区别:正则表达式的扩展正则(Extended类型)和根基正则(Basic类型)下,有些字符应该表明为普通字符,要暗示上述非凡寄义则需要加“\”转义字符。反之,在扩展类型下,应被领略为非凡寄义,要取其字面值,也要对其举办“\”转义。
因此,grep东西带上-E选项,暗示利用扩展正则来举办匹配,若没有该选项,则暗示利用基准正则来举办匹配。
对付上述的问题,我们举譬喻下:
例1:
例2:当方针字符串傍边自己就包括了字符,要想举办正则匹配,应该这样做:

例3:

5.其他普通字符集及其替换
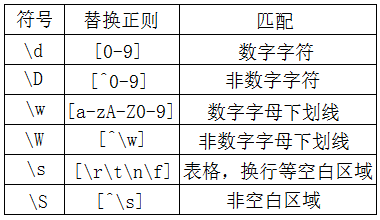
举个例子:

综上,正则表达式有以下三个分类:
(1)根基正则表达式:Basic即BPEs
(2)扩展正则表达式:Extended即EREs
(3)Perl的正则表达式:PREs
因此,当grep指令不跟任何参数时,暗示要利用BREs,后头跟“-E”暗示利用EREs,后头跟“-P”参数,暗示利用PREs
四、贪婪模式与非贪婪模式
1.贪婪模式:正则表达式匹配时,会只管多的匹配切合条件的内容
举譬喻下:
留意:grep默认回收贪婪匹配,大概会对我们的测试功效造成滋扰,各人可以上网利用“正则在线转换东西”举办测试
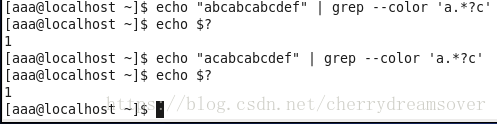
2.非贪婪模式:正则表达式匹配时,会只管少的匹配切合条件的内容,也就是说,一旦发明匹配切合要求,立马就匹配乐成,而不会继承匹配下去(除非有g,开启下一组匹配)
举譬喻下:
五、零宽断言
1.所谓断言,是用来声明一个应该为真的事实。在正则表达式中,只有当断言为真时才会继承举办匹配。
2.零宽断言:像用于查找某些内容之前可能之后的对象,个中一些非凡字符如“\b、^、$”等用于指定一个位置,这个位置应满意必然的条件。
3.分类:
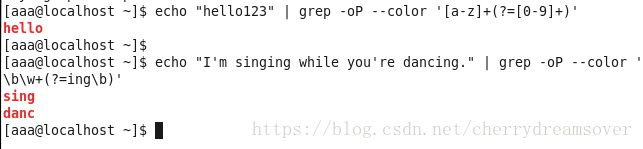
(1)零宽度正预测先行断言(?=exp)
它断言自身呈现的位置之后能匹配的表达式exp。如:\b\w+(?=ing\b),暗示匹配以ing末了的单词的前面的部门(除ing以外的部门)。当我们要查找“I'm singing while you're dancing.”时,它会匹配sing和danc
举譬喻下:
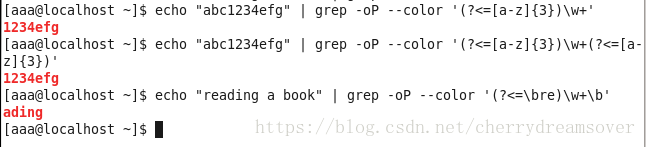
(2)零宽度正回首后发断言(?>=exp)
它断言自身呈现的位置的前面能匹配的表达式exp。如:(?<=\bre)\w+\b会匹配以re开头的单词的后半部门(除er以外的部门),譬喻:在查找“reading a book”时,它匹配ading
举譬喻下:
六、简朴操练
1.手机号码

2.非零的正整数

3.非零开头的最多带两位小数的数字

4.由数字和26位字母构成的字符串
5.QQ号,从10000开始
6.IP地点
\d+\.\d+\.\d+\.\d+
7.判定账号是否正当
^[a-zA-Z0-9][a-zA-Z0-9_]{4,15}$
8.日期名目
^\d{4}-\d{1,2}-\d{1,2}