ORC 是一种自描述的、类型感知的列文件格式,它针对大型数据的读写进行了优化,也是大数据中常用的文件格式。
5.1 读取ORC文件 spark.read.format("orc").load("/usr/file/orc/dept.orc").show(5) 4.2 写入ORC文件 csvFile.write.format("orc").mode("overwrite").save("/tmp/spark/orc/dept")Spark 同样支持与传统的关系型数据库进行数据读写。但是 Spark 程序默认是没有提供数据库驱动的,所以在使用前需要将对应的数据库驱动上传到安装目录下的 jars 目录中。下面示例使用的是 Mysql 数据库,使用前需要将对应的 mysql-connector-java-x.x.x.jar 上传到 jars 目录下。
6.1 读取数据读取全表数据示例如下,这里的 help_keyword 是 mysql 内置的字典表,只有 help_keyword_id 和 name 两个字段。
spark.read .format("jdbc") .option("driver", "com.mysql.jdbc.Driver") //驱动 .option("url", "jdbc:mysql://127.0.0.1:3306/mysql") //数据库地址 .option("dbtable", "help_keyword") //表名 .option("user", "root").option("password","root").load().show(10)从查询结果读取数据:
val pushDownQuery = """(SELECT * FROM help_keyword WHERE help_keyword_id <20) AS help_keywords""" spark.read.format("jdbc") .option("url", "jdbc:mysql://127.0.0.1:3306/mysql") .option("driver", "com.mysql.jdbc.Driver") .option("user", "root").option("password", "root") .option("dbtable", pushDownQuery) .load().show() //输出 +---------------+-----------+ |help_keyword_id| name| +---------------+-----------+ | 0| <>| | 1| ACTION| | 2| ADD| | 3|AES_DECRYPT| | 4|AES_ENCRYPT| | 5| AFTER| | 6| AGAINST| | 7| AGGREGATE| | 8| ALGORITHM| | 9| ALL| | 10| ALTER| | 11| ANALYSE| | 12| ANALYZE| | 13| AND| | 14| ARCHIVE| | 15| AREA| | 16| AS| | 17| ASBINARY| | 18| ASC| | 19| ASTEXT| +---------------+-----------+也可以使用如下的写法进行数据的过滤:
val props = new java.util.Properties props.setProperty("driver", "com.mysql.jdbc.Driver") props.setProperty("user", "root") props.setProperty("password", "root") val predicates = Array("help_keyword_id < 10 OR name = 'WHEN'") //指定数据过滤条件 spark.read.jdbc("jdbc:mysql://127.0.0.1:3306/mysql", "help_keyword", predicates, props).show() //输出: +---------------+-----------+ |help_keyword_id| name| +---------------+-----------+ | 0| <>| | 1| ACTION| | 2| ADD| | 3|AES_DECRYPT| | 4|AES_ENCRYPT| | 5| AFTER| | 6| AGAINST| | 7| AGGREGATE| | 8| ALGORITHM| | 9| ALL| | 604| WHEN| +---------------+-----------+可以使用 numPartitions 指定读取数据的并行度:
option("numPartitions", 10)在这里,除了可以指定分区外,还可以设置上界和下界,任何小于下界的值都会被分配在第一个分区中,任何大于上界的值都会被分配在最后一个分区中。
val colName = "help_keyword_id" //用于判断上下界的列 val lowerBound = 300L //下界 val upperBound = 500L //上界 val numPartitions = 10 //分区综述 val jdbcDf = spark.read.jdbc("jdbc:mysql://127.0.0.1:3306/mysql","help_keyword", colName,lowerBound,upperBound,numPartitions,props)想要验证分区内容,可以使用 mapPartitionsWithIndex 这个算子,代码如下:
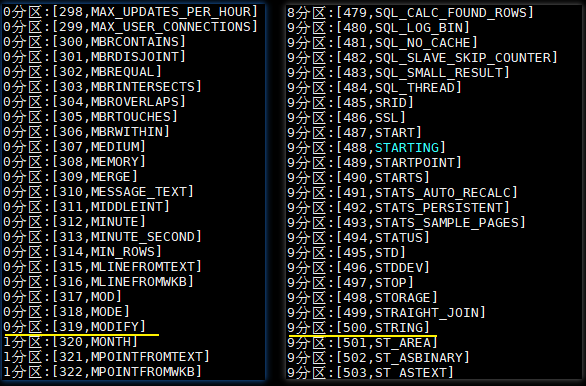
jdbcDf.rdd.mapPartitionsWithIndex((index, iterator) => { val buffer = new ListBuffer[String] while (iterator.hasNext) { buffer.append(index + "分区:" + iterator.next()) } buffer.toIterator }).foreach(println)执行结果如下:help_keyword 这张表只有 600 条左右的数据,本来数据应该均匀分布在 10 个分区,但是 0 分区里面却有 319 条数据,这是因为设置了下限,所有小于 300 的数据都会被限制在第一个分区,即 0 分区。同理所有大于 500 的数据被分配在 9 分区,即最后一个分区。