kafka如何支撑海量消息的集中写入?
答案就是消息分区。
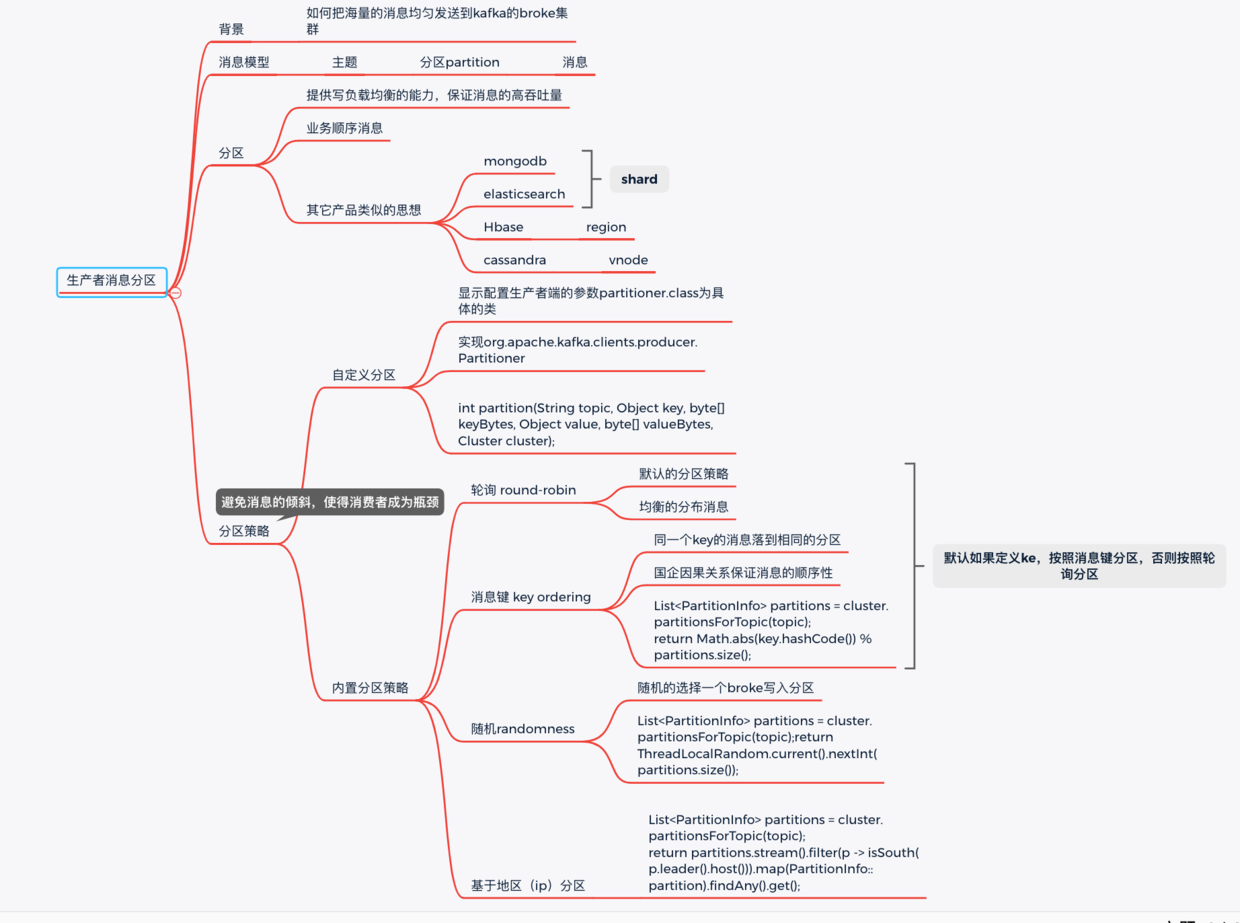
核心思想是:负载均衡,采用合适的分区策略把消息写到不同的broker上的分区中;
其它的产品中有类似的思想。
比如monogodb, es 里面叫做 shard; hbase叫region, cassdra叫vnode;
二、消息的三层结构如下图:
即 topic -> partition -> message ;
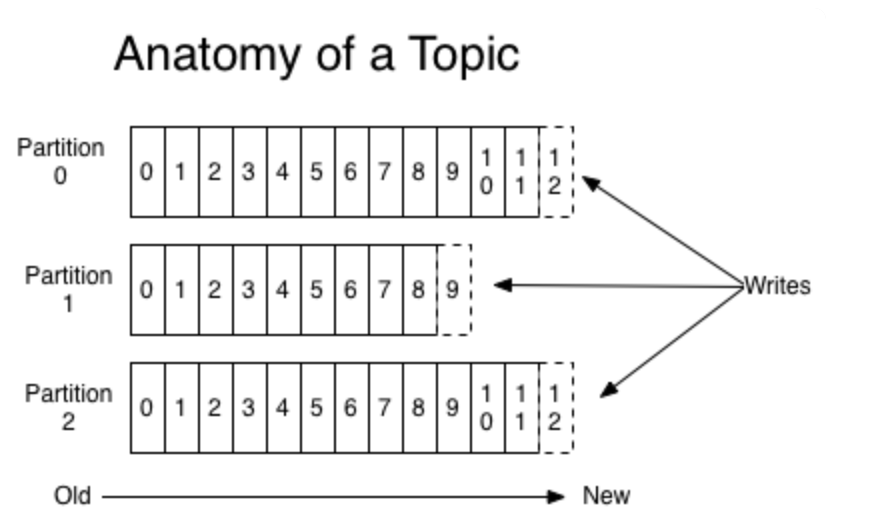
topic是逻辑上的消息容器;
partition实际承载消息,分布在不同的kafka的broke上;
message即具体的消息。
三、分区策略1. round-robin轮询
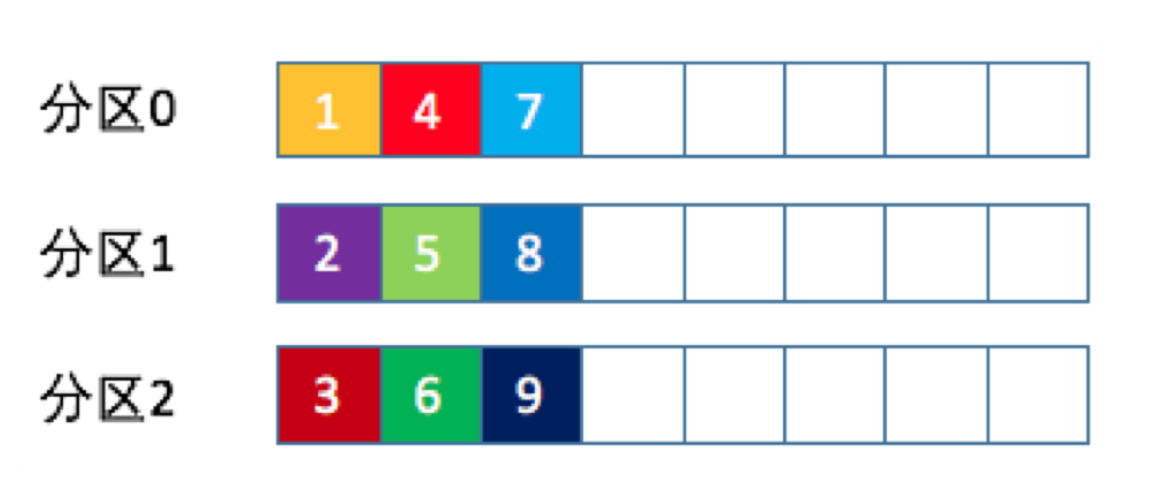
消息按照分区挨个的写。
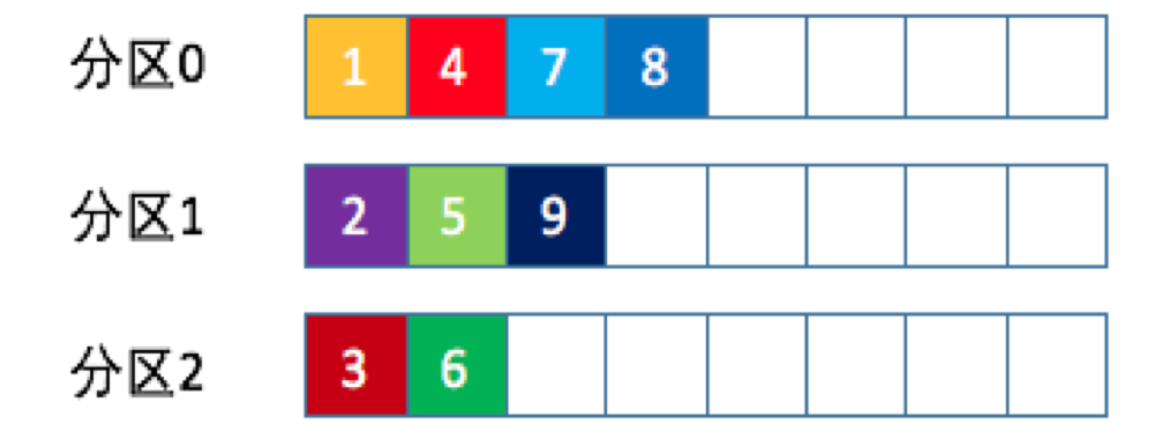
2. randomness随机分区
随机的找一个分区写入,代码如下:
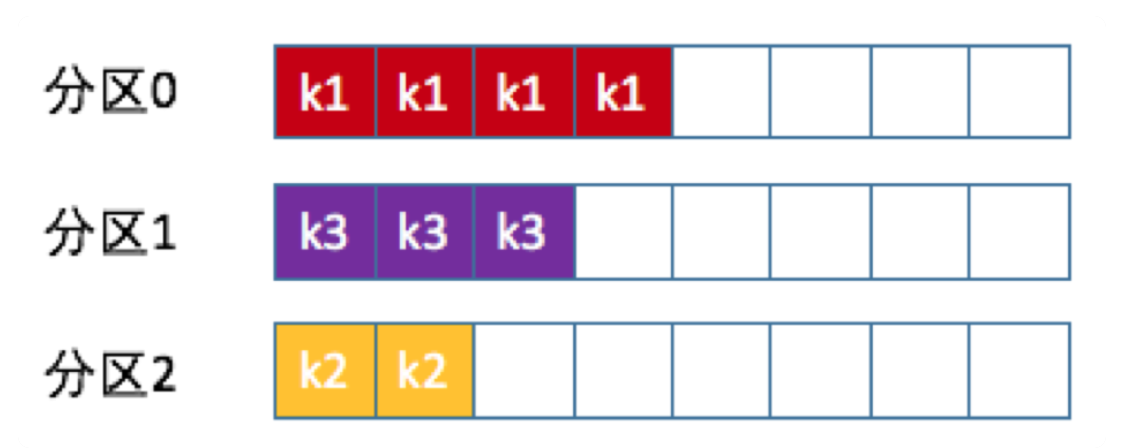
3. key
相同的key的消息写到固定的分区中
4. 自定义分区
必须完成两步:
①. 自定义分区实现类,需要实现org.apache.kafka.clients.producer.Partitioner接口。
主要是实现下面的方法:
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);比如按照区域分区。
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); return partitions.stream().filter(p -> isSouth(p.leader().host())) .map(PartitionInfo::partition).findAny().get();②. 显示配置生产者端的参数partitioner.class为具体的类
系统默认:如果消息有key,按照key分区策略,否则按照轮询策略。
四、小结kafka的分区实现消息的高吞吐量的主要依托,主要是实现了写的负载均衡。可以指定各种负载均衡算法。
负载均衡算法非常重要,需要极力避免消息分区不均的情况,可能给消费者带来性能瓶颈。
小结如下:
Linux公社的RSS地址:https://www.linuxidc.com/rssFeed.aspx