
首先在豆瓣中找到自己想要分析的电影,这里猪哥选择一部美国电影《荒野生存》,因为这部电影是猪哥心中之最,没有之一!
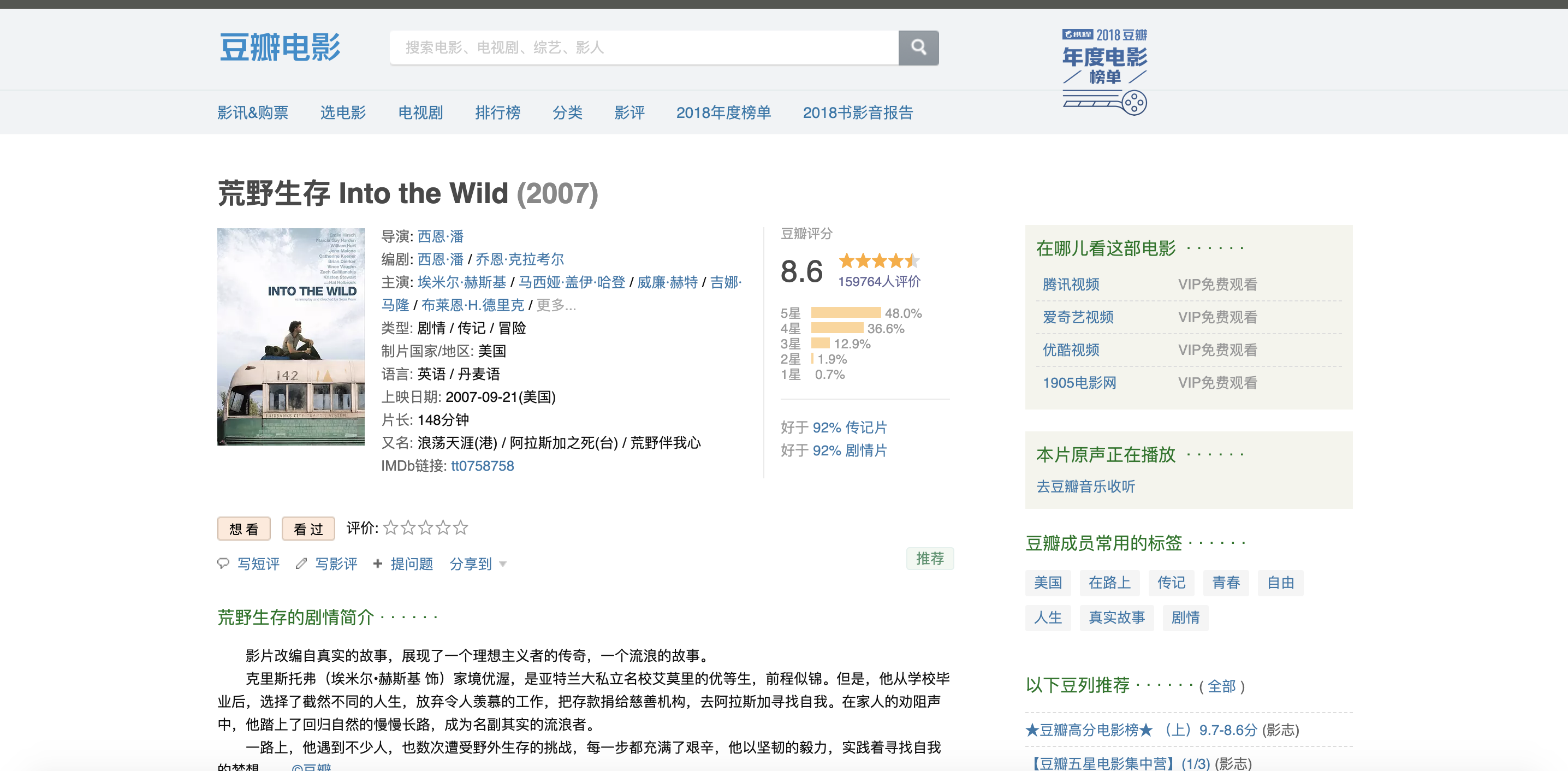
然后下拉找到影评,调出调试窗口,找到加载影评的URL
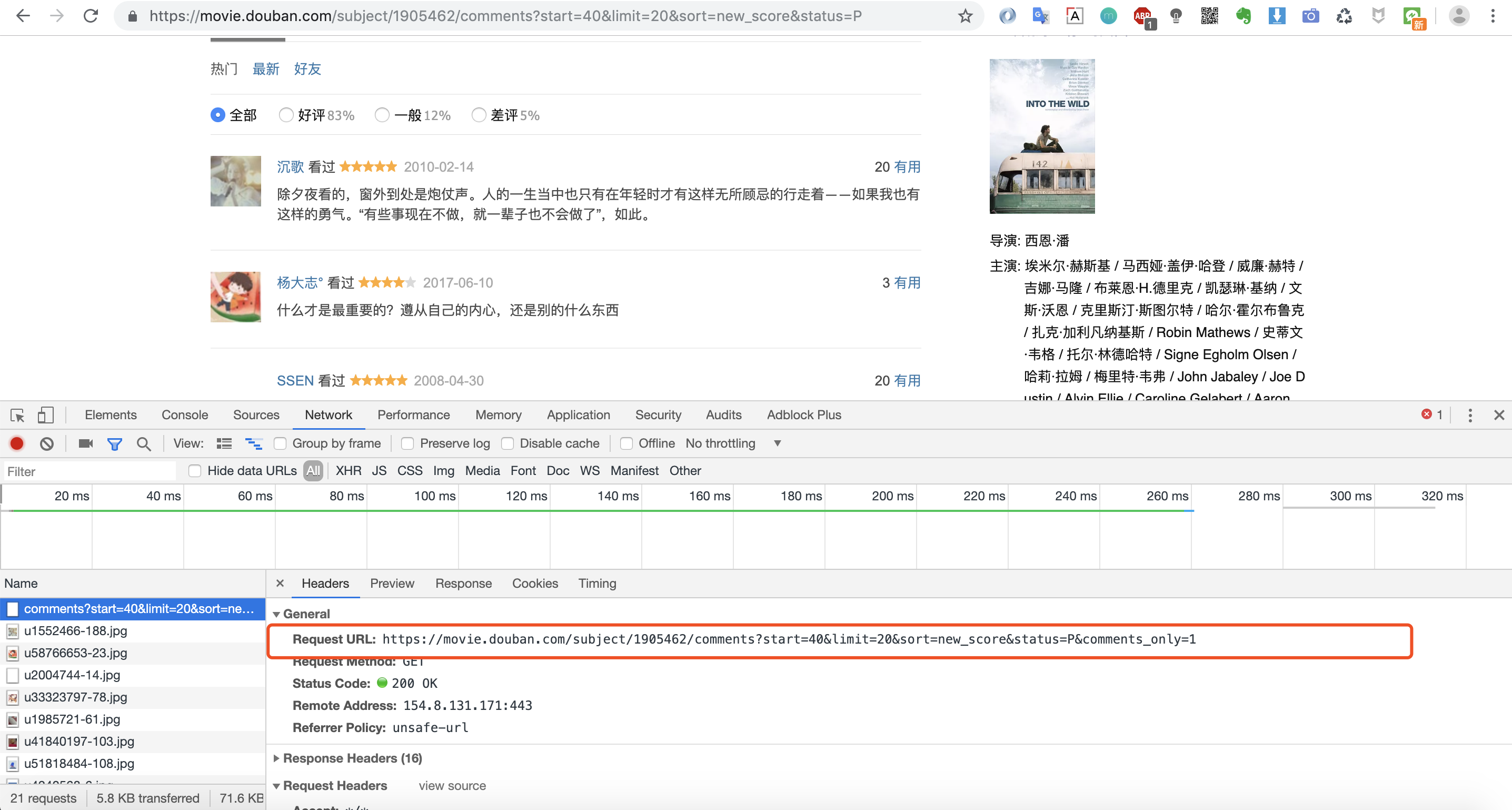
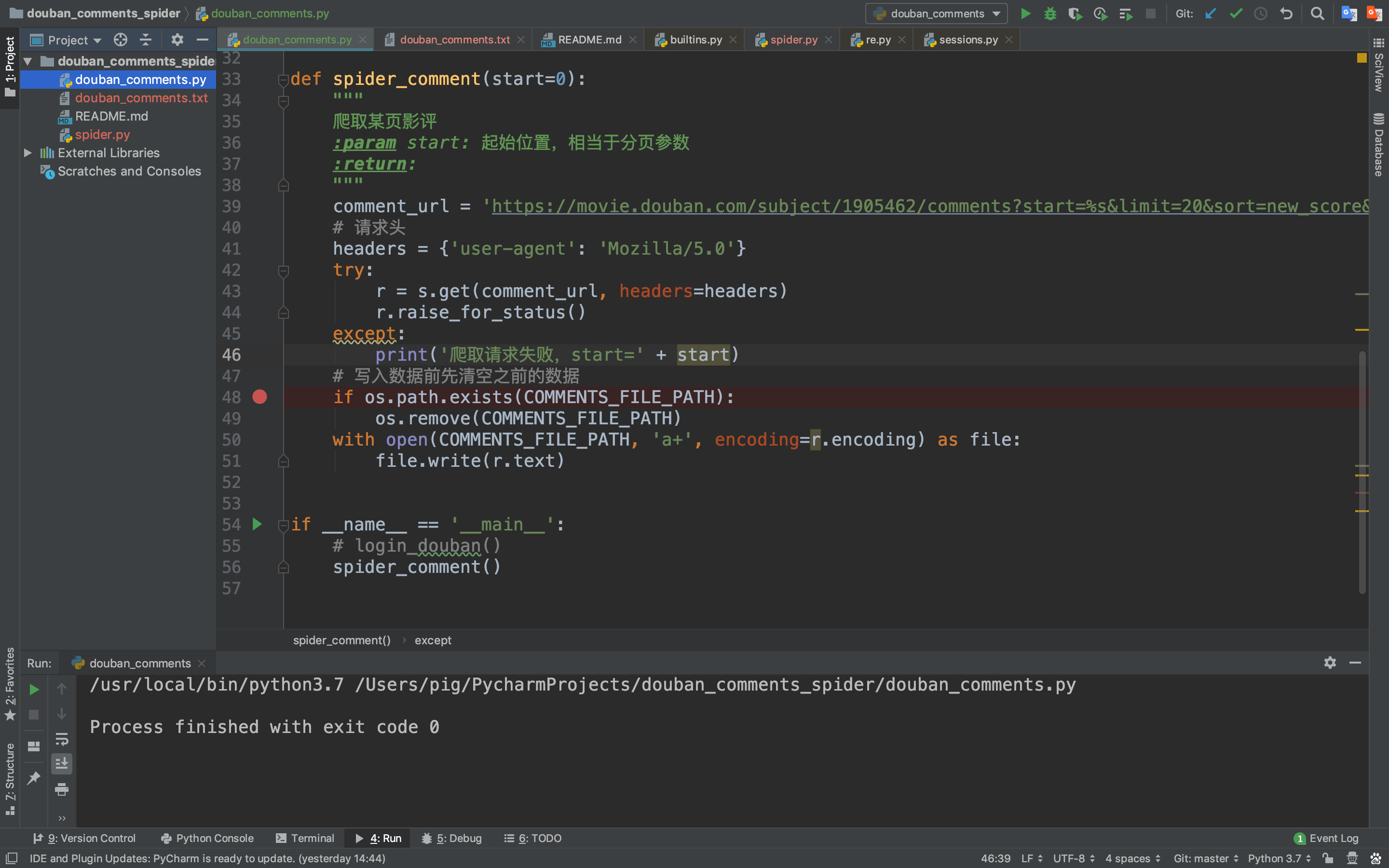
但是爬取下来的是一个HTML网页数据,我们需要将影评数据提取出来
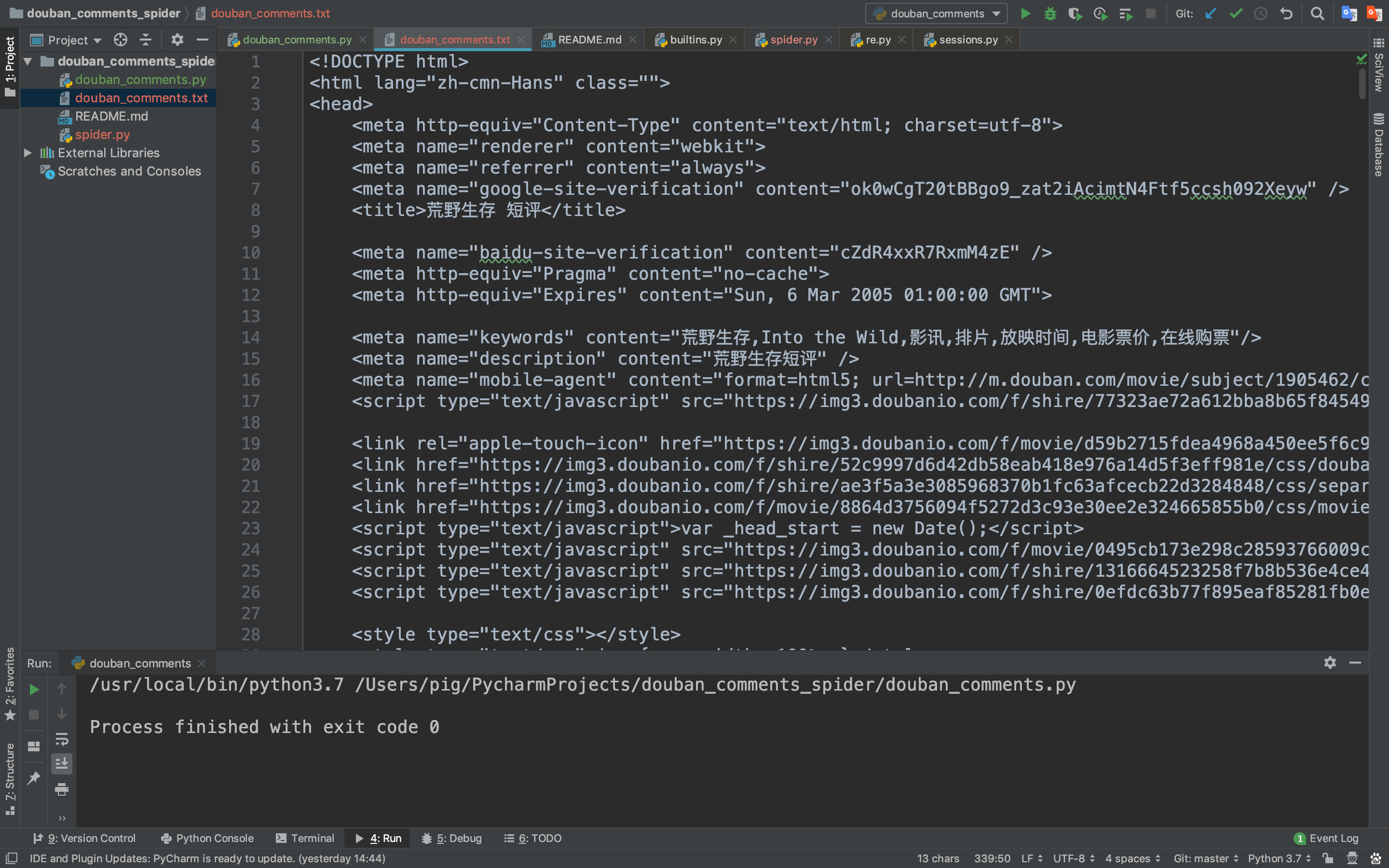
上图中我们可以看到爬取返回的是html,而影评数据便是嵌套在html标签中,如何提取影评内容呢?
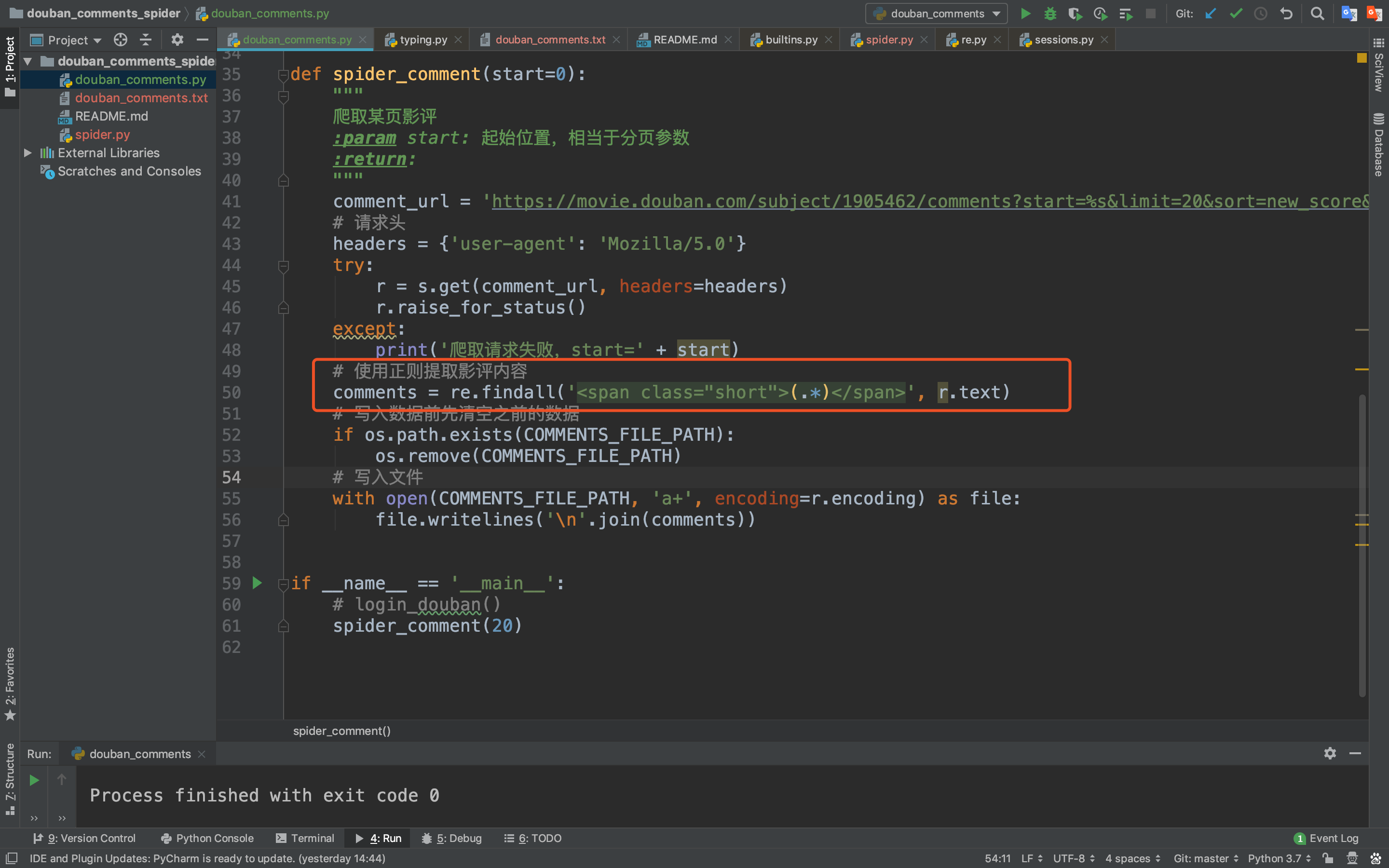
这里我们使用正则表达式来匹配想要的标签内容,当然也有更高级的提取方法,比如使用某些库(比如bs4、xpath等)去解析html提取内容,而且使用库效率也比较高,但这是我们后面的内容,我们今天就用正则来匹配!
我们先来分析下返回html 的网页结构
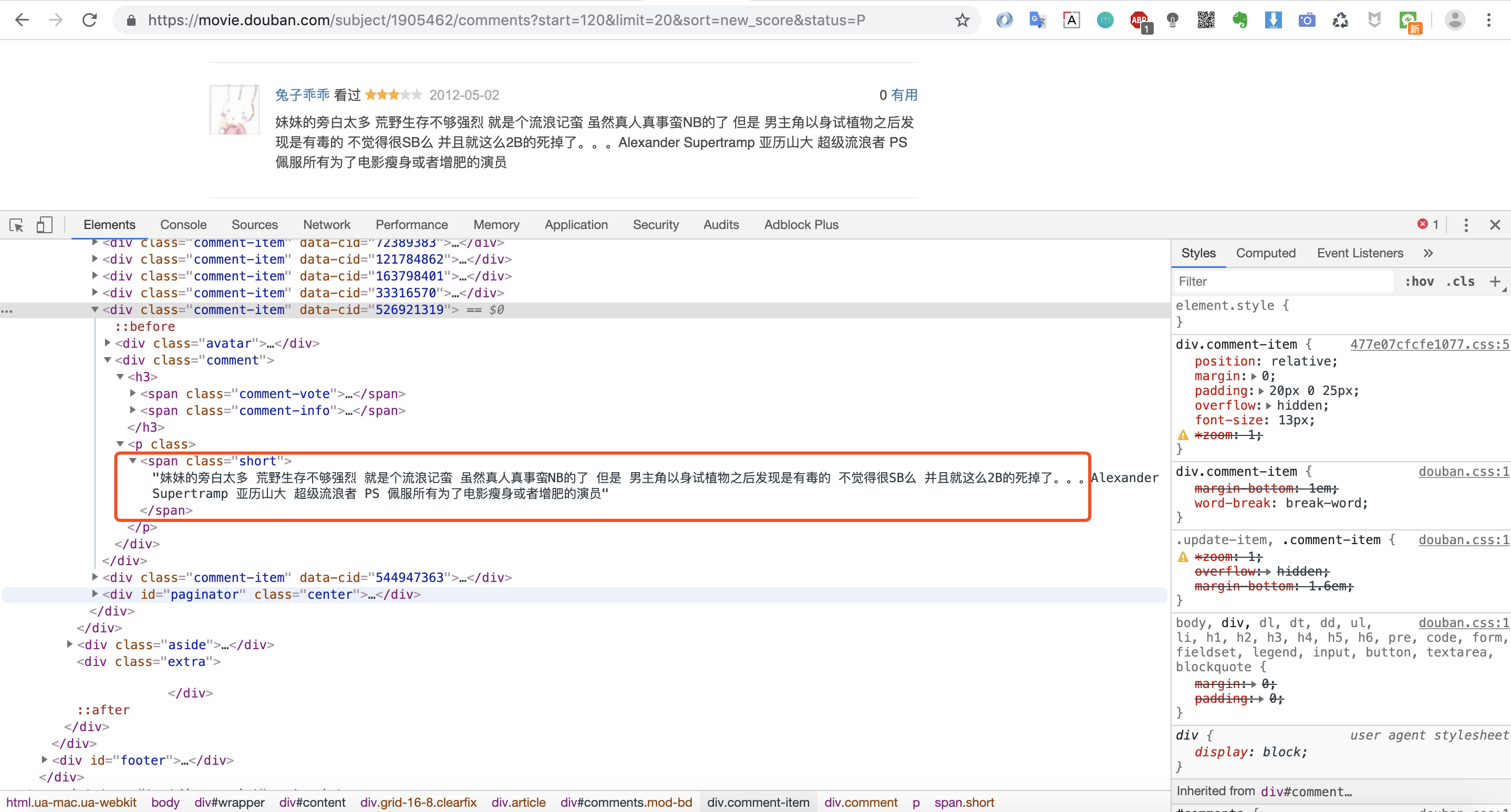
我们发现影评内容都是在<span></span>这个标签里,那我们 就可以写正则来匹配这个标签里的内容啦!
检查下提取的内容
我们爬取、提取、保存完一条数据之后,我们来批量爬取一下。根据前面几次爬取的经验,我们知道批量爬取的关键在于找到分页参数,我们可以很快发现URL中有一个start参数便是控制分页的参数。

这里只爬取了25页就爬完,我们可以去浏览器中验证一下,是不是真的只有25页,猪哥验证过确实只有25页! 六、分析影评
数据抓取下来之后,我们就来使用词云分析一下这部电影吧!
基于使用词云分析的案例前面已经讲过两个了,所以猪哥只会简单的讲解一下!
1.使用结巴分词因为我们下载的影评是一段一段的文字,而我们做的词云是统计单词出现的次数,所以需要先分词!
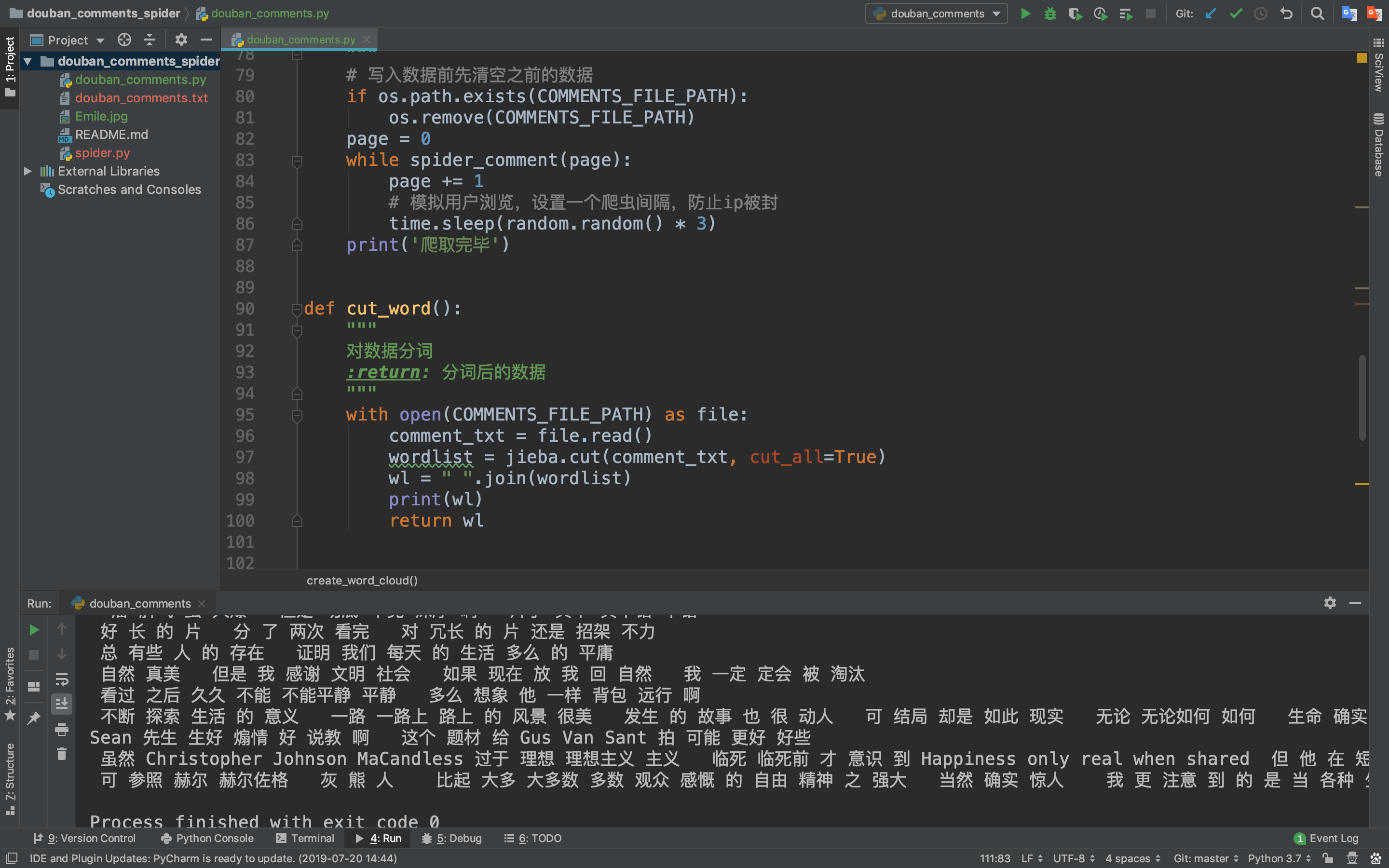
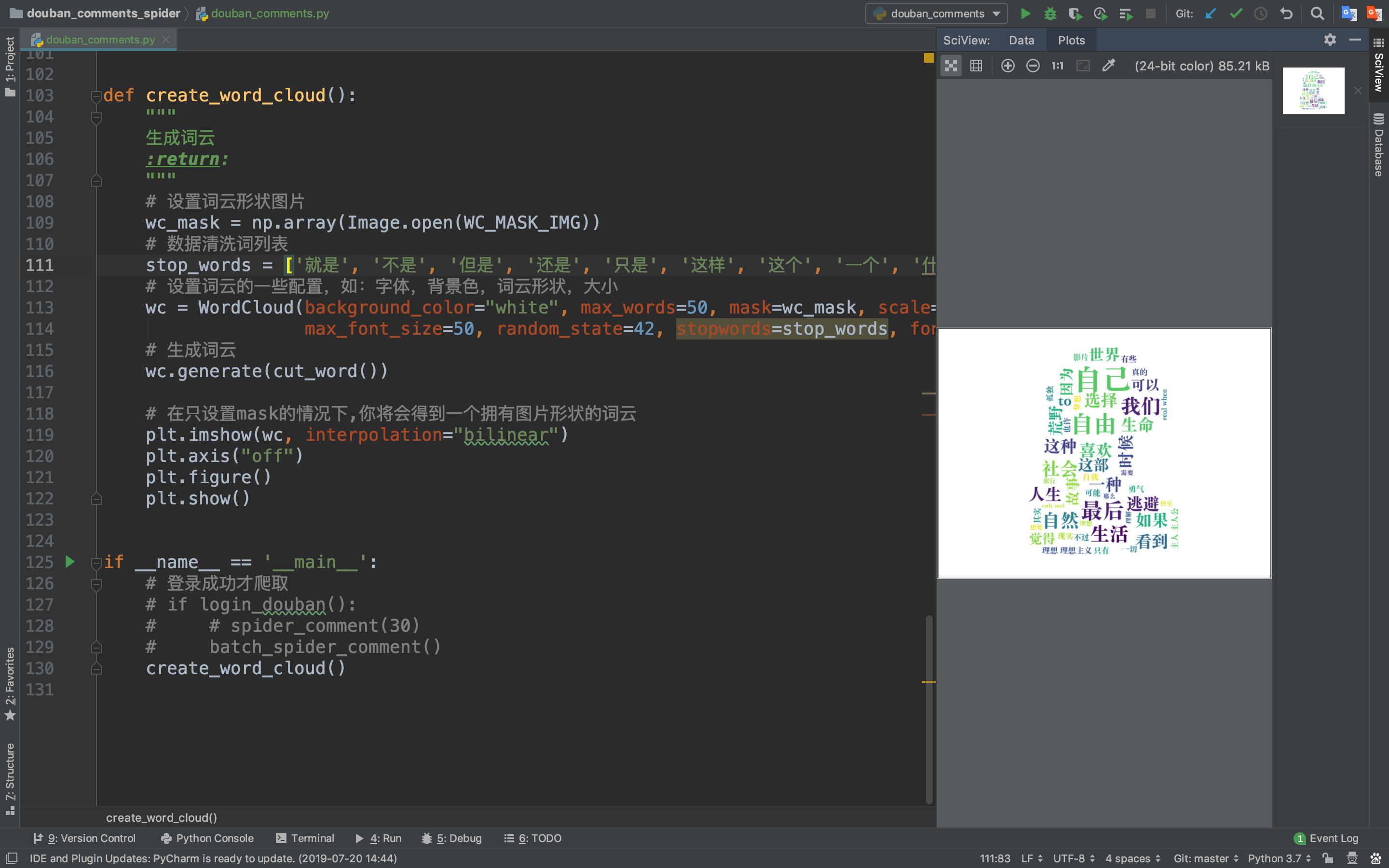
最终成果:

从这些词中我们可以知道这是关于一部关于追寻自我与现实生活的电影,猪哥裂墙推荐!!! 七、总结
今天我们以爬取豆瓣为例子,学到了不少的东西,来总结一下:
学习如何使用requests库发起POST请求
学习了如何使用requests库登录网站
学习了如何使用requests库的Session对象保持会话状态
学习了如何使用正则表达式提取网页标签中的内容
鉴于篇幅有限,爬虫过程中遇到的很多细节和技巧并没有完全写出来,所以希望大家能自己动手实践,当然也可以加入到猪哥的Python新手交流群中和大家一起学习,遇到问题也可以在群里提问!加群请加猪哥微信:it-pig66,好友申请格式:加群-xxx!
源码地址:https://github.com/pig6/douban_comments_spider