设计集群方案时,至少要思量以下因素:
(1)高可用要求:按照妨碍转移的道理,至少需要3个主节点才气完成妨碍转移,且3个主节点不该在同一台物理机上;每个主节点至少需要1个从节点,且主从节点不该在一台物理机上;因此高可用集群至少包括6个节点。
(2)数据量和会见量:估算应用需要的数据量和总会见量(思量业务成长,留有冗余),团结每个主节点的容量和能遭受的会见量(可以通过benchmark获得较精确预计),计较需要的主节点数量。
(3)节点数量限制:Redis官方给出的节点数量限制为1000,主要是思量节点间通信带来的耗损。在实际应用中应只管制止大集群;假如节点数量不敷以满意应用对Redis数据量和会见量的要求,可以思量:
a.业务支解,大集群分为多个小集群;
b.淘汰不须要的数据;
c.调解数据逾期计策等。
(4)适度冗余:Redis可以在不影响集群处事的环境下增加节点,因此节点数量适当冗余即可,不消太大。
集群的道理:
集群最焦点的成果是数据分区,因此首先先容数据的分区法则;然后先容集群实现的细节:通信机制和数据布局;最后以cluster meet(节点握手)、cluster addslots(槽分派)为例,说明节点是如何操作上述数据布局和通信机制实现集群呼吁的。
数据分区方案:
数据分区有顺序分区、哈希分区等,个中哈希分区由于其天然的随机性,利用遍及;集群的分区方案即是哈希分区的一种。
哈希分区的根基思路是:对数据的特征值(如key)举办哈希,然后按照哈希值抉择命据落在哪个节点。常见的哈希分区包罗:哈希取余分区、一致性哈希分区、带虚拟节点的一致性哈希分区等。
(1)哈希取余分区
哈希取余分区思路很是简朴:计较key的hash值,然后对节点数量举办取余,从而抉择命据映射到哪个节点上。该方案最大的问题是,当新增或删减节点时,节点数量产生变革,系统中所有的数据都需要从头计较映射干系,激发大局限数据迁移。
(2)一致性哈希分区
一致性哈希算法将整个哈希值空间组织成一个虚拟的圆环,范畴为0-2^32-1;对付每个数据,按照key计较hash值,确定命据在环上的位置,然后以后位置沿环顺时针行走,找到的第一台处事器就是其应该映射到的处事器。
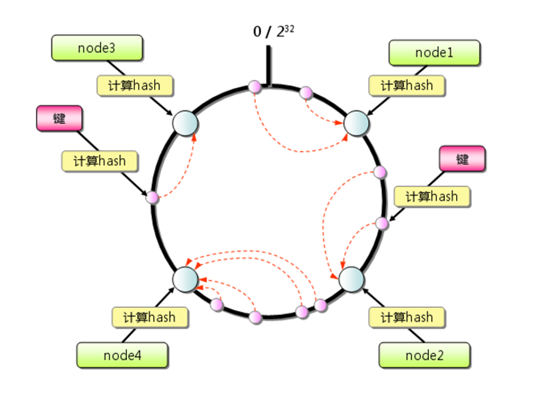
与哈希取余分区对比,一致性哈希分区将增减节点的影响限制在相邻节点。假如在node1和node2之间增加node5,则只有node2中的一部门数据会迁移到node5;假如去掉node2,则原node2中的数据只会迁移到node4中,只有node4会受影响。
一致性哈希分区的主要问题在于,当节点数量较少时,增加或删减节点,对单个节点的影响大概很大,造成数据的严重不服衡。照旧以上图为例,假如去掉node2,node4中的数据由总数据的1/4阁下变为1/2阁下,与其他节点对比负载过高。
(3)带虚拟节点的一致性哈希分区
该方案在一致性哈希分区的基本上,引入了虚拟节点的观念。Redis集群利用的即是该方案,个中的虚拟节点称为槽(slot)。槽是介于数据和实际节点之间的虚拟观念;每个实际节点包括必然数量的槽,每个槽包括哈希值在必然范畴内的数据。引入槽今后,
数据的映射干系由数据hash->实际节点,酿成了数据hash->槽->实际节点。
在利用了槽的一致性哈希分区中,槽是数据打点和迁移的根基单元。槽解耦了数据和实际节点之间的干系,增加或删除节点对系统的影响很小。仍以上图为例,系统中有4个实际节点,假设为其分派16个槽(0-15); 槽0-3位于node1,4-7位于node2,
以此类推。假如此时删除node2,只需要将槽4-7从头分派即可,譬喻槽4-5分派给node1,槽6分派给node3,槽7分派给node4;可以看出删除node2后,数据在其他节点的漫衍仍然较为平衡。槽的数量一般远小于2^32,远大于实际节点的数量;
在Redis集群中,槽的数量为16384
下面这张图很好的总结了Redis集群将数据映射到实际节点的进程:
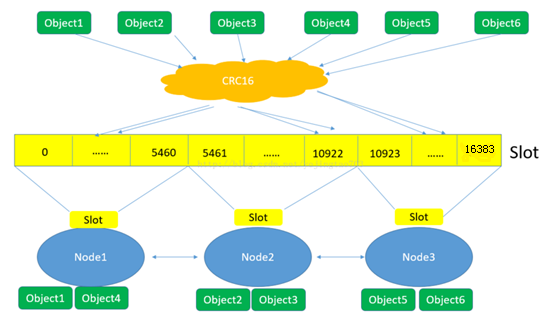
(1)Redis对数据的特征值(一般是key)计较哈希值,利用的算法是CRC16。 Crc16(key) = hash
(2)按照哈希值,计较数据属于哪个槽。 Hash % 16384
(3)按照槽与节点的映射干系,计较数据属于哪个节点。
Redis集群搭建:
一、主/从(master/slave)(缺点: 数据冗余,挥霍内存 (ping - pong)