_LIBARY_PATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$HADOOP_HOME/lib/native、
vi slaves
spark2
spark3
scp -r /usr/local/spark-2.4.5-bin-hadoop2.7 root@spark2:/usr/local/
scp -r /usr/local/spark-2.4.5-bin-hadoop2.7 root@spark3:/usr/local/
./sbin/start-all.sh(不行直接start-all.sh,这个呼吁是hadoop的)
Linux公社的RSS地点:https://www.linuxidc.com/rssFeed.aspx