
编写如下代码
df = pd.read_csv("./demo.txt",header=None,names=['a','b','c','d','e']) print(df) df = pd.read_csv("./demo.txt",header=None,index_col=False,names=['a','b','c','d','e']) print(df)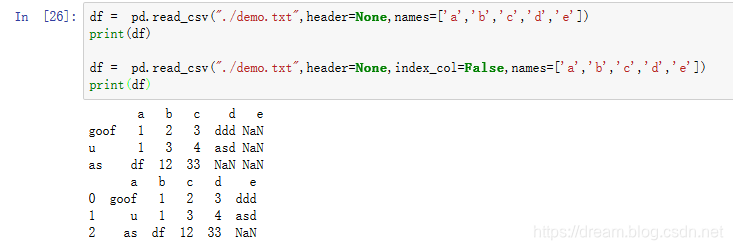
其实发现意义还真不是很大,可能文档并没有表述清楚他的具体作用。接下来说一下index_col的常见用途
在读取文件的时候,如果不设置index_col列索引,默认会使用从0开始的整数索引。当对表格的某一行或列进行操作之后,在保存成文件的时候你会发现总是会多一列从0开始的列,如果设置index_col参数来设置列索引,就不会出现这种问题了。
案例2converters 设置指定列的处理函数,可以用"序号"也可以使用“列名”进行列的指定
import pandas as pd def fun(x): return str(x)+"-haha" df = pd.read_csv("./test.txt",sep=' ',header=None,index_col=0,converters={3:fun}) print(type(df)) print(df.shape) print(df)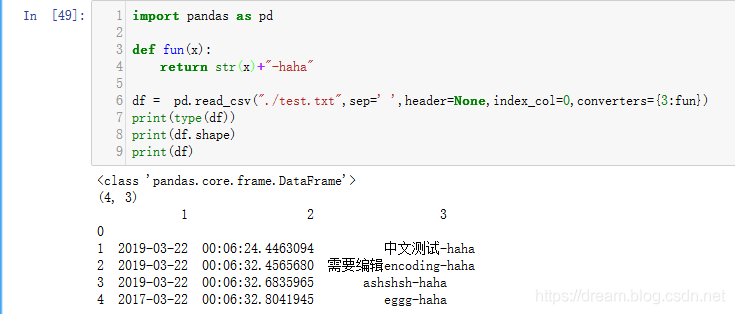
有的IDE中利用Pandas的read_csv函数导入数据文件时,若文件路径或文件名包含中文,会报错。
解决办法
import pandas as pd #df=pd.read_csv('F:/测试文件夹/测试数据.txt') f=open('F:/测试文件夹/测试数据.txt') df=pd.read_csv(f)排除某些行 使用 参数 skiprows.它的功能为排除某一行。
要注意的是:排除前3行是skiprows=3 排除第3行是skiprows=[3]
对于不规则分隔符,使用正则表达式读取文件
文件中的分隔符采用的是空格,那么我们只需要设置sep=" "来读取文件就可以了。当分隔符并不是单个的空格,也许有的是一个空格有的是多个空格时,如果这个时候还是采用sep=" "来读取文件,也许你就会得到一个很奇怪的数据,因为它会将空格也做为数据。
读取的文件中如果出现中文编码错误
需要设定 encoding 参数
为行和列添加索引
用参数names添加列索引,用index_col添加行索引
read_csv该命令有相当数量的参数。大多数都是不必要的,因为你下载的大部分文件都有标准格式。
read_table函数基本用法是一致的,区别在于separator分隔符。
csv是逗号分隔值,仅能正确读入以 “,” 分割的数据,read_table默认是'\t'(也就是tab)切割数据集的
读取具有固定宽度列的文件,例如文件
id8141 360.242940 149.910199 11950.7 id1594 444.953632 166.985655 11788.4 id1849 364.136849 183.628767 11806.2 id1230 413.836124 184.375703 11916.8 id1948 502.953953 173.237159 12468.3read_fwf 命令有2个额外的参数可以设置
colspecs :
需要给一个元组列表,元组列表为半开区间,[from,to) ,默认情况下它会从前100行数据进行推断。
例子:
import pandas as pd colspecs = [(0, 6), (8, 20), (21, 33), (34, 43)] df = pd.read_fwf('demo.txt', colspecs=colspecs, header=None, index_col=0)widths:
直接用一个宽度列表,可以代替colspecs参数
read_fwf 使用并不是很频繁,可以参照 学习
read_msgpack 函数