
2. 延迟曲线分析:随着线程数的不断增加,读取延迟也会不断增大。这是因为读取线程过多,导致CPU资源调度频繁,单个线程分配到的CPU资源会不断降低;另一方面由于线程之间可能会存在互斥操作导致线程阻塞;这些因素都会导致写入延迟不断增大。和写入延迟以及单次随机查找相比,读取延迟会更大,是因为scan操作会涉及多次IO操作,IO本身就是一个耗时操作,因此会导致延迟更高。
建议
根据图表显示,用户可以根据业务实际情况选择100~500之间的线程数来执行scan操作。
查询插入平衡
测试参数
总记录数为10亿,分为128个region,均匀分布在4台region server上;查询插入操作共执行8千万次;查询请求分布遵从zipfian分布;
测试结果

资源使用情况


图11为线程数在1000时系统IO利用率曲线图,图中IO利用率基本保持在100%,说明IO资源已经达到使用上限。图12为线程数在1000时系统负载曲线图,图中显示CPU负载资源达到了40+,对于只有32核的系统来说,已经远远超负荷工作了。
结果分析
1. 吞吐量曲线分析:线程数在10~500的情况下,随着线程数的增加,系统吞吐量会不断升高;之后线程数再增加,系统吞吐量变化就比较缓慢。结合图11、图12系统资源使用曲线图可以看出,当线程数增加到一定程度,系统IO资源基本达到上限,带宽也基本达到上限。IO利用率达到100%是因为大量的读操作都需要从磁盘查找数据,而系统负载很高是因为大量读取操作需要进行解压缩操作,而且线程数很大本身就需要更多CPU资源。因此导致系统吞吐量就不再会增加。可见,查询插入平衡场景下,当IO或者CPU资源bound后,系统吞吐量基本就会稳定不变。
2. 延迟曲线分析:随着线程数的不断增加,读取延迟也会不断增大。这是因为读取线程过多,导致CPU资源调度频繁,单个线程分配到的CPU资源会不断降低;另一方面由于线程之间可能会存在互斥操作导致线程阻塞;这些因素都会导致写入延迟不断增大。图中读延迟大于写延迟是因为读取操作涉及到IO操作,比较耗时。
建议
根据图表显示,在查询插入平衡场景下用户可以根据业务实际情况选择100~500之间的线程数。
插入为主
测试参数
总记录数为10亿,分为128个region,均匀分布在4台region server上;查询插入操作共执行4千万次;查询请求分布遵从latest分布;
测试结果
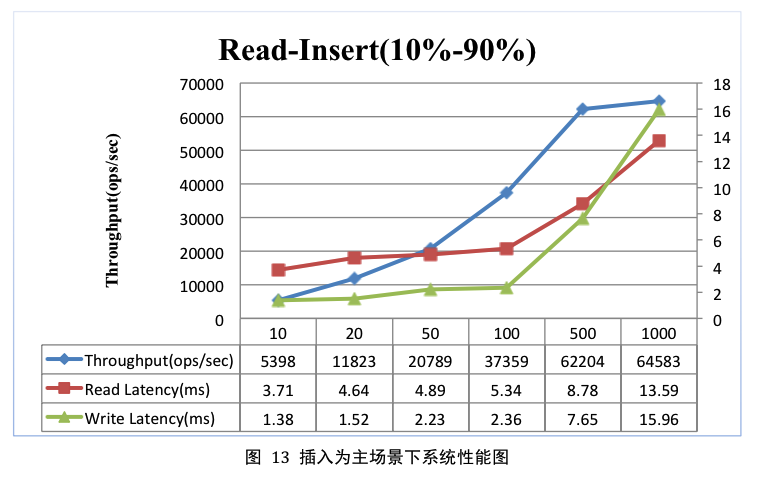
资源使用情况


图15为线程数在1000时系统带宽使用曲线图,图中系统带宽资源基本到达上限,而总体IO利用率还比较低。
结果分析
1. 曲线分析:线程数在10~500的情况下,随着线程数的增加,系统吞吐量会不断升高;之后线程数再增加,系统吞吐量基本上不再变化。结合图14带宽资源使用曲线图可以看出,当线程数增加到一定程度,系统带宽资源基本耗尽,系统吞吐量就不再会增加。基本同单条记录插入场景相同。
2. 写入延迟曲线分析: 基本同单条记录插入场景。
建议
根据图表显示,插入为主的场景下用户可以根据业务实际情况选择500左右的线程数来执行。
查询为主
测试参数
总记录数为10亿,分为128个region,均匀分布在4台region server上;查询插入操作共执行4千万次;查询请求分布遵从zipfian分布;
测试结果
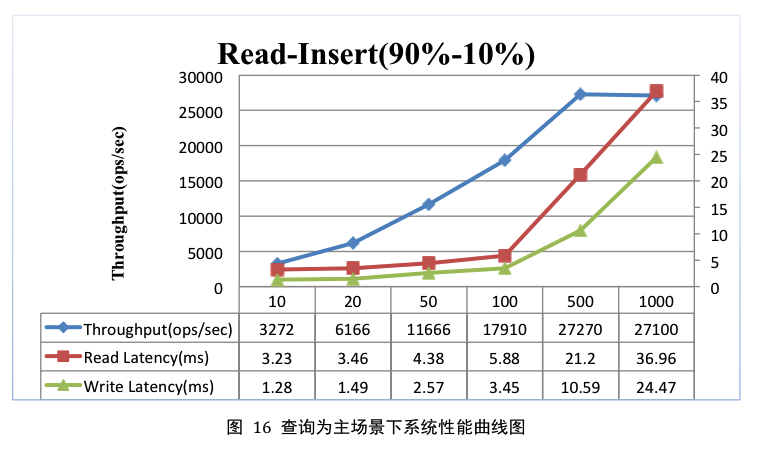
资源使用情况

图17为线程数在1000时IO利用率曲线图,图中IO利用率基本保持在100%,说明IO资源已经达到使用上限。
结果分析
基本分析见单纯查询一节,原理类似。
建议
根据图表显示,查询为主的场景下用户可以根据业务实际情况选择100~500之间的线程数来执行。
Increment自增
测试参数
1亿条数据,分成16个Region,分布在4台RegionServer上;操作次数为100万次;
测试结果
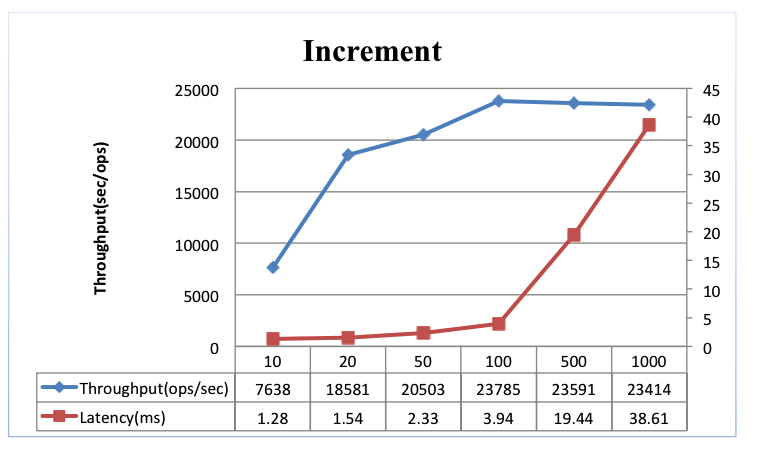
结果分析