
从整体长度和头长度我们就能知道这个请求到底有多少位,前面多少位是头,剩下的都是协议体,这样就能识别出来,扩展位就是留着日后扩展备用。
贴一下 Dubbo 协议:

可以看到有 Magic 位,请求 ID, 数据长度等等。
网络传输组装好数据就等着发送了,这时候就涉及网络传输了。
网络通信那就离不开网络 IO 模型了。
网络 IO 分为这四种模型,具体以后单独写文章分析,这篇就不展开了。
一般而言我们用的都是 IO 多路复用,因为大部分 RPC 调用场景都是高并发调用,IO 复用可以利用较少的线程 hold 住很多请求。
一般 RPC 框架会使用已经造好的轮子来作为底层通信框架。
例如 Java 语言的都会用 Netty ,人家已经封装的很好了,也做了很多优化,拿来即用,便捷高效。
小结RPC 通信的基础流程已经讲完了,看下图:
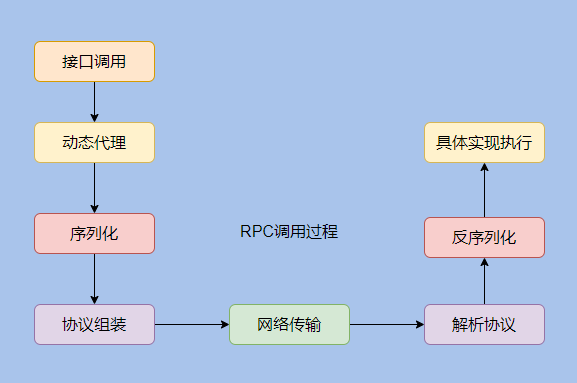
响应返回就没画了,反正就是倒着来。
我再用一段话来总结一下:
服务调用方,面向接口编程,利用动态代理屏蔽底层调用细节将请求参数、接口等数据组合起来并通过序列化转化为二进制数据,再通过 RPC 协议的封装利用网络传输到服务提供方。
服务提供方根据约定的协议解析出请求数据,然后反序列化得到参数,找到具体调用的接口,然后执行具体实现,再返回结果。
这里面还有很多细节。
比如请求都是异步的,所以每个请求会有唯一 ID,返回结果会带上对应的 ID, 这样调用方就能通过 ID 找到对应的请求塞入相应的结果。
有人会问为什么要异步,那是为了提高吞吐。
当然还有很多细节,会在之后剖析 Dubbo 的时候提到,结合实际中间件体会才会更深。
真正工业级别的 RPC以上提到的只是 RPC 的基础流程,这对于工业级别的使用是远远不够的。
生产环境中的服务提供者都是集群部署的,所以有多个提供者,而且还会随着大促等流量情况动态增减机器。
因此需要注册中心,作为服务的发现。
调用者可以通过注册中心得知服务提供者们的 IP 地址等元信息,进行调用。
调用者也能通过注册中心得知服务提供者下线。
还需要有路由分组策略,调用者根据下发的路由信息选择对应的服务提供者,能实现分组调用、灰度发布、流量隔离等功能。
还需要有负载均衡策略,一般经过路由过滤之后还是有多个服务提供者可以选择,通过负载均衡策略来达到流量均衡。
当然还需要有异常重试,毕竟网络是不稳定的,而且有时候某个服务提供者也可能出点问题,所以一次调用出错进行重试,较少业务的损耗。