一、Redis 事务的实现道理
一个事务从开始到竣事凡是会经验以下三个阶段:
1、事务开始
客户端发送 MULTI 呼吁,处事器执行 MULTI 呼吁逻辑。
处事器会在客户端状态(redisClient)的 flags 属性打开 REDIS_MULTI 标识,将客户端从非事务状态切换到事务状态。
void multiCommand(redisClient *c) { // 不能在事务中嵌套事务 if (c->flags & REDIS_MULTI) { addReplyError(c,"MULTI calls can not be nested"); return; } // 打开事务 FLAG c->flags |= REDIS_MULTI; addReply(c,shared.ok); }2、呼吁入队
接着,用户可以在客户端输入当前事务要执行的多个呼吁。
当客户端切换到事务状态时,处事器会按照客户端发来的呼吁来执行差异的操纵。
假如客户端发送的呼吁为 EXEC、DISCARD、WATCH、MULTI 四个呼吁的个中一个,那么处事器当即执行这个呼吁。
与此相反,假如客户端发送的呼吁是 EXEC、DISCARD、WATCH、MULTI 四个呼吁以外的其他呼吁,那么处事器并不当即执行这个呼吁。
首先查抄此呼吁的名目是否正确,假如不正确,处事器会在客户端状态(redisClient)的 flags 属性打开 REDIS_MULTI 标识,而且返回错误信息给客户端。
假如正确将这个呼吁放入一个事务行列内里,然后向客户端返回 QUEUED 回覆。
我们先看看事务行列是如何实现的?
每个 Redis 客户端都有本身的事务状态,对应的是客户端状态(redisClient)的 mstate 属性。
typeof struct redisClient{ // 事务状态 multiState mstate; } redisClient;事务状态(mstate)包括一个事务行列(FIFO 行列),以及一个已入队呼吁的计数器。
/* * 事务状态 */ typedef struct multiState { // 事务行列,FIFO 顺序 multiCmd *commands; /* Array of MULTI commands */ // 已入队呼吁计数 int count; /* Total number of MULTI commands */ int minreplicas; /* MINREPLICAS for synchronous replication */ time_t minreplicas_timeout; /* MINREPLICAS timeout as unixtime. */ } multiState;事务行列是一个 multiCmd 范例数组,数组中每个 multiCmd 布局都生存了一个如入队呼吁的相关信息:指向呼吁实现函数的指针,呼吁的参数,以及参数的数量。
/* * 事务呼吁 */ typedef struct multiCmd { // 参数 robj **argv; // 参数数量 int argc; // 呼吁指针 struct redisCommand *cmd; } multiCmd;最后我们再看看入行列的源码:
/* Add a new command into the MULTI commands queue * * 将一个新呼吁添加到事务行列中 */ void queueMultiCommand(redisClient *c) { multiCmd *mc; int j; // 为新数组元素分派空间 c->mstate.commands = zrealloc(c->mstate.commands, sizeof(multiCmd)*(c->mstate.count+1)); // 指向新元素 mc = c->mstate.commands+c->mstate.count; // 配置事务的呼吁、呼吁参数数量,以及呼吁的参数 mc->cmd = c->cmd; mc->argc = c->argc; mc->argv = zmalloc(sizeof(robj*)*c->argc); memcpy(mc->argv,c->argv,sizeof(robj*)*c->argc); for (j = 0; j < c->argc; j++) incrRefCount(mc->argv[j]); // 事务呼吁数量计数器增一 c->mstate.count++; }虽然了,尚有我们上面提到的,假如呼吁入队堕落时,会打开客户端状态的 REDIS_DIRTY_EXEC 标识。
/* Flag the transacation as DIRTY_EXEC so that EXEC will fail. * * 将事务状态设为 DIRTY_EXEC ,让之后的 EXEC 呼吁失败。 * * Should be called every time there is an error while queueing a command. * * 每次在入队呼吁堕落时挪用 */ void flagTransaction(redisClient *c) { if (c->flags & REDIS_MULTI) c->flags |= REDIS_DIRTY_EXEC; }3、事务执行
客户端发送 EXEC 呼吁,处事器执行 EXEC 呼吁逻辑。
假如客户端状态的 flags 属性不包括 REDIS_MULTI 标识,可能包括 REDIS_DIRTY_CAS 可能 REDIS_DIRTY_EXEC 标识,那么就直接打消事务的执行。
不然客户端处于事务状态(flags 有 REDIS_MULTI 标识),处事器会遍历客户端的事务行列,然后执行事务行列中的所有呼吁,最后将返回功效全部返回给客户端; void execCommand(redisClient *c) { int j; robj **orig_argv; int orig_argc; struct redisCommand *orig_cmd; int must_propagate = 0; /* Need to propagate MULTI/EXEC to AOF / slaves? */ // 客户端没有执行事务 if (!(c->flags & REDIS_MULTI)) { addReplyError(c,"EXEC without MULTI"); return; } /* Check if we need to abort the EXEC because: * * 查抄是否需要阻止事务执行,因为: * * 1) Some WATCHed key was touched. * 有被监督的键已经被修改了 * * 2) There was a previous error while queueing commands. * 呼吁在入队时产生错误 * (留意这个行为是 2.6.4 今后才修改的,之前是静默处理惩罚入队堕落呼吁) * * A failed EXEC in the first case returns a multi bulk nil object * (technically it is not an error but a special behavior), while * in the second an EXECABORT error is returned. * * 第一种环境返回多个批量回覆的空工具 * 而第二种环境则返回一个 EXECABORT 错误 */ if (c->flags & (REDIS_DIRTY_CAS|REDIS_DIRTY_EXEC)) { addReply(c, c->flags & REDIS_DIRTY_EXEC ? shared.execaborterr : shared.nullmultibulk); // 打消事务 discardTransaction(c); goto handle_monitor; } /* Exec all the queued commands */ // 已经可以担保安详性了,打消客户端对所有键的监督 unwatchAllKeys(c); /* Unwatch ASAP otherwise we'll waste CPU cycles */ // 因为事务中的呼吁在执行时大概会修改呼吁和呼吁的参数 // 所觉得了正确地流传呼吁,需要现备份这些呼吁和参数 orig_argv = c->argv; orig_argc = c->argc; orig_cmd = c->cmd; addReplyMultiBulkLen(c,c->mstate.count); // 执行事务中的呼吁 for (j = 0; j < c->mstate.count; j++) { // 因为 Redis 的呼吁必需在客户端的上下文中执行 // 所以要将事务行列中的呼吁、呼吁参数等配置给客户端 c->argc = c->mstate.commands[j].argc; c->argv = c->mstate.commands[j].argv; c->cmd = c->mstate.commands[j].cmd; /* Propagate a MULTI request once we encounter the first write op. * * 当赶上第一个写呼吁时,流传 MULTI 呼吁。 * * This way we'll deliver the MULTI/..../EXEC block as a whole and * both the AOF and the replication link will have the same consistency * and atomicity guarantees. * * 这可以确保处事器和 AOF 文件以及隶属节点的数据一致性。 */ if (!must_propagate && !(c->cmd->flags & REDIS_CMD_READONLY)) { // 流传 MULTI 呼吁 execCommandPropagateMulti(c); // 计数器,只发送一次 must_propagate = 1; } // 执行呼吁 call(c,REDIS_CALL_FULL); /* Commands may alter argc/argv, restore mstate. */ // 因为执行后呼吁、呼吁参数大概会被改变 // 好比 SPOP 会被改写为 SREM // 所以这里需要更新事务行列中的呼吁和参数 // 确保隶属节点和 AOF 的数据一致性 c->mstate.commands[j].argc = c->argc; c->mstate.commands[j].argv = c->argv; c->mstate.commands[j].cmd = c->cmd; } // 还原呼吁、呼吁参数 c->argv = orig_argv; c->argc = orig_argc; c->cmd = orig_cmd; // 清理事务状态 discardTransaction(c); /* Make sure the EXEC command will be propagated as well if MULTI * was already propagated. */ // 将处事器设为脏,确保 EXEC 呼吁也会被流传 if (must_propagate) server.dirty++; handle_monitor: /* Send EXEC to clients waiting data from MONITOR. We do it here * since the natural order of commands execution is actually: * MUTLI, EXEC, ... commands inside transaction ... * Instead EXEC is flagged as REDIS_CMD_SKIP_MONITOR in the command * table, and we do it here with correct ordering. */ if (listLength(server.monitors) && !server.loading) replicationFeedMonitors(c,server.monitors,c->db->id,c->argv,c->argc); }
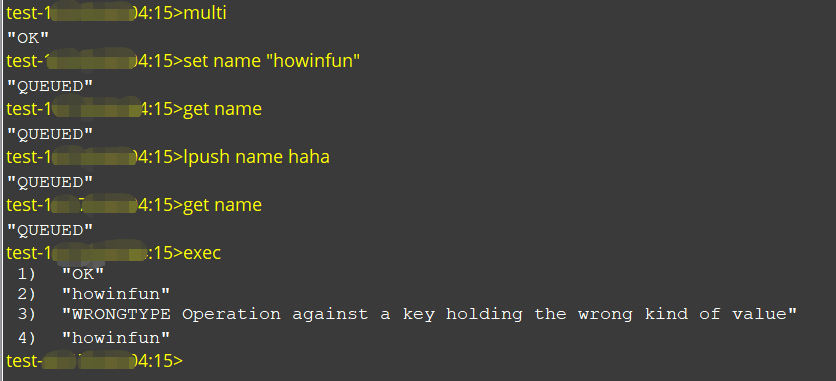
二、为什么许多人说 Redis 事务为何不支持原子性?1、Redis 事务不支持事务回滚机制
Redis 事务执行进程中,假如一个呼吁执行堕落,那么就返回错误,然后照旧会接着继承执行下面的呼吁。
下面我们演示一下: