回滚日志同样也是InnoDB引擎提供的日志,顾名思义,回滚日志的作用就是对数据进行回滚。当事务对数据库进行修改,InnoDB引擎不仅会记录redo log,还会生成对应的undo log日志;如果事务执行失败或调用了rollback,导致事务需要回滚,就可以利用undo log中的信息将数据回滚到修改之前的样子。
但是undo log不redo log不一样,它属于逻辑日志。它对SQL语句执行相关的信息进行记录。当发生回滚时,InnoDB引擎会根据undo log日志中的记录做与之前相反的工作。比如对于每个数据插入操作(insert),回滚时会执行数据删除操作(delete);对于每个数据删除操作(delete),回滚时会执行数据插入操作(insert);对于每个数据更新操作(update),回滚时会执行一个相反的数据更新操作(update),把数据改回去。undo log由两个作用,一是提供回滚,二是实现MVCC。
2、更新语句执行接下来结合一条更新语句的执行,来进一步理解bin log和redo log这两种重要日志。
update t set c=c+1 where ID=2; 2.1、更新语句执行流程我们来看执行器和InnoDB引擎在执行这个简单的update语句时的内部流程。
执行器先找引擎取ID=2这一行。ID是主键,引擎直接用树搜索找到这一行。如果ID=2这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
执行器拿到引擎给的行数据,把这个值加上1,比如原来是N,现在就是N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
引擎将这行新数据更新到内存中,同时将这个更新操作记录到redo log里面,此时redo log处于prepare状态。然后告知执行器执行完成了,随时可以提交事务。
执行器生成这个操作的binlog,并把binlog写入磁盘。
执行器调用引擎的提交事务接口,引擎把刚刚写入的redo log改成提交(commit)状态,更新完成。
update语句的执行流程图如下:
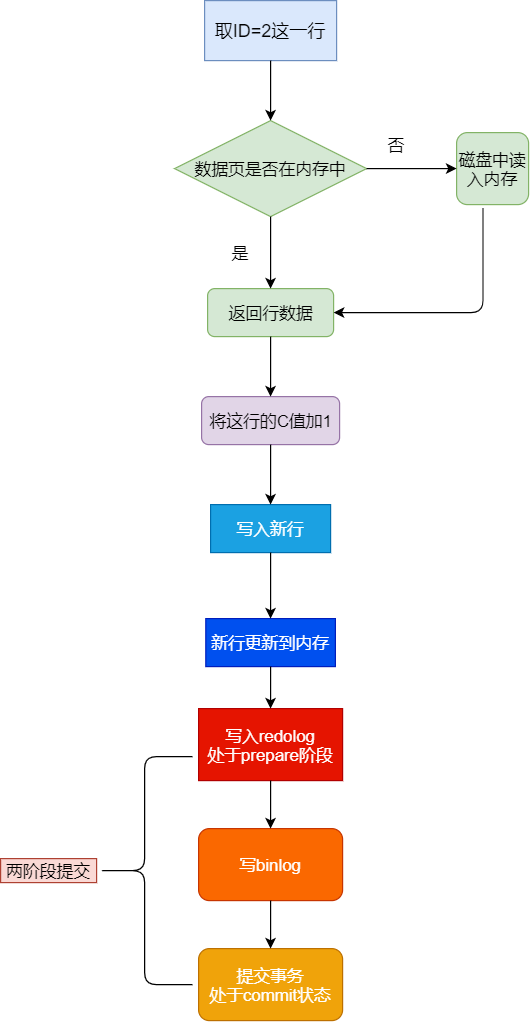
这条语句的执行过程中,redo log的写入分成了两个步骤分成了prepare和commit两个阶段进行提交,这就是所谓的两阶段提交。为什么要用两阶段提交呢?
先用通俗的说法:
比如小明去超市里买一瓶可乐:
小明:老板给我来瓶可乐!透心凉心飞扬的那个。
老板:机器扫一下可乐,告诉小明这瓶可乐2块5,给钱(记录 redo log,事务处于prepare状态)
收钱放入钱箱(记录 binlog,事务实际是否完成的根本依据,处于待标记commit阶段)
然后让小明把可乐拿走(redo log 状态标为 commit,表示该事务逻辑闭环)。到这里,代表一笔交易结束。
等算账前再把这一天卖东西的交易信息一起同步到数据库。
可见,如果收钱之前(prepare阶段,步骤3)交易被打断,回过头来处理此次交易,发现只有记了小黑板但没有收钱,则交易失败,删掉小黑板上的记录(回滚);
如果收了钱后(commit阶段 或 待commit阶段,步骤4 || 5)交易被打断,然后回过头发现系统上有记录(prepare)而且钱箱有本次收入(bin log),则说明本次交易有效,补充修改commit状态,更新到库存中。
用正式一点的语言来描述。
如果不用两阶段提交,要么就是先写完redo log再写binlog,或者采用反过来的顺序。我们看看这两种方式会有什么问题。
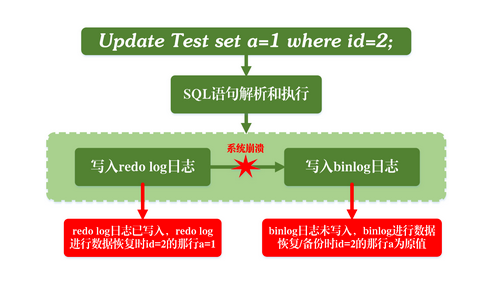
仍然用前面的update语句来做例子。假设当前ID=2的行,字段c的值是0,再假设执行update语句过程中在写完第一个日志后,第二个日志还没有写完期间发生了crash,会出现什么情况呢?
先写redo log后写binlog。假设在redo log写完,binlog还没有写完的时候,MySQL进程异常重启。由于我们前面说过的,redo log写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行c的值是1。
但是由于binlog没写完就crash了,这时候binlog里面就没有记录这个语句。因此,之后备份日志的时候,存起来的binlog里面就没有这条语句。
然后你会发现,如果需要用这个binlog来恢复临时库的话,由于这个语句的binlog丢失,这个临时库就会少了这一次更新,恢复出来的这一行c的值就是0,与原库的值不同。