
流多且有关联,还有切网问题:直播的流之间没有关联性,可以在服务器负载高时调度新的会话到其他服务器,而 RTC 流之间有关联性,有时候不能随意调度,导致负载均衡很难做。
性能优化难:RTC 必须加密,UDP 在内核协议栈的性能低下,QoS 算法的不断迭代消耗了性能。这让 RTC 的服务不再是单纯的 IO 密集型服务器,性能是整个系统的基础,影响其他所有的方面。
客户端版本和算法多,很难做回归测试。牵一发而动全身,很难知道一次修改,是否会导致客户端出问题,很难知道是否所有线上的大版本和小版本是否会出问题。
这些问题,前四个和云原生是有非常紧密的关系。后面几个问题,每个都是很大的话题,限于时间关系,我们会在以后给大家分享。
云的发展方向,不管是中心云、边缘云还是专有云,都是云原生方向。云本身就云里雾里,云原生更加云山雾罩了,我们可以看看云本身的思考。

可以说,开源项目如果做了云原生的改造和重新设计,具备了云架构的能力,就解决了商业化服务一个大问题。我们一起来看,需要做哪些改造。
长会话,升级难长会话:RTC 中最长有 48 小时的会议,甚至更长,直播有时候也是非常长时间推流,比如昨天雷军的视频号直播,折叠小米手机的折叠屏,连续直播折叠三天。这三天直播服务怎么升级?

问题:长会话,最长有 48 小时会议,升级困难。
为何重要:真正提供服务的线上系统,不是在升级,就是在升级的路上,一天到晚都是升级。是不可能完全停下来,中断服务,全量升级后再提供服务。长会话意味着必须支持无中断升级,否则就会造成不可用和服务中断的问题,严重影响客户体验。
扩缩容也会受到长会话的影响。业务量增长时,需要增加机器扩容,现有长会话无法迁移到新的机器,扩容只能应对新的流量。业务量降低后,可以缩容降低成本,如果长会话的周期,超过了业务周期,就无法实现缩容。
直播的业务质量,是按百分比计算,比如百分之 N 的卡顿是可以接受的。而在 RTC 中,会议中有一个人不可用,整个会议就无法继续。每个会议都很重要的,一个会议的重要性,并不一定低于另外一百个会议。
现状和未来:开源 SRS 改进了退出逻辑,可以做到等待一定时间后退出。SRS 还做不到无状态升级,因为要做到无状态化需要依赖存储,而开源的 SLA 还不需要那么高。
GRTN (Tenfold) 已经做到无状态化升级,可随时升级(当然会选择业务低峰期升级)。由于可以无状态重启,我们也顺便解决了 Crash 后恢复的问题,C++ 的程序,就像移动端的 Crash 率一样的,一定会有 Crash。
未来 GRTN (Tenfold) 还会做到状态迁移和 K8S 的滚动升级。
SLA 不同,迁移难中心、边缘、专有云 SLA 差异大:中心云的网络状况,基础设施的完善度很高,会话的迁移相对比较容易。而边缘和专有云的 SLA 就差很多,不能用同样的机制做迁移。

问题:没有 100% 的 SLA,底层设施一定会出问题,迟早会出问题,宕机、IO Hang、网络不可用;中心、边缘、专有云,SLA 差异大,迁移难。
为何重要:当底层基础设施出现问题,虽然概率不大,但一旦出现问题,服务就是不可用了。一台服务器不可用时,影响的不仅仅是这台服务器的会话,而是这个服务器上的所有会议,一个会议一般会跨多个服务器。
中心云的迁移,可用的基础设施比较完善。边缘云和专有云,网络状况和基础设施可靠性,不如中心云,迁移的难度更大。
现状和未来:SRS 没有支持迁移,开源的 SLA 容忍度高一些,同类开源服务器也没有迁移能力;未来计划使用体验差的重连方案支持迁移。
GRTN (Tenfold) 具备了底层迁移能力,预计今年可以支持中心云迁移。未来需要不断优化迁移能力,支持边缘云和专有云的迁移;还需要考虑计划中的迁移,比如流量再均衡。
端口和 IP 复用,扩容难端口和 IP 复用:传统 RTC 一般是内网应用,有可以随便使用的 IP,可以分配几万个随机端口,这些在云上有安全隐患,公网 IPv4 地址不能随意用几万个,扩容就很难做。
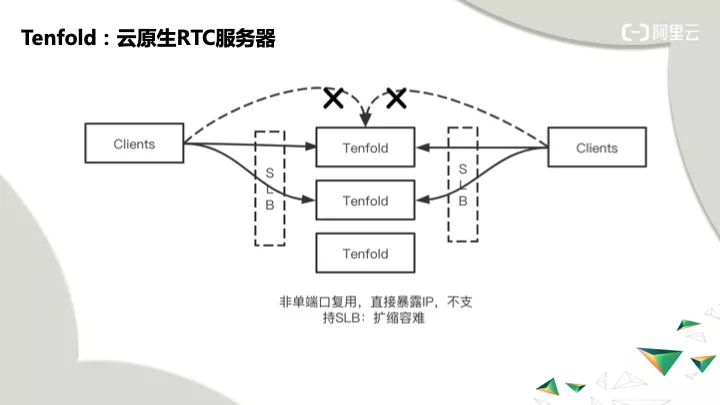
问题:安全要求只能开固定的端口;企业防火墙只能开特定的端口;不能开一定范围端口,比如 10000 到 20000 端口。